Regex w Pythonie: re.search() VS re.findall()
Warunek wstępny: Wyrażenie regularne z przykładami | Pyton
Wyrażenie regularne (czasami nazywane wyrażeniem wymiernym) to sekwencja znaków definiująca wzorzec wyszukiwania, używana głównie do dopasowywania wzorców z ciągami lub dopasowywania ciągów, tj. operacji przypominających wyszukiwanie i zamianę. Wyrażenia regularne to uogólniony sposób dopasowywania wzorców do sekwencji znaków.
Moduł Wyrażenia regularne (RE) określa zestaw pasujących do niego ciągów znaków (wzorzec). Aby zrozumieć analogię RE, MetaCharacters> są przydatne, ważne i będą wykorzystywane w funkcjach modułu re> .
Istnieje w sumie 14 metaznaków i zostaną omówione w miarę ich podążania za funkcjami:
Used to drop the special meaning of character following it (discussed below) [] Represent a character class ^ Matches the beginning $ Matches the end . Matches any character except newline ? Matches zero or one occurrence. | Means OR (Matches with any of the characters separated by it. * Any number of occurrences (including 0 occurrences) + One or more occurrences {} Indicate number of occurrences of a preceding RE to match. () Enclose a group of REs badania()
re.search()> metoda albo zwraca None (jeśli wzorzec nie pasuje), albo a re.MatchObject> który zawiera informację o pasującej części ciągu. Ta metoda kończy się po pierwszym dopasowaniu, dlatego najlepiej nadaje się do testowania wyrażeń regularnych, a nie do wyodrębniania danych.
Przykład:
Python3
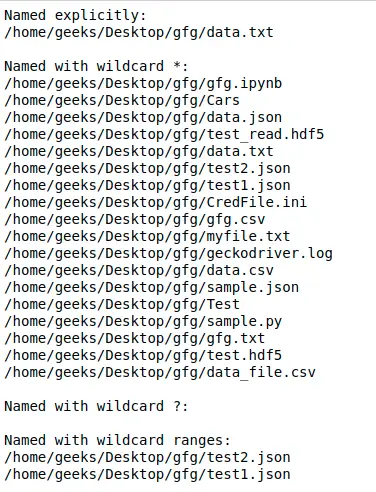
# A Python program to demonstrate working of re.match().> import> re> > # Lets use a regular expression to match a date string> # in the form of Month name followed by day number> regex> => r> '([a-zA-Z]+) (d+)'> > match> => re.search(regex,> 'I was born on June 24'> )> > if> match !> => None> :> > > # We reach here when the expression '([a-zA-Z]+) (d+)'> > # matches the date string.> > > # This will print [14, 21), since it matches at index 14> > # and ends at 21.> > print> (> 'Match at index % s, % s'> %> (match.start(), match.end()))> > > # We us group() method to get all the matches and> > # captured groups. The groups contain the matched values.> > # In particular:> > # match.group(0) always returns the fully matched string> > # match.group(1) match.group(2), ... return the capture> > # groups in order from left to right in the input string> > # match.group() is equivalent to match.group(0)> > > # So this will print 'June 24'> > print> (> 'Full match: % s'> %> (match.group(> 0> )))> > > # So this will print 'June'> > print> (> 'Month: % s'> %> (match.group(> 1> )))> > > # So this will print '24'> > print> (> 'Day: % s'> %> (match.group(> 2> )))> > else> :> > print> (> 'The regex pattern does not match.'> )> |
Wyjście:
Match at index 14, 21 Full match: June 24 Month: June Day: 24
ponownie.znajdź()
Zwróć wszystkie nienakładające się dopasowania wzorca w ciągu znaków jako listę ciągów. Ciąg jest skanowany od lewej do prawej, a dopasowania są zwracane w znalezionej kolejności.
Przykład:
Python3
# A Python program to demonstrate working of> # findall()> import> re> > # A sample text string where regular expression> # is searched.> string> => '''Hello my Number is 123456789 and> > my friend's number is 987654321'''> > # A sample regular expression to find digits.> regex> => 'd+'> > match> => re.findall(regex, string)> print> (match)> |
Wyjście:
['123456789', '987654321']