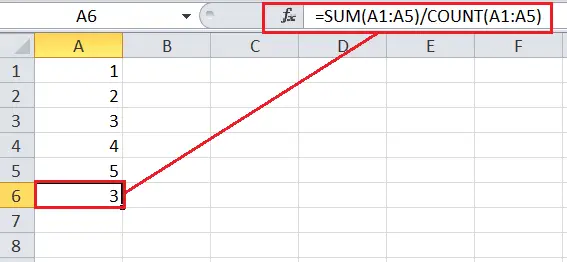
Метод Pandas DataFrame corr().

панди dataframe.corr() використовується для пошуку попарної кореляції всіх стовпців у Pandas Dataframe у Python. Будь-який NaN значення автоматично виключаються. Щоб ігнорувати будь-які нечислові значення, використовуйте параметр numeric_only = True. У цій статті ми дізнаємося про метод DataFrame.corr(). Python .
Синтаксис методу Pandas DataFrame corr().
Синтаксис: DataFrame.corr(self, method=’pearson’, min_periods=1, numeric_only = False)
Параметри:
- метод:
- Пірсона: стандартний коефіцієнт кореляції
- kendall: коефіцієнт кореляції Kendall Tau
- списоносець: кореляція рангу списоносця
- min_periods : Мінімальна кількість спостережень, необхідних для кожної пари стовпців, щоб отримати дійсний результат. Наразі доступно лише для кореляції Пірсона та Спірмена
- numeric_only : чи потрібно оперувати лише числовими значеннями. За замовчуванням встановлено значення False.
Повернення: count :y : DataFrame
Метод кореляції даних Pandas corr().
Хороша кореляція залежить від використання, але можна з упевненістю сказати, що у вас є принаймні 0,6 (або -0,6), щоб назвати це хорошою кореляцією. Простий приклад, щоб показати, як працює кореляція Python .
Python3
import> pandas as pd> df> => {> > 'Array_1'> : [> 30> ,> 70> ,> 100> ],> > 'Array_2'> : [> 65.1> ,> 49.50> ,> 30.7> ]> }> data> => pd.DataFrame(df)> print> (data.corr())> |
Вихід
Array_1 Array_2 Array_1 1.000000 -0.990773 Array_2 -0.990773 1.000000
Створення зразка кадру даних
Друк перших 10 рядків Dataframe.
Примітка: Кореляція змінної з самою собою дорівнює 1. Щоб отримати посилання на файл CSV, який використовується в коді, натисніть тут
Python3
# importing pandas as pd> import> pandas as pd> # Making data frame from the csv file> df> => pd.read_csv(> 'nba.csv'> )> # Printing the first 10 rows of the data frame for visualization> df[:> 10> ]> |
Вихід

Приклади методу Python Pandas DataFrame corr().
Знайдіть кореляцію між стовпцями за допомогою методу Пірсона
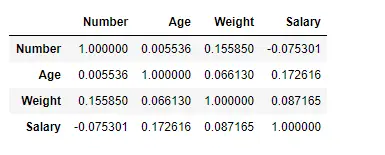
Тут ми використовуємо функцію corr(), щоб знайти кореляцію між стовпцями в Dataframe за допомогою методу Пірсона. Ми маємо лише чотири числових стовпці у Dataframe. Вихідний фрейм даних можна інтерпретувати як для будь-якої клітинки, кореляція змінної рядка зі змінною стовпця є значенням клітинки. Як згадувалося раніше, кореляція змінної з самою собою дорівнює 1. З цієї причини всі діагональні значення дорівнюють 1,00.
Python3
# To find the correlation among> # the columns using pearson method> df.corr(method> => 'pearson'> )> |
Вихід
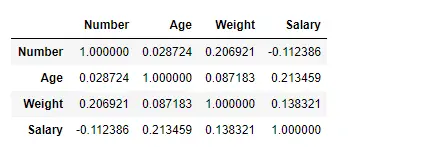
Знайдіть кореляцію між стовпчиками за допомогою методу Кендалла
Використовуйте функцію Pandas df.corr(), щоб знайти кореляцію між стовпцями в Dataframe за допомогою методу «kendall». Вихідний фрейм даних можна інтерпретувати як для будь-якої клітинки, кореляція змінної рядка зі змінною стовпця є значенням клітинки. Як згадувалося раніше, кореляція змінної з самою собою дорівнює 1. З цієї причини всі діагональні значення дорівнюють 1,00.
Python3
# importing pandas as pd> import> pandas as pd> # Making data frame from the csv file> df> => pd.read_csv(> 'nba.csv'> )> # To find the correlation among> # the columns using kendall method> df.corr(method> => 'kendall'> )> |
Вихід