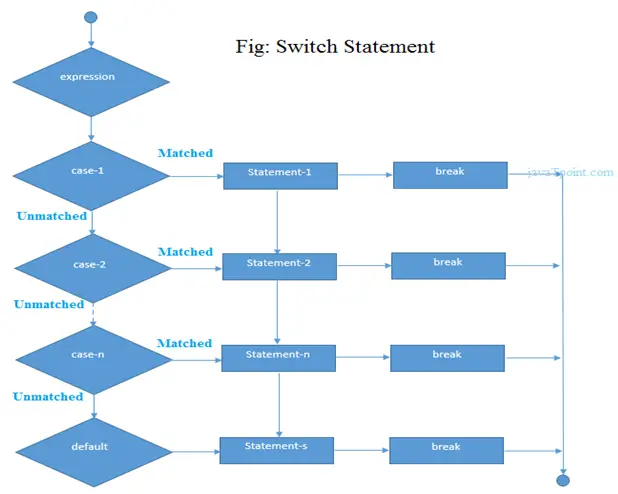
Descărcarea fișierelor de pe web folosind Python
Cereri este o bibliotecă HTTP versatilă în python cu diverse aplicații. Una dintre aplicațiile sale este descărcarea unui fișier de pe web folosind adresa URL a fișierului. Instalare: First of all you would need to download the requests library. You can directly install it using pip by typing following command: Deoarece toate datele fișierului nu pot fi stocate de un singur șir pe care îl folosim r.iter_content metoda de încărcare a datelor în bucăți, specificând dimensiunea bucăților.
pip install requestsOr download it directly from Aici și instalați manual.
Descărcarea fișierelor
Python3 # imported the requests library import requests image_url = 'https://www.python.org/static/community_logos/python-logo-master-v3-TM.webp' # URL of the image to be downloaded is defined as image_url r = requests . get ( image_url ) # create HTTP response object # send a HTTP request to the server and save # the HTTP response in a response object called r with open ( 'python_logo.webp' 'wb' ) as f : # Saving received content as a png file in # binary format # write the contents of the response (r.content) # to a new file in binary mode. f . write ( r . content )
This small piece of code written above will download the following image from the web. Now check your local directory(the folder where this script resides) and you will find this image: All we need is the URL of the image source. (You can get the URL of image source by right-clicking on the image and selecting the View Image option.) Descărcați fișiere mari
Conținutul răspunsului HTTP ( r.conținut ) nu este altceva decât un șir care stochează datele fișierului. Deci nu va fi posibil să salvați toate datele într-un singur șir în cazul fișierelor mari. Pentru a depăși această problemă, facem câteva modificări programului nostru:r = requests.get(URL stream = True)Setting curent parametru la Adevărat va determina descărcarea numai antetelor de răspuns și conexiunea rămâne deschisă. Acest lucru evită citirea conținutului dintr-o dată în memorie pentru răspunsuri mari. O bucată fixă va fi încărcată de fiecare dată r.iter_content is iterated. Here is an example: Python3
import requests file_url = 'http://codex.cs.yale.edu/avi/db-book/db4/slide-dir/ch1-2.pdf' r = requests . get ( file_url stream = True ) with open ( 'python.pdf' 'wb' ) as pdf : for chunk in r . iter_content ( chunk_size = 1024 ): # writing one chunk at a time to pdf file if chunk : pdf . write ( chunk )
Descărcarea videoclipurilor
În acest exemplu, suntem interesați să descărcam toate prelegerile video disponibile despre aceasta pagină web . Toate arhivele acestei prelegeri sunt disponibile Aici . So we first scrape the webpage to extract all video links and then download the videos one by one. Python3 import requests from bs4 import BeautifulSoup ''' URL of the archive web-page which provides link to all video lectures. It would have been tiring to download each video manually. In this example we first crawl the webpage to extract all the links and then download videos. ''' # specify the URL of the archive here archive_url = 'https://public.websites.umich.edu/errors/404.html def get_video_links (): # create response object r = requests . get ( archive_url ) # create beautiful-soup object soup = BeautifulSoup ( r . content 'html5lib' ) # find all links on web-page links = soup . findAll ( 'a' ) # filter the link sending with .mp4 video_links = [ archive_url + link [ 'href' ] for link in links if link [ 'href' ] . endswith ( 'mp4' )] return video_links def download_video_series ( video_links ): for link in video_links : '''iterate through all links in video_links and download them one by one''' # obtain filename by splitting url and getting # last string file_name = link . split ( '/' )[ - 1 ] print ( 'Downloading file: %s ' % file_name ) # create response object r = requests . get ( link stream = True ) # download started with open ( file_name 'wb' ) as f : for chunk in r . iter_content ( chunk_size = 1024 * 1024 ): if chunk : f . write ( chunk ) print ( ' %s downloaded! n ' % file_name ) print ( 'All videos downloaded!' ) return if __name__ == '__main__' : # getting all video links video_links = get_video_links () # download all videos download_video_series ( video_links )
Advantages of using Requests library to download web files are: - Se pot descărca cu ușurință directoarele web, iterând recursiv prin site-ul web!
- Aceasta este o metodă independentă de browser și mult mai rapidă!
- Se poate pur și simplu să răzuiască o pagină web pentru a obține toate adresele URL ale fișierelor de pe o pagină web și, prin urmare, să descărcați toate fișierele într-o singură comandă -
Implementarea Web Scraping în Python cu BeautifulSoup