Lær DSA med Python | Python-datastrukturer og algoritmer

Denne opplæringen er en nybegynnervennlig guide for lære datastrukturer og algoritmer ved hjelp av Python. I denne artikkelen vil vi diskutere de innebygde datastrukturene som lister, tuples, ordbøker osv., og noen brukerdefinerte datastrukturer som f.eks. koblede lister , trær , grafer , etc, og traversering samt søke- og sorteringsalgoritmer ved hjelp av gode og godt forklarte eksempler og øvingsspørsmål.

Lister
Python-lister er ordnede samlinger av data akkurat som arrays i andre programmeringsspråk. Den tillater forskjellige typer elementer i listen. Implementeringen av Python List ligner Vectors i C++ eller ArrayList i JAVA. Den kostbare operasjonen er å sette inn eller slette elementet fra begynnelsen av listen ettersom alle elementene må flyttes. Innsetting og sletting på slutten av listen kan også bli kostbart i tilfelle det forhåndstildelte minnet blir fullt.
Eksempel: Opprette Python-liste
Python3 List = [1, 2, 3, 'GFG', 2.3] print(List)
Produksjon
[1, 2, 3, 'GFG', 2.3]
Listeelementer kan nås av den tilordnede indeksen. I python-startindeksen på listen er en sekvens 0 og sluttindeksen er (hvis N elementer er der) N-1.
Eksempel: Python List Operations
Python3 # Creating a List with # the use of multiple values List = ['Geeks', 'For', 'Geeks'] print('
List containing multiple values: ') print(List) # Creating a Multi-Dimensional List # (By Nesting a list inside a List) List2 = [['Geeks', 'For'], ['Geeks']] print('
Multi-Dimensional List: ') print(List2) # accessing a element from the # list using index number print('Accessing element from the list') print(List[0]) print(List[2]) # accessing a element using # negative indexing print('Accessing element using negative indexing') # print the last element of list print(List[-1]) # print the third last element of list print(List[-3]) Produksjon
List containing multiple values: ['Geeks', 'For', 'Geeks'] Multi-Dimensional List: [['Geeks', 'For'], ['Geeks']] Accessing element from the list Geeks Geeks Accessing element using negative indexing Geeks Geeks
Tuppel
Python-tupler ligner på lister, men Tuples er uforanderlig i naturen, dvs. når den er opprettet, kan den ikke endres. Akkurat som en liste, kan en Tuple også inneholde elementer av ulike typer.
I Python lages tupler ved å plassere en sekvens av verdier atskilt med 'komma' med eller uten bruk av parenteser for gruppering av datasekvensen.
Merk: For å lage en tuppel av ett element må det være et etterfølgende komma. For eksempel vil (8,) lage en tuppel som inneholder 8 som element.
Eksempel: Python Tuple Operations
Python3 # Creating a Tuple with # the use of Strings Tuple = ('Geeks', 'For') print('
Tuple with the use of String: ') print(Tuple) # Creating a Tuple with # the use of list list1 = [1, 2, 4, 5, 6] print('
Tuple using List: ') Tuple = tuple(list1) # Accessing element using indexing print('First element of tuple') print(Tuple[0]) # Accessing element from last # negative indexing print('
Last element of tuple') print(Tuple[-1]) print('
Third last element of tuple') print(Tuple[-3]) Produksjon
Tuple with the use of String: ('Geeks', 'For') Tuple using List: First element of tuple 1 Last element of tuple 6 Third last element of tuple 4 Sett
Python-sett er en foranderlig samling av data som ikke tillater noen duplisering. Sett brukes i utgangspunktet til å inkludere medlemskapstesting og eliminere dupliserte oppføringer. Datastrukturen som brukes i dette er Hashing, en populær teknikk for å utføre innsetting, sletting og kryssing i O(1) i gjennomsnitt.
Hvis flere verdier er tilstede på samme indeksposisjon, blir verdien lagt til den indeksposisjonen for å danne en koblet liste. I, er CPython-sett implementert ved hjelp av en ordbok med dummy-variabler, hvor nøkkelvesener medlemmene setter med større optimaliseringer av tidskompleksiteten.
Sett implementering:

Sett med mange operasjoner på en enkelt hashtabell:

Eksempel: Python-settoperasjoner
Python3 # Creating a Set with # a mixed type of values # (Having numbers and strings) Set = set([1, 2, 'Geeks', 4, 'For', 6, 'Geeks']) print('
Set with the use of Mixed Values') print(Set) # Accessing element using # for loop print('
Elements of set: ') for i in Set: print(i, end =' ') print() # Checking the element # using in keyword print('Geeks' in Set) Produksjon
Set with the use of Mixed Values {1, 2, 4, 6, 'For', 'Geeks'} Elements of set: 1 2 4 6 For Geeks True Frosne sett
Frosne sett i Python er uforanderlige objekter som bare støtter metoder og operatører som produserer et resultat uten å påvirke det frosne settet eller settene de brukes på. Mens elementer i et sett kan endres når som helst, forblir elementene i det frosne settet de samme etter opprettelsen.
Eksempel: Python Frozen sett
Python3 # Same as {'a', 'b','c'} normal_set = set(['a', 'b','c']) print('Normal Set') print(normal_set) # A frozen set frozen_set = frozenset(['e', 'f', 'g']) print('
Frozen Set') print(frozen_set) # Uncommenting below line would cause error as # we are trying to add element to a frozen set # frozen_set.add('h') Produksjon
Normal Set {'a', 'b', 'c'} Frozen Set frozenset({'f', 'g', 'e'}) String
Python-strenger er den uforanderlige rekken av byte som representerer Unicode-tegn. Python har ikke en tegndatatype, et enkelt tegn er ganske enkelt en streng med lengden 1.
Merk: Siden strenger er uforanderlige, vil endring av en streng resultere i å lage en ny kopi.
Eksempel: Python-strengoperasjoner
Python3 String = 'Welcome to GeeksForGeeks' print('Creating String: ') print(String) # Printing First character print('
First character of String is: ') print(String[0]) # Printing Last character print('
Last character of String is: ') print(String[-1]) Produksjon
Creating String: Welcome to GeeksForGeeks First character of String is: W Last character of String is: s
Ordbok
Python-ordbok er en uordnet samling av data som lagrer data i formatet nøkkel:verdi-par. Det er som hashtabeller på et hvilket som helst annet språk med tidskompleksiteten til O(1). Indeksering av Python Dictionary gjøres ved hjelp av taster. Disse er av hvilken som helst hashbar type, dvs. et objekt som aldri kan endres som strenger, tall, tupler, osv. Vi kan lage en ordbok ved å bruke krøllete klammeparenteser ({}) eller ordbokforståelse.
Eksempel: Python Dictionary Operations
Python3 # Creating a Dictionary Dict = {'Name': 'Geeks', 1: [1, 2, 3, 4]} print('Creating Dictionary: ') print(Dict) # accessing a element using key print('Accessing a element using key:') print(Dict['Name']) # accessing a element using get() # method print('Accessing a element using get:') print(Dict.get(1)) # creation using Dictionary comprehension myDict = {x: x**2 for x in [1,2,3,4,5]} print(myDict) Produksjon
Creating Dictionary: {'Name': 'Geeks', 1: [1, 2, 3, 4]} Accessing a element using key: Geeks Accessing a element using get: [1, 2, 3, 4] {1: 1, 2: 4, 3: 9, 4: 16, 5: 25} Matrise
En matrise er en 2D-matrise der hvert element er av strengt tatt samme størrelse. For å lage en matrise vil vi bruke NumPy-pakke .
Eksempel: Python NumPy Matrix Operations
Python3 import numpy as np a = np.array([[1,2,3,4],[4,55,1,2], [8,3,20,19],[11,2,22,21]]) m = np.reshape(a,(4, 4)) print(m) # Accessing element print('
Accessing Elements') print(a[1]) print(a[2][0]) # Adding Element m = np.append(m,[[1, 15,13,11]],0) print('
Adding Element') print(m) # Deleting Element m = np.delete(m,[1],0) print('
Deleting Element') print(m) Produksjon
[[ 1 2 3 4] [ 4 55 1 2] [ 8 3 20 19] [11 2 22 21]] Accessing Elements [ 4 55 1 2] 8 Adding Element [[ 1 2 3 4] [ 4 55 1 2] [ 8 3 20 19] [11 2 22 21] [ 1 15 13 11]] Deleting Element [[ 1 2 3 4] [ 8 3 20 19] [11 2 22 21] [ 1 15 13 11]]
Bytearray
Python Bytearray gir en foranderlig sekvens av heltall i området 0 <= x < 256.
Eksempel: Python Bytearray-operasjoner
Python3 # Creating bytearray a = bytearray((12, 8, 25, 2)) print('Creating Bytearray:') print(a) # accessing elements print('
Accessing Elements:', a[1]) # modifying elements a[1] = 3 print('
After Modifying:') print(a) # Appending elements a.append(30) print('
After Adding Elements:') print(a) Produksjon
Creating Bytearray: bytearray(b'x0cx08x19x02') Accessing Elements: 8 After Modifying: bytearray(b'x0cx03x19x02') After Adding Elements: bytearray(b'x0cx03x19x02x1e')
Koblet liste
EN koblet liste er en lineær datastruktur, der elementene ikke er lagret på sammenhengende minneplasseringer. Elementene i en koblet liste er koblet ved hjelp av pekere som vist i bildet nedenfor:

En koblet liste er representert med en peker til den første noden i den koblede listen. Den første noden kalles hodet. Hvis den koblede listen er tom, er verdien på hodet NULL. Hver node i en liste består av minst to deler:
- Data
- Peker (eller referanse) til neste node
Eksempel: Definere lenket liste i Python
Python3 # Node class class Node: # Function to initialize the node object def __init__(self, data): self.data = data # Assign data self.next = None # Initialize # next as null # Linked List class class LinkedList: # Function to initialize the Linked # List object def __init__(self): self.head = None
La oss lage en enkel koblet liste med 3 noder.
Python3 # A simple Python program to introduce a linked list # Node class class Node: # Function to initialise the node object def __init__(self, data): self.data = data # Assign data self.next = None # Initialize next as null # Linked List class contains a Node object class LinkedList: # Function to initialize head def __init__(self): self.head = None # Code execution starts here if __name__=='__main__': # Start with the empty list llist = LinkedList() llist.head = Node(1) second = Node(2) third = Node(3) ''' Three nodes have been created. We have references to these three blocks as head, second and third llist.head second third | | | | | | +----+------+ +----+------+ +----+------+ | 1 | None | | 2 | None | | 3 | None | +----+------+ +----+------+ +----+------+ ''' llist.head.next = second; # Link first node with second ''' Now next of first Node refers to second. So they both are linked. llist.head second third | | | | | | +----+------+ +----+------+ +----+------+ | 1 | o-------->| 2 | null | | 3 | null | +----+------+ +----+------+ +----+------+ ''' second.next = tredje ; # Koble andre node med tredje node ''' Nå refererer neste av andre node til tredje. Så alle tre nodene er koblet sammen. llist.head andre tredje | | | | | | +----+------+ +----+-----+ +----+-----+ | 1 | o-------->| 2 | o-------->| 3 | null | +----+------+ +----+-----+ +----+-----+ '''
Linket listegjennomgang
I forrige program har vi laget en enkel lenket liste med tre noder. La oss krysse den opprettede listen og skrive ut dataene til hver node. For gjennomgang, la oss skrive en generell funksjon printList() som skriver ut en gitt liste.
Python3 # A simple Python program for traversal of a linked list # Node class class Node: # Function to initialise the node object def __init__(self, data): self.data = data # Assign data self.next = None # Initialize next as null # Linked List class contains a Node object class LinkedList: # Function to initialize head def __init__(self): self.head = None # This function prints contents of linked list # starting from head def printList(self): temp = self.head while (temp): print (temp.data) temp = temp.next # Code execution starts here if __name__=='__main__': # Start with the empty list llist = LinkedList() llist.head = Node(1) second = Node(2) third = Node(3) llist.head.next = second; # Link first node with second second.next = third; # Link second node with the third node llist.printList()
Produksjon
1 2 3
Flere artikler om Linked List
- Innsetting av lenket liste
- Sletting av koblet liste (sletting av en gitt nøkkel)
- Sletting av koblet liste (sletting av en nøkkel ved gitt posisjon)
- Finn lengden på en koblet liste (Iterativ og rekursiv)
- Søk etter et element i en koblet liste (Iterativ og rekursiv)
- Nte node fra slutten av en koblet liste
- Omvendt en koblet liste

Funksjonene knyttet til stack er:
- tomme() – Returnerer om stabelen er tom – Tidskompleksitet: O(1)
- størrelse() – Returnerer størrelsen på stabelen – Tidskompleksitet: O(1)
- topp() – Returnerer en referanse til det øverste elementet i stabelen – Tidskompleksitet: O(1)
- push(a) – Setter inn elementet 'a' på toppen av stabelen – Tidskompleksitet: O(1)
- pop() – Sletter det øverste elementet i stabelen – Tidskompleksitet: O(1)
stack = [] # append() function to push # element in the stack stack.append('g') stack.append('f') stack.append('g') print('Initial stack') print(stack) # pop() function to pop # element from stack in # LIFO order print('
Elements popped from stack:') print(stack.pop()) print(stack.pop()) print(stack.pop()) print('
Stack after elements are popped:') print(stack) # uncommenting print(stack.pop()) # will cause an IndexError # as the stack is now empty Produksjon
Initial stack ['g', 'f', 'g'] Elements popped from stack: g f g Stack after elements are popped: []
Flere artikler om Stack
- Infiks til Postfix-konvertering ved hjelp av Stack
- Prefiks til Infix Conversion
- Prefiks til Postfix-konvertering
- Postfix til Prefikskonvertering
- Postfix til Infix
- Se etter balanserte parenteser i et uttrykk
- Evaluering av Postfix-uttrykk
Som en stabel er kø er en lineær datastruktur som lagrer elementer på en First In First Out (FIFO) måte. Med en kø fjernes det elementet som sist ble lagt til først. Et godt eksempel på køen er en hvilken som helst kø av forbrukere for en ressurs der forbrukeren som kom først blir servert først.

Operasjoner knyttet til køen er:
- Kø: Legger til et element i køen. Hvis køen er full, sies det å være en overløpstilstand – Tidskompleksitet: O(1)
- Tilsvarende: Fjerner et element fra køen. Elementene er poppet i samme rekkefølge som de skyves. Hvis køen er tom, sies det å være en underflyttilstand – Tidskompleksitet: O(1)
- Front: Få det fremre elementet fra køen – Tidskompleksitet: O(1)
- Bak: Få det siste elementet fra køen – Tidskompleksitet: O(1)
# Initializing a queue queue = [] # Adding elements to the queue queue.append('g') queue.append('f') queue.append('g') print('Initial queue') print(queue) # Removing elements from the queue print('
Elements dequeued from queue') print(queue.pop(0)) print(queue.pop(0)) print(queue.pop(0)) print('
Queue after removing elements') print(queue) # Uncommenting print(queue.pop(0)) # will raise and IndexError # as the queue is now empty Produksjon
Initial queue ['g', 'f', 'g'] Elements dequeued from queue g f g Queue after removing elements []
Flere artikler om kø
- Implementer kø ved hjelp av stabler
- Implementer Stack ved hjelp av køer
- Implementer en stabel med enkeltkø
Prioritetskø
Prioriterte køer er abstrakte datastrukturer hvor hver data/verdi i køen har en viss prioritet. For eksempel hos flyselskaper kommer bagasje med tittelen Business eller First-class tidligere enn resten. Priority Queue er en utvidelse av køen med følgende egenskaper.
- Et element med høy prioritet settes ut av kø før et element med lav prioritet.
- Hvis to elementer har samme prioritet, serveres de i henhold til rekkefølgen i køen.
# A simple implementation of Priority Queue # using Queue. class PriorityQueue(object): def __init__(self): self.queue = [] def __str__(self): return ' '.join([str(i) for i in self.queue]) # for checking if the queue is empty def isEmpty(self): return len(self.queue) == 0 # for inserting an element in the queue def insert(self, data): self.queue.append(data) # for popping an element based on Priority def delete(self): try: max = 0 for i in range(len(self.queue)): if self.queue[i]>self.queue[max]: max = i item = self.queue[max] del self.queue[max] return item unntatt IndexError: print() exit() if __name__ == '__main__': myQueue = PriorityQueue( ) myQueue.insert(12) myQueue.insert(1) myQueue.insert(14) myQueue.insert(7) print(myQueue) mens ikke myQueue.isEmpty(): print(myQueue.delete())
Produksjon
12 1 14 7 14 12 7 1
Heap
heapq-modul i Python gir haugdatastrukturen som hovedsakelig brukes til å representere en prioritert kø. Egenskapen til denne datastrukturen er at den alltid gir det minste elementet (min haug) når elementet er poppet. Hver gang elementer skyves eller poppes, opprettholdes haugstrukturen. Heap[0]-elementet returnerer også det minste elementet hver gang. Den støtter utvinning og innsetting av det minste elementet i O(log n) ganger.
Generelt kan heaps være av to typer:
- Max-Heap: I en Max-Heap må nøkkelen som er tilstede ved rotnoden være størst blant nøklene som er tilstede på alle sine barn. Den samme egenskapen må være rekursivt sann for alle undertrær i det binære treet.
- Min-haug: I en Min-Heap må nøkkelen som er tilstede ved rotnoden være minimum blant nøklene som er tilstede på alle dens barn. Den samme egenskapen må være rekursivt sann for alle undertrær i det binære treet.

# importing 'heapq' to implement heap queue import heapq # initializing list li = [5, 7, 9, 1, 3] # using heapify to convert list into heap heapq.heapify(li) # printing created heap print ('The created heap is : ',end='') print (list(li)) # using heappush() to push elements into heap # pushes 4 heapq.heappush(li,4) # printing modified heap print ('The modified heap after push is : ',end='') print (list(li)) # using heappop() to pop smallest element print ('The popped and smallest element is : ',end='') print (heapq.heappop(li)) Produksjon
The created heap is : [1, 3, 9, 7, 5] The modified heap after push is : [1, 3, 4, 7, 5, 9] The popped and smallest element is : 1
Flere artikler om Heap
- Binær haug
- K’th største element i en rekke
- K’te minste/største element i usortert matrise
- Sorter en nesten sortert matrise
- K-te største sum sammenhengende undergruppe
- Minimum sum av to tall dannet av sifre i en matrise
Et tre er en hierarkisk datastruktur som ser ut som figuren nedenfor -
tree ---- j <-- root / f k / a h z <-- leaves
Den øverste noden av treet kalles roten, mens de nederste nodene eller nodene uten barn kalles bladnodene. Nodene som er rett under en node kalles dens barn og nodene som er rett over noe kalles dens overordnede.
EN binært tre er et tre hvis elementer kan ha nesten to barn. Siden hvert element i et binært tre bare kan ha 2 barn, kaller vi dem vanligvis venstre og høyre barn. En binær tre-node inneholder følgende deler.
- Data
- Peker til venstre barn
- Peker til rett barn
Eksempel: Definere nodeklasse
Python3 # A Python class that represents an individual node # in a Binary Tree class Node: def __init__(self,key): self.left = None self.right = None self.val = key
La oss nå lage et tre med 4 noder i Python. La oss anta at trestrukturen ser ut som nedenfor -
tree ---- 1 <-- root / 2 3 / 4
Eksempel: Legge til data i treet
Python3 # Python program to introduce Binary Tree # A class that represents an individual node in a # Binary Tree class Node: def __init__(self,key): self.left = None self.right = None self.val = key # create root root = Node(1) ''' following is the tree after above statement 1 / None None''' root.left = Node(2); root.right = Node(3); ''' 2 and 3 become left and right children of 1 1 / 2 3 / / None None None None''' root.left.left = Node(4); '''4 becomes left child of 2 1 / 2 3 / / 4 None None None / None None'''
Traversering av tre
Trær kan krysses på forskjellige måter. Følgende er de generelt brukte måtene å krysse trær på. La oss vurdere treet nedenfor -
tree ---- 1 <-- root / 2 3 / 4 5
Depth First Traversals:
- I rekkefølge (venstre, rot, høyre): 4 2 5 1 3
- Forhåndsbestilling (Root, Venstre, Høyre): 1 2 4 5 3
- Postordre (venstre, høyre, rot): 4 5 2 3 1
Algoritme rekkefølge (tre)
- Gå gjennom venstre undertre, dvs. ring Inorder (venstre-undertre)
- Besøk roten.
- Gå gjennom høyre undertre, dvs. ring Inorder (høyre undertre)
Algoritme forhåndsbestilling (tre)
- Besøk roten.
- Gå gjennom venstre undertre, dvs. ring Preorder (venstre-undertre)
- Gå gjennom høyre undertre, dvs. ring Preorder (høyre undertre)
Algoritme Postordre (tre)
- Gå gjennom venstre undertre, dvs. ring Postorder (venstre-undertre)
- Gå gjennom høyre undertre, dvs. ring Postorder (høyre undertre)
- Besøk roten.
# Python program to for tree traversals # A class that represents an individual node in a # Binary Tree class Node: def __init__(self, key): self.left = None self.right = None self.val = key # A function to do inorder tree traversal def printInorder(root): if root: # First recur on left child printInorder(root.left) # then print the data of node print(root.val), # now recur on right child printInorder(root.right) # A function to do postorder tree traversal def printPostorder(root): if root: # First recur on left child printPostorder(root.left) # the recur on right child printPostorder(root.right) # now print the data of node print(root.val), # A function to do preorder tree traversal def printPreorder(root): if root: # First print the data of node print(root.val), # Then recur on left child printPreorder(root.left) # Finally recur on right child printPreorder(root.right) # Driver code root = Node(1) root.left = Node(2) root.right = Node(3) root.left.left = Node(4) root.left.right = Node(5) print('Preorder traversal of binary tree is') printPreorder(root) print('
Inorder traversal of binary tree is') printInorder(root) print('
Postorder traversal of binary tree is') printPostorder(root) Produksjon
Preorder traversal of binary tree is 1 2 4 5 3 Inorder traversal of binary tree is 4 2 5 1 3 Postorder traversal of binary tree is 4 5 2 3 1
Tidskompleksitet – O(n)
Breadth-First eller Level Order Traversal
Nivåordregjennomgang av et tre er bredde-første kryssing for treet. Nivårekkefølgen for treet ovenfor er 1 2 3 4 5.
For hver node besøkes først noden, og deretter settes dens underordnede noder i en FIFO-kø. Nedenfor er algoritmen for det samme –
- Opprett en tom kø q
- temp_node = rot /*start fra rot*/
- Loop mens temp_node ikke er NULL
- skriv ut temp_node->data.
- Sett temp_nodes barn i kø (først venstre og deretter høyre barn) til q
- Sett en node i kø fra q
# Python program to print level # order traversal using Queue # A node structure class Node: # A utility function to create a new node def __init__(self ,key): self.data = key self.left = None self.right = None # Iterative Method to print the # height of a binary tree def printLevelOrder(root): # Base Case if root is None: return # Create an empty queue # for level order traversal queue = [] # Enqueue Root and initialize height queue.append(root) while(len(queue)>0): # Skriv ut forsiden av køen og # fjern den fra køutskrift (kø[0].data) node = queue.pop(0) # Enqueue left child hvis node.left ikke er Ingen: queue.append(node.left ) # Enqueue right child if node.right ikke er Ingen: queue.append(node.right) # Driver Program for å teste over funksjonen root = Node(1) root.left = Node(2) root.right = Node(3) root.left.left = Node(4) root.left.right = Node(5) print ('Level Order Traversal av binært tre er -') printLevelOrder(root) Produksjon
Level Order Traversal of binary tree is - 1 2 3 4 5
Tidskompleksitet: O(n)
Flere artikler om Binary Tree
- Innsetting i et binært tre
- Sletting i et binært tre
- Inorder Tree Traversal uten rekursjon
- Bestill Tree Traversal uten rekursjon og uten stabel!
- Skriv ut Postorder-gjennomgang fra gitte Inorder- og Preorder-gjennomganger
- Finn postorder-traversering av BST fra preorder-traversering
Binært søketre er en nodebasert binær tredatastruktur som har følgende egenskaper:
- Det venstre undertreet til en node inneholder kun noder med nøkler som er mindre enn nodens nøkkel.
- Det høyre undertreet til en node inneholder bare noder med nøkler som er større enn nodens nøkkel.
- Det venstre og høyre undertreet må også være et binært søketre.

De ovennevnte egenskapene til det binære søketreet gir en rekkefølge mellom nøkler slik at operasjoner som søk, minimum og maksimum kan gjøres raskt. Hvis det ikke er noen rekkefølge, må vi kanskje sammenligne hver nøkkel for å søke etter en gitt nøkkel.
Søkeelement
- Start fra roten.
- Sammenlign søkeelementet med rot, hvis det er mindre enn rot, så recurse for venstre, ellers recurse for høyre.
- Hvis elementet som skal søkes finnes hvor som helst, returner true, ellers returner false.
# A utility function to search a given key in BST def search(root,key): # Base Cases: root is null or key is present at root if root is None or root.val == key: return root # Key is greater than root's key if root.val < key: return search(root.right,key) # Key is smaller than root's key return search(root.left,key)
Innsetting av nøkkel
- Start fra roten.
- Sammenlign innsettingselementet med rot, hvis mindre enn rot, så recurse for venstre, ellers recurse for høyre.
- Etter å ha nådd slutten, bare sett inn den noden til venstre (hvis mindre enn gjeldende) ellers til høyre.
# Python program to demonstrate # insert operation in binary search tree # A utility class that represents # an individual node in a BST class Node: def __init__(self, key): self.left = None self.right = None self.val = key # A utility function to insert # a new node with the given key def insert(root, key): if root is None: return Node(key) else: if root.val == key: return root elif root.val < key: root.right = insert(root.right, key) else: root.left = insert(root.left, key) return root # A utility function to do inorder tree traversal def inorder(root): if root: inorder(root.left) print(root.val) inorder(root.right) # Driver program to test the above functions # Let us create the following BST # 50 # / # 30 70 # / / # 20 40 60 80 r = Node(50) r = insert(r, 30) r = insert(r, 20) r = insert(r, 40) r = insert(r, 70) r = insert(r, 60) r = insert(r, 80) # Print inorder traversal of the BST inorder(r)
Produksjon
20 30 40 50 60 70 80
Flere artikler om binært søketre
- Binært søketre – Slettnøkkel
- Konstruer BST fra gitt forhåndsbestillingsgjennomgang | Sett 1
- Konvertering av binært tre til binært søketre
- Finn noden med minimumsverdi i et binært søketre
- Et program for å sjekke om et binært tre er BST eller ikke
EN kurve er en ikke-lineær datastruktur som består av noder og kanter. Nodene blir noen ganger også referert til som toppunkter, og kantene er linjer eller buer som forbinder hvilke som helst to noder i grafen. Mer formelt kan en graf defineres som en graf som består av et begrenset sett med toppunkter (eller noder) og et sett med kanter som forbinder et par noder.

I grafen ovenfor er settet med toppunkter V = {0,1,2,3,4} og settet med kanter E = {01, 12, 23, 34, 04, 14, 13}. De følgende to er de mest brukte representasjonene av en graf.
- Adjacency Matrix
- Tilknytningsliste
Adjacency Matrix
Adjacency Matrix er en 2D-array av størrelse V x V der V er antall toppunkter i en graf. La 2D-matrisen være adj[][], et spor adj[i][j] = 1 indikerer at det er en kant fra toppunkt i til toppunkt j. Nærhetsmatrisen for en urettet graf er alltid symmetrisk. Adjacency Matrix brukes også til å representere vektede grafer. Hvis adj[i][j] = w, så er det en kant fra toppunkt i til toppunkt j med vekt w.
Python3 # A simple representation of graph using Adjacency Matrix class Graph: def __init__(self,numvertex): self.adjMatrix = [[-1]*numvertex for x in range(numvertex)] self.numvertex = numvertex self.vertices = {} self.verticeslist =[0]*numvertex def set_vertex(self,vtx,id): if 0 <=vtx <=self.numvertex: self.vertices[id] = vtx self.verticeslist[vtx] = id def set_edge(self,frm,to,cost=0): frm = self.vertices[frm] to = self.vertices[to] self.adjMatrix[frm][to] = cost # for directed graph do not add this self.adjMatrix[to][frm] = cost def get_vertex(self): return self.verticeslist def get_edges(self): edges=[] for i in range (self.numvertex): for j in range (self.numvertex): if (self.adjMatrix[i][j]!=-1): edges.append((self.verticeslist[i],self.verticeslist[j],self.adjMatrix[i][j])) return edges def get_matrix(self): return self.adjMatrix G =Graph(6) G.set_vertex(0,'a') G.set_vertex(1,'b') G.set_vertex(2,'c') G.set_vertex(3,'d') G.set_vertex(4,'e') G.set_vertex(5,'f') G.set_edge('a','e',10) G.set_edge('a','c',20) G.set_edge('c','b',30) G.set_edge('b','e',40) G.set_edge('e','d',50) G.set_edge('f','e',60) print('Vertices of Graph') print(G.get_vertex()) print('Edges of Graph') print(G.get_edges()) print('Adjacency Matrix of Graph') print(G.get_matrix()) Produksjon
Toppunktene til grafen
['A B C D E F']
Kanter av graf
[('a', 'c', 20), ('a', 'e', 10), ('b', 'c', 30), ('b', 'e', 40), ( 'c', 'a', 20), ('c', 'b', 30), ('d', 'e', 50), ('e', 'a', 10), ('e ', 'b', 40), ('e', 'd', 50), ('e', 'f', 60), ('f', 'e', 60)]
Adjacency Matrix of Graph
[[-1, -1, 20, -1, 10, -1], [-1, -1, 30, -1, 40, -1], [20, 30, -1, -1, -1 , -1], [-1, -1, -1, -1, 50, -1], [10, 40, -1, 50, -1, 60], [-1, -1, -1, -1, 60, -1]]
Tilknytningsliste
En rekke lister brukes. Størrelsen på matrisen er lik antall toppunkter. La matrisen være en matrise[]. En inngangsmatrise[i] representerer listen over toppunkter ved siden av det ite toppunktet. Denne representasjonen kan også brukes til å representere en vektet graf. Vektene til kanter kan representeres som lister over par. Følgende er tilstøtende listerepresentasjon av grafen ovenfor.

# A class to represent the adjacency list of the node class AdjNode: def __init__(self, data): self.vertex = data self.next = None # A class to represent a graph. A graph # is the list of the adjacency lists. # Size of the array will be the no. of the # vertices 'V' class Graph: def __init__(self, vertices): self.V = vertices self.graph = [None] * self.V # Function to add an edge in an undirected graph def add_edge(self, src, dest): # Adding the node to the source node node = AdjNode(dest) node.next = self.graph[src] self.graph[src] = node # Adding the source node to the destination as # it is the undirected graph node = AdjNode(src) node.next = self.graph[dest] self.graph[dest] = node # Function to print the graph def print_graph(self): for i in range(self.V): print('Adjacency list of vertex {}
head'.format(i), end='') temp = self.graph[i] while temp: print(' ->{}'.format(temp.vertex), end='') temp = temp.next print('
') # Driverprogram til grafklassen ovenfor hvis __navn__ == '__main__' : V = 5 graf = Graph(V) graph.add_edge(0, 1) graph.add_edge(0, 4) graph.add_edge(1, 2) graph.add_edge(1, 3) graph.add_edge(1, 4) graph.add_edge(2, 3) graph.add_edge(3, 4) graph.print_graph() Produksjon
Adjacency list of vertex 0 head ->4 -> 1 Adjacency liste over toppunkt 1 hode -> 4 -> 3 -> 2 -> 0 Adjacency liste over toppunkt 2 hode -> 3 -> 1 Adjacency liste over toppunkt 3 hode -> 4 -> 2 -> 1 Adjacency liste over toppunkt 4 hode -> 3 -> 1 -> 0
Grafgjennomgang
Breadth-First Search eller BFS
Breadth-First Traversal for en graf ligner på Breadth-First Traversal av et tre. Den eneste fangsten her er, i motsetning til trær, kan grafer inneholde sykluser, så vi kan komme til samme node igjen. For å unngå å behandle en node mer enn én gang, bruker vi en boolsk besøkt matrise. For enkelhets skyld antas det at alle toppunktene er tilgjengelige fra startpunktet.
For eksempel, i følgende graf, starter vi traversering fra toppunkt 2. Når vi kommer til toppunkt 0, ser vi etter alle tilstøtende toppunkter av det. 2 er også et tilstøtende toppunkt på 0. Hvis vi ikke merker besøkte toppunkter, vil 2 bli behandlet på nytt og det blir en ikke-avsluttende prosess. En Breadth-First Traversal av følgende graf er 2, 0, 3, 1.

# Python3 Program to print BFS traversal # from a given source vertex. BFS(int s) # traverses vertices reachable from s. from collections import defaultdict # This class represents a directed graph # using adjacency list representation class Graph: # Constructor def __init__(self): # default dictionary to store graph self.graph = defaultdict(list) # function to add an edge to graph def addEdge(self,u,v): self.graph[u].append(v) # Function to print a BFS of graph def BFS(self, s): # Mark all the vertices as not visited visited = [False] * (max(self.graph) + 1) # Create a queue for BFS queue = [] # Mark the source node as # visited and enqueue it queue.append(s) visited[s] = True while queue: # Dequeue a vertex from # queue and print it s = queue.pop(0) print (s, end = ' ') # Get all adjacent vertices of the # dequeued vertex s. If a adjacent # has not been visited, then mark it # visited and enqueue it for i in self.graph[s]: if visited[i] == False: queue.append(i) visited[i] = True # Driver code # Create a graph given in # the above diagram g = Graph() g.addEdge(0, 1) g.addEdge(0, 2) g.addEdge(1, 2) g.addEdge(2, 0) g.addEdge(2, 3) g.addEdge(3, 3) print ('Following is Breadth First Traversal' ' (starting from vertex 2)') g.BFS(2) Produksjon
Following is Breadth First Traversal (starting from vertex 2) 2 0 3 1
Tidskompleksitet: O(V+E) hvor V er antall toppunkter i grafen og E er antall kanter i grafen.
Depth First Search eller DFS
Depth First Traversal for en graf ligner på Depth First Traversal av et tre. Den eneste fangsten her er, i motsetning til trær, kan grafer inneholde sykluser, en node kan besøkes to ganger. For å unngå å behandle en node mer enn én gang, bruk en boolsk besøkt matrise.
Algoritme:
- Lag en rekursiv funksjon som tar indeksen til noden og en besøkt matrise.
- Merk gjeldende node som besøkt og skriv ut noden.
- Gå gjennom alle tilstøtende og umerkede noder og kall den rekursive funksjonen med indeksen til den tilstøtende noden.
# Python3 program to print DFS traversal # from a given graph from collections import defaultdict # This class represents a directed graph using # adjacency list representation class Graph: # Constructor def __init__(self): # default dictionary to store graph self.graph = defaultdict(list) # function to add an edge to graph def addEdge(self, u, v): self.graph[u].append(v) # A function used by DFS def DFSUtil(self, v, visited): # Mark the current node as visited # and print it visited.add(v) print(v, end=' ') # Recur for all the vertices # adjacent to this vertex for neighbour in self.graph[v]: if neighbour not in visited: self.DFSUtil(neighbour, visited) # The function to do DFS traversal. It uses # recursive DFSUtil() def DFS(self, v): # Create a set to store visited vertices visited = set() # Call the recursive helper function # to print DFS traversal self.DFSUtil(v, visited) # Driver code # Create a graph given # in the above diagram g = Graph() g.addEdge(0, 1) g.addEdge(0, 2) g.addEdge(1, 2) g.addEdge(2, 0) g.addEdge(2, 3) g.addEdge(3, 3) print('Following is DFS from (starting from vertex 2)') g.DFS(2) Produksjon
Following is DFS from (starting from vertex 2) 2 0 1 3
Flere artikler om graf
- Tegn grafiske representasjoner ved hjelp av sett og hash
- Finn Mother Vertex i en graf
- Iterativ dybde først søk
- Tell antall noder på gitt nivå i et tre ved å bruke BFS
- Tell alle mulige veier mellom to toppunkter
Prosessen der en funksjon kaller seg selv direkte eller indirekte kalles rekursjon og den tilsvarende funksjonen kalles a rekursiv funksjon . Ved å bruke de rekursive algoritmene kan visse problemer løses ganske enkelt. Eksempler på slike problemer er Towers of Hanoi (TOH), Inorder/Preorder/Postorder Tree Traversals, DFS of Graph, etc.
Hva er grunntilstanden ved rekursjon?
I det rekursive programmet er løsningen på grunntilfellet gitt og løsningen av det større problemet uttrykkes i form av mindre problemer.
def fact(n): # base case if (n <= 1) return 1 else return n*fact(n-1)
I eksemplet ovenfor er grunntilfelle for n <= 1 definert og større verdi av tall kan løses ved å konvertere til mindre til grunntilfelle er nådd.
Hvordan tildeles minne til ulike funksjonskall i rekursjon?
Når en funksjon kalles fra main(), blir minnet allokert til den på stabelen. En rekursiv funksjon kaller seg selv, minnet for en kalt funksjon blir allokert på toppen av minnet som er allokert til den kallende funksjonen, og en annen kopi av lokale variabler opprettes for hvert funksjonskall. Når basistilfellet er nådd, returnerer funksjonen sin verdi til funksjonen den kalles av, og minnet blir deallokert og prosessen fortsetter.
La oss ta eksempelet på hvordan rekursjon fungerer ved å ta en enkel funksjon.
Python3 # A Python 3 program to # demonstrate working of # recursion def printFun(test): if (test < 1): return else: print(test, end=' ') printFun(test-1) # statement 2 print(test, end=' ') return # Driver Code test = 3 printFun(test)
Produksjon
3 2 1 1 2 3
Minnestakken er vist i diagrammet nedenfor.
Flere artikler om rekursjon
- Rekursjon
- Rekursjon i Python
- Øvingsspørsmål for rekursjon | Sett 1
- Øvingsspørsmål for rekursjon | Sett 2
- Øvingsspørsmål for rekursjon | Sett 3
- Øvingsspørsmål for rekursjon | Sett 4
- Øvingsspørsmål for rekursjon | Sett 5
- Øvingsspørsmål for rekursjon | Sett 6
- Øvingsspørsmål for rekursjon | Sett 7
>>> Mer
Dynamisk programmering
Dynamisk programmering er hovedsakelig en optimalisering over ren rekursjon. Uansett hvor vi ser en rekursiv løsning som har gjentatte anrop for samme innganger, kan vi optimalisere den ved hjelp av dynamisk programmering. Tanken er å bare lagre resultatene av delproblemer, slik at vi ikke trenger å beregne dem på nytt ved behov senere. Denne enkle optimaliseringen reduserer tidskompleksiteten fra eksponentiell til polynom. For eksempel, hvis vi skriver enkel rekursiv løsning for Fibonacci-tall, får vi eksponentiell tidskompleksitet og hvis vi optimerer den ved å lagre løsninger av delproblemer, reduseres tidskompleksiteten til lineær.

Tabulering vs Memoisering
Det er to forskjellige måter å lagre verdiene på slik at verdiene til et delproblem kan gjenbrukes. Her vil vi diskutere to mønstre for å løse dynamisk programmeringsproblem (DP):
- Tabell: Opp ned
- Memoisering: Top Down
Tabellering
Som navnet selv antyder, starter du fra bunnen og samler svar til toppen. La oss diskutere når det gjelder statsovergang.
La oss beskrive en tilstand for DP-problemet vårt som er dp[x] med dp[0] som basistilstand og dp[n] som destinasjonstilstand. Så vi må finne verdien av destinasjonstilstand, dvs. dp[n].
Hvis vi starter vår overgang fra vår basistilstand, dvs. dp[0] og følger vår tilstandsovergangsrelasjon for å nå vår destinasjonstilstand dp[n], kaller vi det Bottom-Up-tilnærmingen siden det er ganske tydelig at vi startet overgangen fra nederste basistilstand og nådde den øverste ønskede tilstanden.
Nå, hvorfor kaller vi det tabuleringsmetode?
For å vite dette, la oss først skrive litt kode for å beregne faktoren til et tall ved å bruke nedenfra og opp-tilnærming. Nok en gang, som vår generelle prosedyre for å løse en DP, definerer vi først en tilstand. I dette tilfellet definerer vi en tilstand som dp[x], der dp[x] er å finne faktoren til x.
Nå er det ganske åpenbart at dp[x+1] = dp[x] * (x+1)
# Tabulated version to find factorial x. dp = [0]*MAXN # base case dp[0] = 1; for i in range(n+1): dp[i] = dp[i-1] * i
Memoisering
Nok en gang, la oss igjen beskrive det i form av statsovergang. Hvis vi trenger å finne verdien for en tilstand, si dp[n] og i stedet for å starte fra basistilstanden som dvs. dp[0] spør vi vårt svar fra statene som kan nå destinasjonstilstanden dp[n] etter tilstandsovergangen forhold, så er det top-down-moten til DP.
Her starter vi reisen vår fra den øverste destinasjonsstaten og beregner svaret ved å telle verdiene til tilstander som kan nå destinasjonstilstanden, til vi når den nederste basistilstanden.
Nok en gang, la oss skrive koden for det faktorielle problemet ovenfra og ned
# Memoized version to find factorial x. # To speed up we store the values # of calculated states # initialized to -1 dp[0]*MAXN # return fact x! def solve(x): if (x==0) return 1 if (dp[x]!=-1) return dp[x] return (dp[x] = x * solve(x-1))

Flere artikler om dynamisk programmering
- Optimal underbygningseiendom
- Overlappende underproblemer Egenskap
- Fibonacci tall
- Delmengde med sum delelig med m
- Maksimal sum økende etterfølge
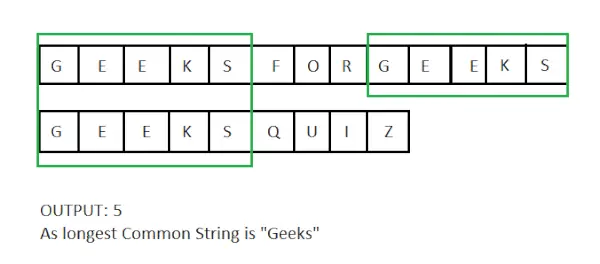
- Lengste felles understreng
Søkealgoritmer
Lineært søk
- Start fra elementet lengst til venstre i arr[] og sammenlign x én etter én med hvert element i arr[]
- Hvis x samsvarer med et element, returner indeksen.
- Hvis x ikke samsvarer med noen av elementene, returnerer du -1.

# Python3 code to linearly search x in arr[]. # If x is present then return its location, # otherwise return -1 def search(arr, n, x): for i in range(0, n): if (arr[i] == x): return i return -1 # Driver Code arr = [2, 3, 4, 10, 40] x = 10 n = len(arr) # Function call result = search(arr, n, x) if(result == -1): print('Element is not present in array') else: print('Element is present at index', result) Produksjon
Element is present at index 3
Tidskompleksiteten til algoritmen ovenfor er O(n).
For mer informasjon, se Lineært søk .
Binært søk
Søk i en sortert matrise ved gjentatte ganger å dele søkeintervallet i to. Begynn med et intervall som dekker hele matrisen. Hvis verdien av søkenøkkelen er mindre enn elementet i midten av intervallet, begrenser du intervallet til nedre halvdel. Ellers, begrense den til øvre halvdel. Kontroller gjentatte ganger til verdien er funnet eller intervallet er tomt.

# Python3 Program for recursive binary search. # Returns index of x in arr if present, else -1 def binarySearch (arr, l, r, x): # Check base case if r>= l: mid = l + (r - l) // 2 # Hvis element er til stede i midten selv hvis arr[mid] == x: return mid # Hvis element er mindre enn mid, så kan # bare være tilstede i venstre undergruppe elif arr[midt]> x: return binært søk(arr, l, mid-1, x) # Ellers kan elementet bare være tilstede # i høyre undergruppe else: return binært søk(arr, mid + 1, r, x ) annet: # Element er ikke til stede i array-return -1 # Driverkode arr = [ 2, 3, 4, 10, 40 ] x = 10 # Funksjonsanropsresultat = binært søk(arr, 0, len(arr)-1 , x) hvis resultat != -1: skriv ut ('Element er til stede ved indeks % d' % resultat) annet: skriv ut ('Element er ikke til stede i array') Produksjon
Element is present at index 3
Tidskompleksiteten til algoritmen ovenfor er O(log(n)).
For mer informasjon, se Binært søk .
Sorteringsalgoritmer
Utvalgssortering
De utvalg sortering algoritmen sorterer en matrise ved gjentatte ganger å finne minimumselementet (vurderer stigende rekkefølge) fra usortert del og sette det i begynnelsen. I hver iterasjon av utvalgssortering, plukkes minimumselementet (med tanke på stigende rekkefølge) fra den usorterte undergruppen og flyttes til den sorterte undergruppen.
Flytskjema for utvalgssortering:
# Python program for implementation of Selection # Sort import sys A = [64, 25, 12, 22, 11] # Traverse through all array elements for i in range(len(A)): # Find the minimum element in remaining # unsorted array min_idx = i for j in range(i+1, len(A)): if A[min_idx]>A[j]: min_idx = j # Bytt minimumselementet som ble funnet med # det første elementet A[i], A[min_idx] = A[min_idx], A[i] # Driverkode for å teste over utskriften ('Sortert array ') for i i området(len(A)): print('%d' %A[i]), Produksjon
Sorted array 11 12 22 25 64
Tidskompleksitet: På 2 ) siden det er to nestede løkker.
Hjelpeplass: O(1)
Boblesortering
Boblesortering er den enkleste sorteringsalgoritmen som fungerer ved gjentatte ganger å bytte de tilstøtende elementene hvis de er i feil rekkefølge.
Illustrasjon:

# Python program for implementation of Bubble Sort def bubbleSort(arr): n = len(arr) # Traverse through all array elements for i in range(n): # Last i elements are already in place for j in range(0, n-i-1): # traverse the array from 0 to n-i-1 # Swap if the element found is greater # than the next element if arr[j]>arr[j+1] : arr[j], arr[j+1] = arr[j+1], arr[j] # Driverkode for å teste over arr = [64, 34, 25, 12, 22, 11 , 90] bubbleSort(arr) print ('Sortert array er:') for i in range(len(arr)): print ('%d' %arr[i]), Produksjon
Sorted array is: 11 12 22 25 34 64 90
Tidskompleksitet: På 2 )
Innsettingssortering
For å sortere en matrise med størrelse n i stigende rekkefølge ved å bruke innsettingssortering :
- Iterer fra arr[1] til arr[n] over matrisen.
- Sammenlign gjeldende element (nøkkel) med forgjengeren.
- Hvis nøkkelelementet er mindre enn forgjengeren, kan du sammenligne det med elementene før. Flytt de større elementene en posisjon opp for å gjøre plass til det byttet element.
Illustrasjon:

# Python program for implementation of Insertion Sort # Function to do insertion sort def insertionSort(arr): # Traverse through 1 to len(arr) for i in range(1, len(arr)): key = arr[i] # Move elements of arr[0..i-1], that are # greater than key, to one position ahead # of their current position j = i-1 while j>= 0 og tast < arr[j] : arr[j + 1] = arr[j] j -= 1 arr[j + 1] = key # Driver code to test above arr = [12, 11, 13, 5, 6] insertionSort(arr) for i in range(len(arr)): print ('% d' % arr[i]) Produksjon
5 6 11 12 13
Tidskompleksitet: På 2 ))
Slå sammen sortering
Som QuickSort, Slå sammen sortering er en Divide and Conquer-algoritme. Den deler inndatamatrisen i to halvdeler, kaller seg selv for de to halvdelene og slår deretter sammen de to sorterte halvdelene. Merge()-funksjonen brukes til å slå sammen to halvdeler. Sammenslåingen (arr, l, m, r) er en nøkkelprosess som forutsetter at arr[l..m] og arr[m+1..r] er sortert og slår sammen de to sorterte sub-arrayene til én.
MergeSort(arr[], l, r) If r>l 1. Finn midtpunktet for å dele matrisen i to halvdeler: midterste m = l+ (r-l)/2 2. Ring mergeSort for første halvdel: Call mergeSort(arr, l, m) 3. Call mergeSort for andre halvdel: Call mergeSort(arr, m+1, r) 4. Slå sammen de to halvdelene sortert i trinn 2 og 3: Ring merge(arr, l, m, r)
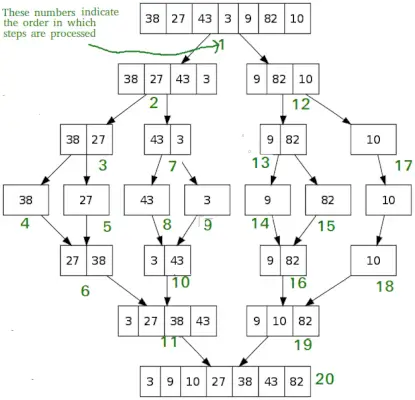
# Python program for implementation of MergeSort def mergeSort(arr): if len(arr)>1: # Finne midten av arrayen mid = len(arr)//2 # Dele array-elementene L = arr[:mid] # i 2 halvdeler R = arr[midt:] # Sortering av første halvdel mergeSort(L) # Sortering av andre halvdel mergeSort(R) i = j = k = 0 # Kopier data til midlertidige arrays L[] og R[] mens i < len(L) and j < len(R): if L[i] < R[j]: arr[k] = L[i] i += 1 else: arr[k] = R[j] j += 1 k += 1 # Checking if any element was left while i < len(L): arr[k] = L[i] i += 1 k += 1 while j < len(R): arr[k] = R[j] j += 1 k += 1 # Code to print the list def printList(arr): for i in range(len(arr)): print(arr[i], end=' ') print() # Driver Code if __name__ == '__main__': arr = [12, 11, 13, 5, 6, 7] print('Given array is', end='
') printList(arr) mergeSort(arr) print('Sorted array is: ', end='
') printList(arr) Produksjon
Given array is 12 11 13 5 6 7 Sorted array is: 5 6 7 11 12 13
Tidskompleksitet: O(n(logg))
QuickSort
Som Merge Sort, QuickSort er en Divide and Conquer-algoritme. Den velger et element som pivot og deler den gitte matrisen rundt den valgte pivoten. Det er mange forskjellige versjoner av quickSort som velger pivot på forskjellige måter.
Velg alltid første element som pivot.
- Velg alltid siste element som pivot (implementert nedenfor)
- Velg et tilfeldig element som pivot.
- Velg median som pivot.
Nøkkelprosessen i quickSort er partisjon(). Målet for partisjoner er, gitt en array og et element x av array som pivot, å sette x i riktig posisjon i sortert array og sette alle mindre elementer (mindre enn x) før x, og sette alle større elementer (større enn x) etter x. Alt dette bør gjøres i lineær tid.
/* low -->Startindeks, høy --> Sluttindeks */ quickSort(arr[], lav, høy) { if (low { /* pi er partisjoneringsindeks, arr[pi] er nå på riktig sted */ pi = partisjon(arr, low, high); quickSort(arr, low, pi - 1); // Before pi quickSort(arr, pi + 1, high } } 
Partisjonsalgoritme
Det kan være mange måter å gjøre partisjon på, følgende pseudokode bruker metoden gitt i CLRS bok. Logikken er enkel, vi starter fra elementet lengst til venstre og holder styr på indeksen til mindre (eller lik) elementer som jeg. Mens vi krysser, hvis vi finner et mindre element, bytter vi nåværende element med arr[i]. Ellers ignorerer vi gjeldende element.
/* This function takes last element as pivot, places the pivot element at its correct position in sorted array, and places all smaller (smaller than pivot) to left of pivot and all greater elements to right of pivot */ partition (arr[], low, high) { // pivot (Element to be placed at right position) pivot = arr[high]; i = (low – 1) // Index of smaller element and indicates the // right position of pivot found so far for (j = low; j <= high- 1; j++){ // If current element is smaller than the pivot if (arr[j] i++; // increment index of smaller element swap arr[i] and arr[j] } } swap arr[i + 1] and arr[high]) return (i + 1) } Python3 # Python3 implementation of QuickSort # This Function handles sorting part of quick sort # start and end points to first and last element of # an array respectively def partition(start, end, array): # Initializing pivot's index to start pivot_index = start pivot = array[pivot_index] # This loop runs till start pointer crosses # end pointer, and when it does we swap the # pivot with element on end pointer while start < end: # Increment the start pointer till it finds an # element greater than pivot while start < len(array) and array[start] <= pivot: start += 1 # Decrement the end pointer till it finds an # element less than pivot while array[end]>pivot: end -= 1 # Hvis start og slutt ikke har krysset hverandre, # bytt tallene på start og slutt if(start < end): array[start], array[end] = array[end], array[start] # Swap pivot element with element on end pointer. # This puts pivot on its correct sorted place. array[end], array[pivot_index] = array[pivot_index], array[end] # Returning end pointer to divide the array into 2 return end # The main function that implements QuickSort def quick_sort(start, end, array): if (start < end): # p is partitioning index, array[p] # is at right place p = partition(start, end, array) # Sort elements before partition # and after partition quick_sort(start, p - 1, array) quick_sort(p + 1, end, array) # Driver code array = [ 10, 7, 8, 9, 1, 5 ] quick_sort(0, len(array) - 1, array) print(f'Sorted array: {array}') Produksjon
Sorted array: [1, 5, 7, 8, 9, 10]
Tidskompleksitet: O(n(logg))
ShellSort
ShellSort er hovedsakelig en variant av Insertion Sort. Ved innsettingssortering flytter vi elementer bare én posisjon foran. Når et element skal flyttes langt frem, er mange bevegelser involvert. Ideen med shellSort er å tillate utveksling av fjerne gjenstander. I shellSort gjør vi matrisen h-sortert for en stor verdi på h. Vi fortsetter å redusere verdien av h til den blir 1. En matrise sies å være h-sortert hvis alle underlister av hver h th elementet er sortert.
Python3 # Python3 program for implementation of Shell Sort def shellSort(arr): gap = len(arr) // 2 # initialize the gap while gap>0: i = 0 j = gap # sjekk matrisen inn fra venstre til høyre # til siste mulige indeks av j mens j < len(arr): if arr[i]>arr[j]: arr[i],arr[j] = arr[j],arr[i] i += 1 j += 1 # nå ser vi tilbake fra ith indeksen til venstre # vi bytter ut verdiene som er ikke i riktig rekkefølge. k = i mens k - gap> -1: hvis arr[k - gap]> arr[k]: arr[k-gap],arr[k] = arr[k],arr[k-gap] k -= 1 gap //= 2 # driver for å sjekke koden arr2 = [12, 34, 54, 2, 3] print('input array:',arr2) shellSort(arr2) print('sorted array', arr2) Produksjon
input array: [12, 34, 54, 2, 3] sorted array [2, 3, 12, 34, 54]
Tidskompleksitet: På 2 ).