Læsning af valgt websideindhold ved hjælp af Python Web Scraping
Forudsætning: Download af filer i Python Webskrabning med BeautifulSoup Vi ved alle, at Python er et meget nemt programmeringssprog, men det, der gør det cool, er det store antal open source-biblioteker, der er skrevet til det. Requests er et af de mest udbredte biblioteker. Det giver os mulighed for at åbne ethvert HTTP/HTTPS-websted og lade os gøre enhver form for ting, vi normalt gør på nettet, og kan også gemme sessioner, f.eks. cookie. Som vi alle ved, er en webside blot et stykke HTML-kode, som sendes af webserveren til vores browser, som igen konverteres til den smukke side. Nu har vi brug for en mekanisme til at få fat i HTML-kildekoden, dvs. finde nogle bestemte tags med en pakke kaldet BeautifulSoup. Installation:
pip3 install requests
pip3 install beautifulsoup4
Vi tager et eksempel ved at læse en nyhedsside Hindustan Times
Koden kan opdeles i tre dele.- Anmodning om en webside
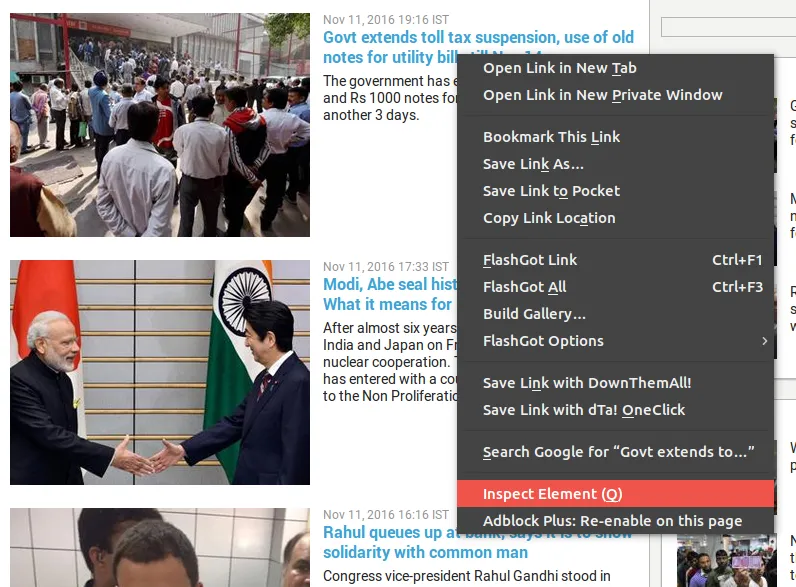
- Inspicering af tags
- Udskriv det relevante indhold

 Bemærk Nyhedsteksten er til stede i ankertagtekstdelen. En nøje observation giver os den idé, at alle nyheder er i li-liste-tags af det uordnede tag.
Bemærk Nyhedsteksten er til stede i ankertagtekstdelen. En nøje observation giver os den idé, at alle nyheder er i li-liste-tags af det uordnede tag. 
import requests from bs4 import BeautifulSoup def news (): # the target we want to open url = 'http://www.hindustantimes.com/top-news' #open with GET method resp = requests . get ( url ) #http_respone 200 means OK status if resp . status_code == 200 : print ( 'Successfully opened the web page' ) print ( 'The news are as follow :- n ' ) # we need a parserPython built-in HTML parser is enough . soup = BeautifulSoup ( resp . text 'html.parser' ) # l is the list which contains all the text i.e news l = soup . find ( 'ul' { 'class' : 'searchNews' }) #now we want to print only the text part of the anchor. #find all the elements of a i.e anchor for i in l . findAll ( 'a' ): print ( i . text ) else : print ( 'Error' ) news ()
Produktion
Successfully opened the web page The news are as follow :- Govt extends toll tax suspension use of old notes for utility bills extended till Nov 14 Modi Abe seal historic civil nuclear pact: What it means for India Rahul queues up at bank says it is to show solidarity with common man IS kills over 60 in Mosul victims dressed in orange and marked 'traitors' Rock On 2 review: Farhan Akhtar Arjun Rampal's band hasn't lost its magic Rumours of shortage in salt supply spark panic among consumers in UP Worrying truth: India ranks first in pneumonia diarrhoea deaths among kids To hell with romance here's why being single is the coolest way to be India vs England: Cheteshwar Pujara Murali Vijay make merry with tons in Rajkot Akshay-Bhumi SRK-Alia Ajay-Parineeti: Age difference doesn't matter anymore Currency ban: Only one-third have bank access; NE backward regions worst hit Nepal's central bank halts transactions with Rs 500 Rs 1000 Indian notes Political upheaval in Punjab after SC tells it to share Sutlej water Let's not kid ourselves with Trump what we have seen is what we will get Want to colour your hair? Try rose gold the hottest hair trend this winter
Referencer
Opret quizDu Kan Måske Lide

Top Artikler