Rad s PDF datotekama u Pythonu

Svi morate biti upoznati s time što su PDF-ovi. Zapravo, oni su jedan od najvažnijih i najčešće korištenih digitalnih medija. PDF je skraćenica za Prijenosni format dokumenta . Koristi se .pdf proširenje. Koristi se za predstavljanje i razmjenu dokumenata pouzdano neovisno o softverskom hardveru ili operativnom sustavu.
Izumio Adobe PDF je sada otvoreni standard koji održava Međunarodna organizacija za standardizaciju (ISO). PDF-ovi mogu sadržavati poveznice i gumbe iz polja audio, video i poslovne logike.
U ovom ćemo članku naučiti kako možemo izvoditi razne operacije poput:
- Izdvajanje teksta iz PDF-a
- Rotiranje PDF stranica
- Spajanje PDF-ova
- Razdvajanje PDF-a
- Dodavanje vodenog žiga na PDF stranice
Montaža: Korištenje jednostavnih python skripti!
Koristit ćemo modul treće strane pypdf.
pypdf je python biblioteka izgrađena kao PDF alat. Sposoban je za:
- Izdvajanje informacija o dokumentu (autor naslova...)
- Dijeljenje dokumenata stranicu po stranicu
- Spajanje dokumenata stranicu po stranicu
- Izrezivanje stranica
- Spajanje više stranica u jednu stranicu
- Šifriranje i dešifriranje PDF datoteka
- i više!
Da biste instalirali pypdf, pokrenite sljedeću naredbu iz naredbenog retka:
pip install pypdfOvaj naziv modula razlikuje velika i mala slova pa provjerite je li i je mala slova, a sve ostalo je veliko. Svi kodovi i PDF datoteke korištene u ovom vodiču/članku su dostupni ovdje .
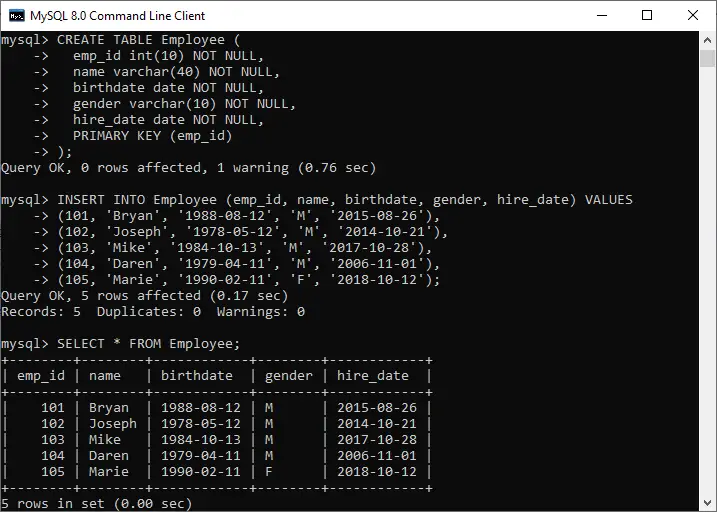
1. Izdvajanje teksta iz PDF datoteke
PythonIzlaz gornjeg programa izgleda ovako:
20
PythonBasics
S.R.Doty
August272008
Contents
1Preliminaries
4
1.1WhatisPython?...................................
..4
1.2Installationanddocumentation....................
.........4 [and some more lines...]
Pokušajmo razumjeti gornji kod u dijelovima:
reader = PdfReader('example.pdf')
- Ovdje stvaramo objekt od PdfReader klasa pypdf modula i proslijedite put do PDF datoteke i dobijete objekt PDF čitača.
print(len(reader.pages))
- stranice svojstvo daje broj stranica u PDF datoteci. Na primjer, u našem slučaju to je 20 (pogledajte prvi red ispisa).
pageObj = reader.pages[0]
- Sada stvaramo objekt od PageObject klasa pypdf modula. Objekt PDF čitača ima funkciju stranice[] koji uzima broj stranice (počevši od indeksa 0) kao argument i vraća objekt stranice.
print(pageObj.extract_text())
- Objekt stranice ima funkciju ekstrakt_teksta() za izdvajanje teksta s PDF stranice.
Bilješka: Iako su PDF datoteke izvrsne za postavljanje teksta na način koji je ljudima jednostavan za ispis i čitanje, softver ih ne može jednostavno raščlaniti u čisti tekst. Kao takav, pypdf bi mogao pogriješiti prilikom izdvajanja teksta iz PDF-a i možda čak uopće neće moći otvoriti neke PDF-ove. Nažalost, ne možete puno učiniti u vezi s tim. pypdf možda jednostavno ne može raditi s nekim od vaših PDF datoteka.
2. Rotiranje PDF stranica
# importing the required classes from pypdf import PdfReader PdfWriter def PDFrotate ( origFileName newFileName rotation ): # creating a pdf Reader object reader = PdfReader ( origFileName ) # creating a pdf writer object for new pdf writer = PdfWriter () # rotating each page for page in range ( len ( reader . pages )): pageObj = reader . pages [ page ] pageObj . rotate ( rotation ) # Add the rotated page object to the PDF writer writer . add_page ( pageObj ) # Write the rotated pages to the new PDF file with open ( newFileName 'wb' ) as newFile : writer . write ( newFile ) def main (): # original pdf file name origFileName = 'example.pdf' # new pdf file name newFileName = 'rotated_example.pdf' # rotation angle rotation = 270 # calling the PDFrotate function PDFrotate ( origFileName newFileName rotation ) if __name__ == '__main__' : # calling the main function main ()
Ovdje možete vidjeti kako izgleda prva stranica rotirani_primjer.pdf izgleda ovako (desna slika) nakon rotacije:

Neke važne točke povezane s gornjim kodom:
- Za rotaciju prvo stvaramo objekt PDF čitača izvornog PDF-a.
writer = PdfWriter()
- Zakrenute stranice bit će zapisane u novi PDF. Za pisanje u PDF-ove koristimo objekt of PdfWriter klasa pypdf modula.
for page in range(len(pdfReader.pages)):
pageObj = pdfReader.pages[page]
pageObj.rotate(rotation)
writer.add_page(pageObj)
- Sada ponavljamo svaku stranicu izvornog PDF-a. Dobivamo objekt stranice putem .stranice[] metoda PDF reader klase. Sada okrećemo stranicu za rotirati() metoda klase objekta stranice. Zatim dodajemo stranicu objektu PDF pisca pomoću dodati() metoda klase PDF writer prosljeđivanjem objekta rotirane stranice.
newFile = open(newFileName 'wb')
writer.write(newFile)
newFile.close()
- Sada moramo napisati PDF stranice u novu PDF datoteku. Prvo otvorimo novi objekt datoteke i u njega upišemo PDF stranice koristeći pisati() metoda objekta PDF pisca. Na kraju zatvaramo izvorni objekt PDF datoteke i novi objekt datoteke.
3. Spajanje PDF datoteka
Python # importing required modules from pypdf import PdfWriter def PDFmerge ( pdfs output ): # creating pdf file writer object pdfWriter = PdfWriter () # appending pdfs one by one for pdf in pdfs : pdfWriter . append ( pdf ) # writing combined pdf to output pdf file with open ( output 'wb' ) as f : pdfWriter . write ( f ) def main (): # pdf files to merge pdfs = [ 'example.pdf' 'rotated_example.pdf' ] # output pdf file name output = 'combined_example.pdf' # calling pdf merge function PDFmerge ( pdfs = pdfs output = output ) if __name__ == '__main__' : # calling the main function main ()
Izlaz gornjeg programa je kombinirani PDF kombinirani_primjer.pdf dobiveni spajanjem primjer.pdf i rotirani_primjer.pdf .
- Pogledajmo važne aspekte ovog programa:
pdfWriter = PdfWriter() - Za spajanje koristimo unaprijed izgrađenu klasu PdfWriter pypdf modula.
Ovdje stvaramo objekt pdfwriter razreda PDF pisca
# appending pdfs one by one
for pdf in pdfs:
pdfWriter.append(pdf)
- Sada dodajemo objekt datoteke svakog PDF-a u objekt PDF pisača pomoću dodati() metoda.
# writing combined pdf to output pdf file
with open(output 'wb') as f:
pdfWriter.write(f)
- Na kraju pišemo PDF stranice u izlaznu PDF datoteku pomoću pisati metoda objekta PDF pisca.
4. Razdvajanje PDF datoteke
Python # importing the required modules from pypdf import PdfReader PdfWriter def PDFsplit ( pdf splits ): # creating pdf reader object reader = PdfReader ( pdf ) # starting index of first slice start = 0 # starting index of last slice end = splits [ 0 ] for i in range ( len ( splits ) + 1 ): # creating pdf writer object for (i+1)th split writer = PdfWriter () # output pdf file name outputpdf = pdf . split ( '.pdf' )[ 0 ] + str ( i ) + '.pdf' # adding pages to pdf writer object for page in range ( start end ): writer . add_page ( reader . pages [ page ]) # writing split pdf pages to pdf file with open ( outputpdf 'wb' ) as f : writer . write ( f ) # interchanging page split start position for next split start = end try : # setting split end position for next split end = splits [ i + 1 ] except IndexError : # setting split end position for last split end = len ( reader . pages ) def main (): # pdf file to split pdf = 'example.pdf' # split page positions splits = [ 2 4 ] # calling PDFsplit function to split pdf PDFsplit ( pdf splits ) if __name__ == '__main__' : # calling the main function main ()
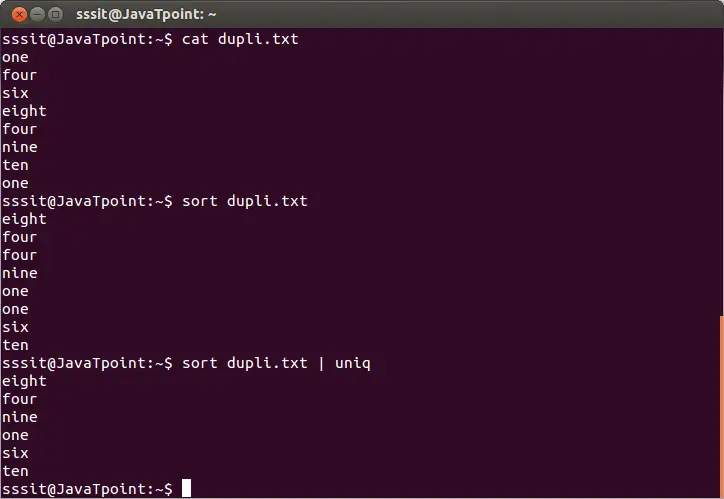
Izlaz će biti tri nove PDF datoteke sa dio 1 (stranica 01) dio 2 (stranica 23) dio 3 (stranica 4-kraj) .
U gornjem python programu nije korištena nikakva nova funkcija ili klasa. Koristeći jednostavnu logiku i iteracije stvorili smo podjele položenog PDF-a prema popisu položenog rascjepi .
5. Dodavanje vodenog žiga na PDF stranice
Python # importing the required modules from pypdf import PdfReader PdfWriter def add_watermark ( wmFile pageObj ): # creating pdf reader object of watermark pdf file reader = PdfReader ( wmFile ) # merging watermark pdf's first page with passed page object. pageObj . merge_page ( reader . pages [ 0 ]) # returning watermarked page object return pageObj def main (): # watermark pdf file name mywatermark = 'watermark.pdf' # original pdf file name origFileName = 'example.pdf' # new pdf file name newFileName = 'watermarked_example.pdf' # creating pdf File object of original pdf pdfFileObj = open ( origFileName 'rb' ) # creating a pdf Reader object reader = PdfReader ( pdfFileObj ) # creating a pdf writer object for new pdf writer = PdfWriter () # adding watermark to each page for page in range ( len ( reader . pages )): # creating watermarked page object wmpageObj = add_watermark ( mywatermark reader . pages [ page ]) # adding watermarked page object to pdf writer writer . add_page ( wmpageObj ) # writing watermarked pages to new file with open ( newFileName 'wb' ) as newFile : writer . write ( newFile ) # closing the original pdf file object pdfFileObj . close () if __name__ == '__main__' : # calling the main function main ()
Evo kako izgleda prva stranica originalne (lijevo) i PDF datoteke s vodenim žigom (desno):

- Cijeli postupak je isti kao u primjeru rotacije stranice. Jedina razlika je:
wmpageObj = add_watermark(mywatermark pdfReader.pages[page])
- Objekt stranice pretvara se u objekt stranice s vodenim žigom pomoću dodaj_vodeni žig() funkcija.
- Pokušajmo razumjeti dodaj_vodeni žig() funkcija:
reader = PdfReader(wmFile)
pageObj.merge_page(reader.pages[0])
return pageObj
- Najprije stvaramo objekt PDF čitača vodeni žig.pdf . Objektu proslijeđene stranice koji koristimo merge_page() funkciju i proslijedi objekt stranice prve stranice objekta PDF čitača vodenog žiga. Ovo će prekriti vodeni žig preko objekta stranice koji je prošao.
I ovdje smo došli do kraja ovog dugog vodiča o radu s PDF datotekama u pythonu.
Sada možete jednostavno izraditi vlastiti PDF upravitelj!
Reference:
- https://automatetheboringstuff.com/chapter13/
- https://pypi.org/project/pypdf/
Ako vam se sviđa GeeksforGeeks i želite doprinijeti, možete napisati članak koristeći write.geeksforgeeks.org ili svoj članak poslati poštom na [email protected]. Pogledajte kako se vaš članak pojavljuje na glavnoj stranici GeeksforGeeksa i pomozite drugim Geekovima.
Napišite komentare ako pronađete bilo što netočno ili ako želite podijeliti više informacija o temi koja je gore razmotrena.