Реалізація хеш-таблиці в Python за допомогою окремого ланцюжка
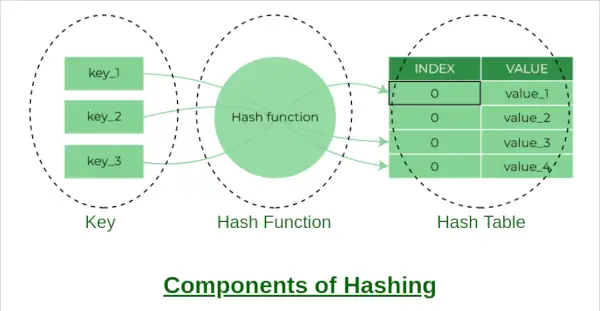
А хеш-таблиця це структура даних, яка дозволяє швидко вставляти, видаляти та отримувати дані. Він працює за допомогою хеш-функції для зіставлення ключа з індексом у масиві. У цій статті ми реалізуємо хеш-таблицю в Python за допомогою окремого ланцюжка для обробки колізій.

Компоненти хешування
Окреме з’єднання — це техніка, яка використовується для обробки колізій у хеш-таблиці. Коли два або більше ключів відображаються на один і той самий індекс у масиві, ми зберігаємо їх у зв’язаному списку за цим індексом. Це дозволяє нам зберігати кілька значень за одним індексом і мати можливість отримувати їх за допомогою їхнього ключа.
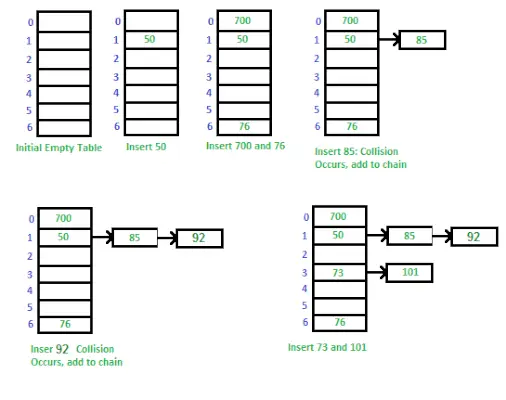
Спосіб реалізації хеш-таблиці за допомогою окремого ланцюжка
Спосіб реалізації хеш-таблиці за допомогою окремого ланцюжка:
Створіть два класи: ' Вузол 'і' HashTable '.
' Вузол ‘ клас представлятиме вузол у пов’язаному списку. Кожен вузол міститиме пару ключ-значення, а також вказівник на наступний вузол у списку.
Python3
class> Node:> > def> __init__(> self> , key, value):> > self> .key> => key> > self> .value> => value> > self> .> next> => None> |
Клас «HashTable» міститиме масив, який буде містити зв’язані списки, а також методи для вставки, отримання та видалення даних із хеш-таблиці.
Python3
class> HashTable:> > def> __init__(> self> , capacity):> > self> .capacity> => capacity> > self> .size> => 0> > self> .table> => [> None> ]> *> capacity> |
' __гарячий__ ‘ метод ініціалізує хеш-таблицю заданою ємністю. Він встановлює ' місткість 'і' розмір ‘ змінні та ініціалізує масив як «Немає».
Наступний метод - це ' _хеш 'метод. Цей метод приймає ключ і повертає індекс в масиві, де має зберігатися пара ключ-значення. Ми використаємо вбудовану хеш-функцію Python, щоб хешувати ключ, а потім використаємо оператор modulo, щоб отримати індекс у масиві.
Python3
def> _hash(> self> , key):> > return> hash> (key)> %> self> .capacity> |
The «вставити» метод вставить пару ключ-значення в хеш-таблицю. Він бере індекс, де має бути збережена пара, використовуючи « _хеш 'метод. Якщо в цьому індексі немає пов’язаного списку, він створює новий вузол із парою ключ-значення та встановлює його як голову списку. Якщо в цьому індексі є зв’язаний список, перебирайте список, доки не буде знайдено останній вузол або ключ уже існує, і оновіть значення, якщо ключ уже існує. Якщо він знаходить ключ, він оновлює значення. Якщо він не знаходить ключ, він створює новий вузол і додає його до початку списку.
Python3
def> insert(> self> , key, value):> > index> => self> ._hash(key)> > if> self> .table[index]> is> None> :> > self> .table[index]> => Node(key, value)> > self> .size> +> => 1> > else> :> > current> => self> .table[index]> > while> current:> > if> current.key> => => key:> > current.value> => value> > return> > current> => current.> next> > new_node> => Node(key, value)> > new_node.> next> => self> .table[index]> > self> .table[index]> => new_node> > self> .size> +> => 1> |
The пошук метод отримує значення, пов'язане з заданим ключем. Спочатку він отримує індекс, де має зберігатися пара ключ-значення за допомогою _хеш метод. Потім він шукає ключ у пов’язаному списку за цим індексом. Якщо він знаходить ключ, він повертає відповідне значення. Якщо він не знаходить ключ, він викликає a KeyError .
Python3
def> search(> self> , key):> > index> => self> ._hash(key)> > current> => self> .table[index]> > while> current:> > if> current.key> => => key:> > return> current.value> > current> => current.> next> > raise> KeyError(key)> |
The 'видалити' метод видаляє пару ключ-значення з хеш-таблиці. Спочатку він отримує індекс, де має бути збережена пара за допомогою ` _хеш ` метод. Потім він шукає ключ у пов’язаному списку за цим індексом. Якщо він знаходить ключ, він видаляє вузол зі списку. Якщо він не знаходить ключ, він викликає ` KeyError `.
Python3
def> remove(> self> , key):> > index> => self> ._hash(key)> > > previous> => None> > current> => self> .table[index]> > > while> current:> > if> current.key> => => key:> > if> previous:> > previous.> next> => current.> next> > else> :> > self> .table[index]> => current.> next> > self> .size> -> => 1> > return> > previous> => current> > current> => current.> next> > > raise> KeyError(key)> |
‘__str__’ метод, який повертає рядкове представлення хеш-таблиці.
Python3
def> __str__(> self> ):> > elements> => []> > for> i> in> range> (> self> .capacity):> > current> => self> .table[i]> > while> current:> > elements.append((current.key, current.value))> > current> => current.> next> > return> str> (elements)> |
Ось повна реалізація класу «HashTable»:
Python3
class> Node:> > def> __init__(> self> , key, value):> > self> .key> => key> > self> .value> => value> > self> .> next> => None> > > class> HashTable:> > def> __init__(> self> , capacity):> > self> .capacity> => capacity> > self> .size> => 0> > self> .table> => [> None> ]> *> capacity> > > def> _hash(> self> , key):> > return> hash> (key)> %> self> .capacity> > > def> insert(> self> , key, value):> > index> => self> ._hash(key)> > > if> self> .table[index]> is> None> :> > self> .table[index]> => Node(key, value)> > self> .size> +> => 1> > else> :> > current> => self> .table[index]> > while> current:> > if> current.key> => => key:> > current.value> => value> > return> > current> => current.> next> > new_node> => Node(key, value)> > new_node.> next> => self> .table[index]> > self> .table[index]> => new_node> > self> .size> +> => 1> > > def> search(> self> , key):> > index> => self> ._hash(key)> > > current> => self> .table[index]> > while> current:> > if> current.key> => => key:> > return> current.value> > current> => current.> next> > > raise> KeyError(key)> > > def> remove(> self> , key):> > index> => self> ._hash(key)> > > previous> => None> > current> => self> .table[index]> > > while> current:> > if> current.key> => => key:> > if> previous:> > previous.> next> => current.> next> > else> :> > self> .table[index]> => current.> next> > self> .size> -> => 1> > return> > previous> => current> > current> => current.> next> > > raise> KeyError(key)> > > def> __len__(> self> ):> > return> self> .size> > > def> __contains__(> self> , key):> > try> :> > self> .search(key)> > return> True> > except> KeyError:> > return> False> > > # Driver code> if> __name__> => => '__main__'> :> > > # Create a hash table with> > # a capacity of 5> > ht> => HashTable(> 5> )> > > # Add some key-value pairs> > # to the hash table> > ht.insert(> 'apple'> ,> 3> )> > ht.insert(> 'banana'> ,> 2> )> > ht.insert(> 'cherry'> ,> 5> )> > > # Check if the hash table> > # contains a key> > print> (> 'apple'> in> ht)> # True> > print> (> 'durian'> in> ht)> # False> > > # Get the value for a key> > print> (ht.search(> 'banana'> ))> # 2> > > # Update the value for a key> > ht.insert(> 'banana'> ,> 4> )> > print> (ht.search(> 'banana'> ))> # 4> > > ht.remove(> 'apple'> )> > # Check the size of the hash table> > print> (> len> (ht))> # 3> |
Вихід
True False 2 4 3
Часова складність і просторова складність:
- The часова складність з вставка , пошук і видалити Методи в хеш-таблиці з використанням окремого ланцюжка залежать від розміру хеш-таблиці, кількості пар ключ-значення в хеш-таблиці та довжини пов’язаного списку в кожному індексі.
- Припускаючи хорошу хеш-функцію та рівномірний розподіл ключів, очікувана часова складність цих методів становить О(1) для кожної операції. Однак у гіршому випадку може бути тимчасова складність O(n) , де n – кількість пар ключ-значення в хеш-таблиці.
- Однак важливо вибрати хорошу хеш-функцію та відповідний розмір для хеш-таблиці, щоб мінімізувати ймовірність колізій і забезпечити хорошу продуктивність.
- The складність простору хеш-таблиці з використанням окремого ланцюжка залежить від розміру хеш-таблиці та кількості пар ключ-значення, що зберігаються в хеш-таблиці.
- Сама хеш-таблиця приймає О(м) простір, де m – ємність хеш-таблиці. Кожен зв’язаний вузол списку приймає О(1) простору, і в пов’язаних списках може бути щонайбільше n вузлів, де n – це кількість пар ключ-значення, що зберігаються в хеш-таблиці.
- Тому загальна складність простору становить O(m + n) .
висновок:
На практиці важливо вибрати відповідну ємність для хеш-таблиці, щоб збалансувати використання простору та ймовірність колізій. Якщо ємність занадто мала, ймовірність колізій зростає, що може спричинити погіршення продуктивності. З іншого боку, якщо ємність занадто велика, хеш-таблиця може споживати більше пам’яті, ніж необхідно.