comando grep in Unix/Linux

IL grep> Il comando in Unix/Linux è un potente strumento utilizzato per cercare e manipolare modelli di testo all'interno dei file. Il suo nome deriva dal comando ed (editor) g/re/p (ricerca globale di un'espressione regolare e stampa delle righe corrispondenti), che riflette la sua funzionalità principale. grep> è ampiamente utilizzato da programmatori, amministratori di sistema e utenti per la sua efficienza e versatilità nella gestione dei dati di testo. In questo articolo esploreremo i vari aspetti del grep> comando.
Tabella dei contenuti
- Sintassi del comando grep in Unix/Linux
- Opzioni disponibili nel comando grep
- Esempio pratico del comando grep in Linux
- 1. Ricerca senza distinzione tra maiuscole e minuscole
- 2. Visualizzazione del conteggio del numero di corrispondenze utilizzando grep
- 3. Visualizza i nomi dei file che corrispondono al modello utilizzando grep
- 4. Controllo delle parole intere in un file utilizzando grep
- 5. Visualizzazione solo del modello corrispondente Utilizzando grep
- 6. Mostra il numero di riga durante la visualizzazione dell'output utilizzando grep -n
- 7. Invertire il pattern match usando grep
- 8. Corrispondenza delle righe che iniziano con una stringa utilizzando grep
- 9. Corrispondenza delle righe che terminano con una stringa utilizzando grep
- 10.Specifica l'espressione con l'opzione -e
- 11. Opzione -f file Prende i pattern dal file, uno per riga
- 12. Stampa n righe specifiche da un file utilizzando grep
- 13. Cerca ricorsivamente un modello nella directory
Sintassi del comando grep in Unix/Linux
La sintassi di base del file ` grep`> il comando è il seguente:
grep [options] pattern [files]
Qui,
[> options> ]> : Questi sono flag della riga di comando che modificano il comportamento di grep> .
[> pattern> ]> : questa è l'espressione regolare che vuoi cercare.
[> file> ]> : Questo è il nome dei file in cui vuoi cercare. È possibile specificare più file per la ricerca simultanea.
Opzioni disponibili nel comando grep
| Opzioni | Descrizione |
|---|---|
| -C | Questo stampa solo il conteggio delle linee che corrispondono a un modello |
| -H | Visualizza le righe corrispondenti, ma non visualizza i nomi dei file. |
| – io | Ignora, caso per corrispondenza |
| -l | Visualizza solo l'elenco dei nomi di file. |
| -N | Visualizza le righe corrispondenti e i relativi numeri di riga. |
| -In | Questo stampa tutte le linee che non corrispondono al modello |
| -e esp | Specifica l'espressione con questa opzione. Può essere utilizzato più volte. |
| -ffile | Prende i modelli dal file, uno per riga. |
| -E | Tratta il modello come un'espressione regolare estesa (ERE) |
| -In | Abbina la parola intera |
| -O | Stampa solo le parti corrispondenti di una riga corrispondente, con ciascuna parte su una riga di output separata. |
| -UN | Stampa la riga e le nrighe cercate dopo il risultato. |
| -Bn | Stampa la riga cercata en riga prima del risultato. |
| -C n | Stampa la riga cercata e n righe prima del risultato. |
Comandi di esempio
Considera il file seguente come input.
cat>geekfile.txt>
Unix è un ottimo sistema operativo. unix è stato sviluppato nei laboratori Bell.
imparare il sistema operativo.
Unix Linux quale scegli.
uNix è facile da imparare.unix è un sistema operativo multiutente. Impara unix .unix è un sistema potente.
Esempio pratico del comando grep in Linux
1. Ricerca senza distinzione tra maiuscole e minuscole
L'opzione -i consente di cercare una stringa maiuscole e minuscole in modo insensibile nel file specificato. Corrisponde a parole come UNIX, Unix, unix.
grep -i 'UNix' geekfile.txt
Produzione:

Ricerca senza distinzione tra maiuscole e minuscole
2. Visualizzazione del conteggio del numero di corrispondenze utilizzando grep
Possiamo trovare il numero di righe che corrispondono alla stringa/modello specificato
grep -c 'unix' geekfile.txt
Produzione:

Visualizzazione del conteggio delle corrispondenze
3. Visualizza i nomi dei file che corrispondono al modello utilizzando grep
Possiamo semplicemente visualizzare i file che contengono la stringa/modello specificato.
grep -l 'unix' *
O
grep -l 'unix' f1.txt f2.txt f3.xt f4.txt
Produzione:

Il nome del file che corrisponde al modello
4. Controllo delle parole intere in un file utilizzando grep
Per impostazione predefinita, grep corrisponde alla stringa/modello specificato anche se viene trovato come sottostringa in un file. L'opzione -w di grep fa sì che corrisponda solo alle parole intere.
grep -w 'unix' geekfile.txt
Produzione:

controllare intere parole in un file
5. Visualizzazione solo del modello corrispondente Utilizzando grep
Per impostazione predefinita, grep visualizza l'intera riga che contiene la stringa corrispondente. Possiamo fare in modo che grep visualizzi solo la stringa corrispondente utilizzando l'opzione -o.
grep -o 'unix' geekfile.txt
Produzione:
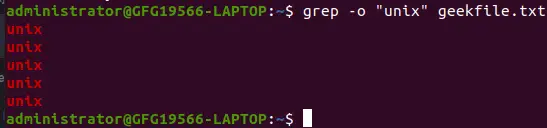
Visualizza solo il modello corrispondente
6. Mostra il numero di riga durante la visualizzazione dell'output utilizzando grep -n
Per mostrare il numero di riga del file con la riga corrispondente.
grep -n 'unix' geekfile.txt
Produzione:

Mostra il numero di riga durante la visualizzazione dell'output
7. Invertire il pattern match usando grep
È possibile visualizzare le righe che non corrispondono al modello di stringa di ricerca specificato utilizzando l'opzione -v.
grep -v 'unix' geekfile.txt
Produzione:

Inversione della corrispondenza del modello
8. Corrispondenza delle righe che iniziano con una stringa utilizzando grep
Il modello di espressione regolare ^ specifica l'inizio di una riga. Questo può essere usato in grep per abbinare le linee che iniziano con la stringa o il modello specificato.
grep '^unix' geekfile.txt
Produzione:

Corrispondenza delle righe che iniziano con una stringa
9. Corrispondenza delle righe che terminano con una stringa utilizzando grep
Il modello di espressione regolare $ specifica la fine di una riga. Questo può essere usato in grep per abbinare le linee che terminano con la stringa o il modello specificato.
grep 'os$' geekfile.txt
10.Specifica l'espressione con l'opzione -e
Può essere utilizzato più volte:
grep –e 'Agarwal' –e 'Aggarwal' –e 'Agrawal' geekfile.txt
11. Opzione -f file Prende i pattern dal file, uno per riga
cat pattern.txt
Agarwal
Aggarwal
Agrawal
grep –f pattern.txt geekfile.txt
12. Stampa n righe specifiche da un file utilizzando grep
-A stampa la riga cercata e n righe dopo il risultato, -B stampa la riga cercata e n righe prima del risultato e -C stampa la riga cercata e n righe prima e dopo il risultato.
Sintassi:
grep -A[NumberOfLines(n)] [search] [file] grep -B[NumberOfLines(n)] [search] [file] grep -C[NumberOfLines(n)] [search] [file]
Esempio:
grep -A1 learn geekfile.txt
Produzione:

Stampa n righe specifiche da un file
13. Cerca ricorsivamente un pattern nel file D directory
-R stampa ricorsivamente in tutti i file il modello cercato nella directory specificata.
Sintassi:
grep -R [Search] [directory]
Esempio :
grep -iR geeks /home/geeks
Produzione:
./geeks2.txt:Well Hello Geeks ./geeks1.txt:I am a big time geek ---------------------------------- -i to search for a string case insensitively -R to recursively check all the files in the directory.
Conclusione
In questo articolo abbiamo discusso di grep> comando in Linux che è un potente strumento di ricerca di testo che utilizza espressioni regolari per trovare modelli o testo all'interno dei file. Offre varie opzioni come la distinzione tra maiuscole e minuscole, il conteggio delle corrispondenze e l'elenco dei nomi dei file. Con la possibilità di effettuare ricerche ricorsive, utilizzare flag di espressioni regolari e personalizzare l'output, grep> è uno strumento vitale per gli utenti Linux per gestire in modo efficiente le attività relative al testo. Masterizzazione grep> migliora la tua capacità di lavorare con dati di testo nell'ambiente Linux.