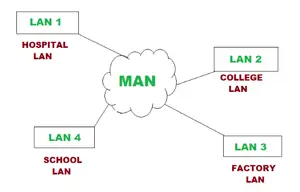
Pitone | Pandas.pivot()
pandas.pivot(indice, colonne, valori) la funzione produce una tabella pivot basata su 3 colonne del DataFrame. Utilizza valori univoci dall'indice/colonne e li riempie con valori.
Sintassi Python Pandas.pivot()
Sintassi : pandas.pivot(indice, colonne, valori)
parametri:
- indice[ndarray] : Etichette da utilizzare per creare l'indice del nuovo frame
- colonne[ndarray]: Etichette da utilizzare per creare le colonne della nuova cornice
- valori[ndarray]: Valori da utilizzare per popolare i valori del nuovo frame
Ritorna: DataFrame rimodellato
Eccezione: ValueError sollevato se sono presenti duplicati.
Creazione di un DataFrame di esempio
Qui stiamo creando un DataFrame di esempio che utilizzeremo nel nostro articolo.
Python3
# importing pandas as pd> import> pandas as pd> > # creating a dataframe> df> => pd.DataFrame({> 'A'> : [> 'John'> ,> 'Boby'> ,> 'Mina'> ],> > 'B'> : [> 'Masters'> ,> 'Graduate'> ,> 'Graduate'> ],> > 'C'> : [> 27> ,> 23> ,> 21> ]})> > df> |
Produzione
A B C 0 John Masters 27 1 Boby Graduate 23 2 Mina Graduate 21
Esempi di funzioni Pandas pivot()
Di seguito sono riportati alcuni esempi in base ai quali possiamo ruotare un DataFrame utilizzando Panda funzione pivot() in Pitone :
- Creare e Ruota un DataFrame
- Creazione di una tabella pivot multilivello con Panda DataFrame
- ValueError nel pivot di un DataFrame
Creare e Ruota un DataFrame
In questo esempio, un DataFrame panda ( df> ) viene ruotato con le colonne 'A' e 'B' che diventano rispettivamente il nuovo indice e le colonne e i valori nella colonna 'C' popolano le celle della tabella pivot risultante. La funzione presuppone che ciascuna combinazione di 'A' e 'B' abbia un valore corrispondente univoco in 'C'.
Python3
# values can be an object or a list> df.pivot(> 'A'> ,> 'B'> ,> 'C'> )> |
Produzione
B Graduate Masters A Boby 23.0 NaN John NaN 27.0 Mina 21.0 NaN
Creazione di una tabella pivot multilivello con Pandas DataFrame
In questo esempio, il DataFrame dei panda ( df> ) viene trasformato in una tabella pivot multilivello, utilizzando 'A' come indice, 'B' come colonne ed estraendo valori da entrambe le colonne 'C' e 'A' per riempire le celle. Questo approccio consente una rappresentazione più dettagliata dei dati, incorporando più dimensioni nella tabella pivot risultante.
Python3
# value is a list> df.pivot(index> => 'A'> , columns> => 'B'> , values> => [> 'C'> ,> 'A'> ])> |
Produzione
C A B Graduate Masters Graduate Masters A Boby 23.0 NaN NaN NaN John NaN 27.0 NaN NaN Mina 21.0 NaN NaN NaN
ValueError sollevato durante il pivoting di un DataFrame
Aumenta ValueError quando sono presenti indici e combinazioni di colonne con più valori.
Python3
# importing pandas as pd> import> pandas as pd> > # creating a dataframe> df> => pd.DataFrame({> 'A'> : [> 'John'> ,> 'John'> ,> 'Mina'> ],> > 'B'> : [> 'Masters'> ,> 'Masters'> ,> 'Graduate'> ],> > 'C'> : [> 27> ,> 23> ,> 21> ]})> > > df.pivot(> 'A'> ,> 'B'> ,> 'C'> )> |
Produzione
ValueError: Index contains duplicate entries, cannot reshape


![Le 10 città più grandi degli Stati Uniti in base alla popolazione classificata [Elenco aggiornato 2024]](https://techcodeview.com/img/us-gk/09/top-10-largest-cities-united-states-population-ranked.webp)