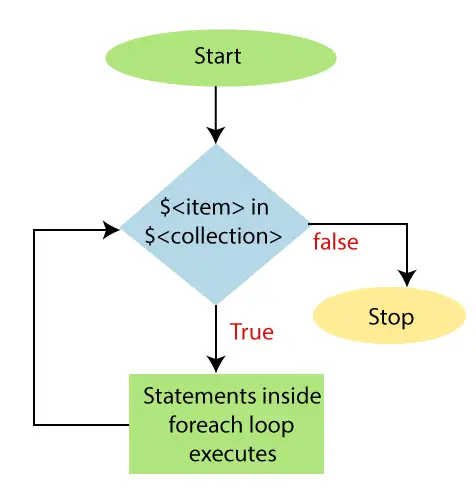
Étant donné un nombre « n » et un n nombres, triez les nombres à l’aide du tri par fusion simultanée. (Indice : essayez d'utiliser les appels système shmget, shmat).Partie 1 : L'algorithme (COMMENT ?) Créez de manière récursive deux processus enfants, un pour la moitié gauche, un pour la moitié droite. Si le nombre d'éléments dans le tableau d'un processus est inférieur à 5, effectuez un tri par insertion. Le parent des deux enfants fusionne ensuite le résultat et revient au parent et ainsi de suite. Mais comment le rendre concurrent ?Partie 2 : La logique (POURQUOI ?) La partie importante de la solution à ce problème n'est pas algorithmique, mais consiste à expliquer les concepts de système d'exploitation et de noyau. Pour réaliser un tri simultané, nous avons besoin d’un moyen de faire fonctionner deux processus sur le même tableau en même temps. Pour faciliter les choses, Linux fournit de nombreux appels système via de simples points de terminaison API. Deux d'entre eux sont shmget() (pour l'allocation de mémoire partagée) et shmat() (pour les opérations de mémoire partagée). Nous créons un espace mémoire partagé entre le processus enfant que nous bifurquons. Chaque segment est divisé en enfants gauche et droit qui sont triés, la partie intéressante étant qu'ils travaillent simultanément ! shmget() demande au noyau d'attribuer une page partagée pour les deux processus. Pourquoi le fork() traditionnel ne fonctionne pas ? La réponse réside dans ce que fait réellement fork(). D'après la documentation, « fork() crée un nouveau processus en dupliquant le processus appelant ». Le processus enfant et le processus parent s'exécutent dans des espaces mémoire distincts. Au moment de fork(), les deux espaces mémoire ont le même contenu. Les écritures en mémoire, les modifications du descripteur de fichier (fd), etc., effectuées par l'un des processus n'affectent pas l'autre. Nous avons donc besoin d'un segment de mémoire partagée.