Analyse XML en Python

Cet article se concentre sur la façon dont on peut analyser un fichier XML donné et en extraire des données utiles de manière structurée. XML : XML signifie eXtensible Markup Language. Il a été conçu pour stocker et transporter des données. Il a été conçu pour être lisible à la fois par l'homme et par la machine. C'est pourquoi les objectifs de conception de XML mettent l'accent sur la simplicité, la généralité et la convivialité sur Internet. Le fichier XML à analyser dans ce didacticiel est en réalité un flux RSS. RSS : RSS (Rich Site Summary, souvent appelé Really Simple Syndication) utilise une famille de formats de flux Web standard pour publier des informations fréquemment mises à jour, telles que des entrées de blog, des titres d'actualités, des vidéos audio. RSS est du texte brut au format XML.
- Le format RSS lui-même est relativement facile à lire tant par les processus automatisés que par les humains.
- Le flux RSS traité dans ce didacticiel est le flux RSS des principales actualités d'un site Web d'actualités populaire. Vous pouvez le vérifier ici . Notre objectif est de traiter ce flux RSS (ou fichier XML) et de l'enregistrer dans un autre format pour une utilisation ultérieure.
#Python code to illustrate parsing of XML files # importing the required modules import csv import requests import xml.etree.ElementTree as ET def loadRSS (): # url of rss feed url = 'http://www.hindustantimes.com/rss/topnews/rssfeed.xml' # creating HTTP response object from given url resp = requests . get ( url ) # saving the xml file with open ( 'topnewsfeed.xml' 'wb' ) as f : f . write ( resp . content ) def parseXML ( xmlfile ): # create element tree object tree = ET . parse ( xmlfile ) # get root element root = tree . getroot () # create empty list for news items newsitems = [] # iterate news items for item in root . findall ( './channel/item' ): # empty news dictionary news = {} # iterate child elements of item for child in item : # special checking for namespace object content:media if child . tag == '{https://video.search.yahoo.com/mrss' : news [ 'media' ] = child . attrib [ 'url' ] else : news [ child . tag ] = child . text . encode ( 'utf8' ) # append news dictionary to news items list newsitems . append ( news ) # return news items list return newsitems def savetoCSV ( newsitems filename ): # specifying the fields for csv file fields = [ 'guid' 'title' 'pubDate' 'description' 'link' 'media' ] # writing to csv file with open ( filename 'w' ) as csvfile : # creating a csv dict writer object writer = csv . DictWriter ( csvfile fieldnames = fields ) # writing headers (field names) writer . writeheader () # writing data rows writer . writerows ( newsitems ) def main (): # load rss from web to update existing xml file loadRSS () # parse xml file newsitems = parseXML ( 'topnewsfeed.xml' ) # store news items in a csv file savetoCSV ( newsitems 'topnews.csv' ) if __name__ == '__main__' : # calling main function main ()
Above code will: - Chargez le flux RSS à partir de l'URL spécifiée et enregistrez-le sous forme de fichier XML.
- Analysez le fichier XML pour enregistrer les actualités sous forme de liste de dictionnaires où chaque dictionnaire est un élément d'actualité unique.
- Enregistrez les actualités dans un fichier CSV.
- Vous pouvez consulter davantage de flux RSS du site Web d’actualités utilisé dans l’exemple ci-dessus. Vous pouvez essayer de créer une version étendue de l'exemple ci-dessus en analysant également d'autres flux RSS.
- Êtes-vous un fan de cricket? Alors ce le flux rss doit vous intéresser ! Vous pouvez analyser ce fichier XML pour récupérer des informations sur les matchs de cricket en direct et l'utiliser pour créer un notificateur de bureau !
def loadRSS(): # url of rss feed url = 'http://www.hindustantimes.com/rss/topnews/rssfeed.xml' # creating HTTP response object from given url resp = requests.get(url) # saving the xml file with open('topnewsfeed.xml' 'wb') as f: f.write(resp.content) Here we first created a HTTP response object by sending an HTTP request to the URL of the RSS feed. The content of response now contains the XML file data which we save as topnewsfeed.xml dans notre annuaire local. Pour plus d'informations sur le fonctionnement du module de requêtes, suivez cet article : Requêtes GET et POST utilisant Python  Ici, nous utilisons xml.etree.ElementTree (appelez-le ET en bref) module. Element Tree a deux classes à cet effet - ArbreÉlément représente l'ensemble du document XML sous forme d'arborescence et Élément représente un seul nœud dans cet arbre. Les interactions avec l'ensemble du document (lecture et écriture vers/depuis des fichiers) se font généralement sur le ArbreÉlément niveau. Les interactions avec un seul élément XML et ses sous-éléments se font sur le Élément niveau. Ok, passons en revue analyserXML() function now:
Ici, nous utilisons xml.etree.ElementTree (appelez-le ET en bref) module. Element Tree a deux classes à cet effet - ArbreÉlément représente l'ensemble du document XML sous forme d'arborescence et Élément représente un seul nœud dans cet arbre. Les interactions avec l'ensemble du document (lecture et écriture vers/depuis des fichiers) se font généralement sur le ArbreÉlément niveau. Les interactions avec un seul élément XML et ses sous-éléments se font sur le Élément niveau. Ok, passons en revue analyserXML() function now: tree = ET.parse(xmlfile)Here we create an ArbreÉlément objet en analysant le passé fichier xml.
root = tree.getroot()être enraciné() la fonction renvoie la racine de arbre comme un Élément object.
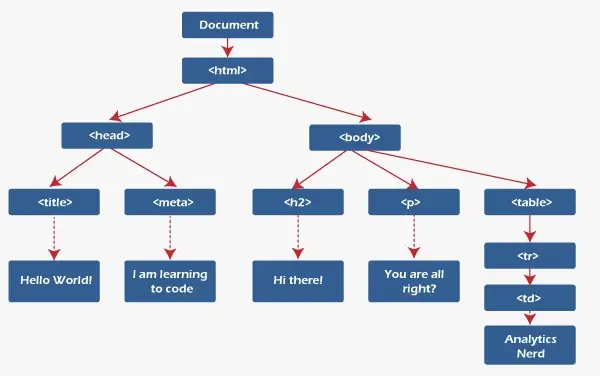
for item in root.findall('./channel/item'): Now once you have taken a look at the structure of your XML file you will notice that we are interested only in article élément. ./canal/article est en fait XPath syntaxe (XPath est un langage permettant d'adresser des parties d'un document XML). Ici, nous voulons tout trouver article petits-enfants de canal les enfants du racine (noté par '.') élément. Vous pouvez en savoir plus sur la syntaxe XPath prise en charge ici . for item in root.findall('./channel/item'): # empty news dictionary news = {} # iterate child elements of item for child in item: # special checking for namespace object content:media if child.tag == '{https://video.search.yahoo.com/mrss': news['media'] = child.attrib['url'] else: news[child.tag] = child.text.encode('utf8') # append news dictionary to news items list newsitems.append(news) Now we know that we are iterating through article éléments où chacun article L'élément contient une nouvelle. Nous créons donc un vide nouvelles dictionary in which we will store all data available about news item. To iterate though each child element of an element we simply iterate through it like this: for child in item:Now notice a sample item element here:
 We will have to handle namespace tags separately as they get expanded to their original value when parsed. So we do something like this:
We will have to handle namespace tags separately as they get expanded to their original value when parsed. So we do something like this: if child.tag == '{https://video.search.yahoo.com/mrss': news['media'] = child.attrib['url'] enfant.attrib est un dictionnaire de tous les attributs liés à un élément. Nous nous intéressons ici URL attribut de média:contenu namespace tag. Now for all other children we simply do: news[child.tag] = child.text.encode('utf8') enfant.tag contient le nom de l'élément enfant. enfant.texte stores all the text inside that child element. So finally a sample item element is converted to a dictionary and looks like this: {'description': 'Ignis has a tough competition already from Hyun.... 'guid': 'http://www.hindustantimes.com/autos/maruti-ignis-launch.... 'link': 'http://www.hindustantimes.com/autos/maruti-ignis-launch.... 'media': 'http://www.hindustantimes.com/rf/image_size_630x354/HT/... 'pubDate': 'Thu 12 Jan 2017 12:33:04 GMT ' 'title': 'Maruti Ignis launches on Jan 13: Five cars that threa..... } Then we simply append this dict element to the list articles d'actualité . Finalement, cette liste est renvoyée.  Comme vous pouvez le constater, les données du fichier XML hiérarchique ont été converties en un simple fichier CSV afin que toutes les actualités soient stockées sous la forme d'un tableau. Cela facilite également l'extension de la base de données. On peut également utiliser les données de type JSON directement dans leurs applications ! C'est la meilleure alternative pour extraire des données de sites Web qui ne fournissent pas d'API publique mais fournissent des flux RSS. Tout le code et les fichiers utilisés dans l'article ci-dessus peuvent être trouvés ici . Et ensuite ?
Comme vous pouvez le constater, les données du fichier XML hiérarchique ont été converties en un simple fichier CSV afin que toutes les actualités soient stockées sous la forme d'un tableau. Cela facilite également l'extension de la base de données. On peut également utiliser les données de type JSON directement dans leurs applications ! C'est la meilleure alternative pour extraire des données de sites Web qui ne fournissent pas d'API publique mais fournissent des flux RSS. Tout le code et les fichiers utilisés dans l'article ci-dessus peuvent être trouvés ici . Et ensuite ? Vous Pourriez Aimer
Top Articles





Catégorie
Des Articles Intéressants