Způsoby, jak filtrovat Pandas DataFrame podle hodnot sloupců

Filtrování Pandas DataFrame pomocí hodnot sloupců je běžnou operací při běhu s informacemi v Pythonu. K tomu můžete použít různé metody a techniky. Zde je mnoho způsobů, jak odfiltrovat Pandas DataFrame prostřednictvím hodnot sloupců.
V tomto příspěvku uvidíme různé způsoby, jak filtrovat Pandas Dataframe podle hodnot sloupců. Nejprve vytvoříme datový rámec:
Python3
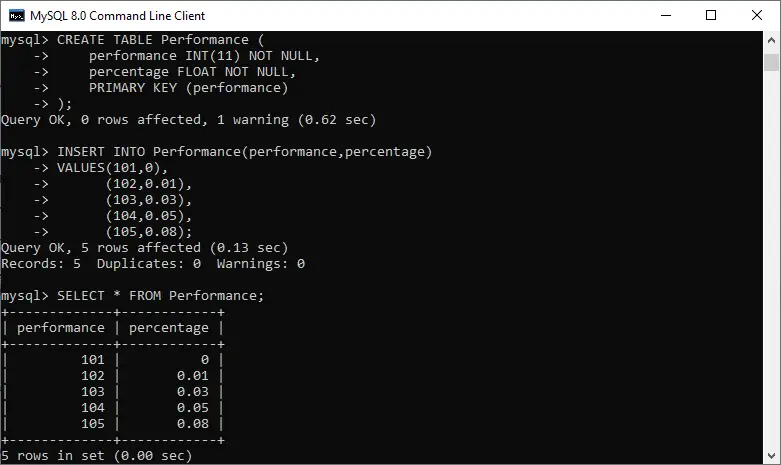
# importing pandas> import> pandas as pd> > # declare a dictionary> record> => {> > 'Name'> : [> 'Ankit'> ,> 'Swapnil'> ,> 'Aishwarya'> ,> > 'Priyanka'> ,> 'Shivangi'> ,> 'Shaurya'> ],> > > 'Age'> : [> 22> ,> 20> ,> 21> ,> 19> ,> 18> ,> 22> ],> > > 'Stream'> : [> 'Math'> ,> 'Commerce'> ,> 'Science'> ,> > 'Math'> ,> 'Math'> ,> 'Science'> ],> > > 'Percentage'> : [> 90> ,> 90> ,> 96> ,> 75> ,> 70> ,> 80> ] }> > # create a dataframe> dataframe> => pd.DataFrame(record,> > columns> => [> 'Name'> ,> 'Age'> ,> > 'Stream'> ,> 'Percentage'> ])> # show the Dataframe> print> (> 'Given Dataframe :
'> , dataframe)> |
Výstup:

Výběr řádků datového rámce Pandas na základě konkrétní hodnoty sloupce pomocí operátorů ‚>‘, ‚=‘, ‚=‘, ‚ <=‘, ‚!=‘.
Příklad 1: Výběr všech řádků z daného datového rámce, ve kterých je „Procento“ větší než 75 pomocí [ ] .
Python3
# selecting rows based on condition> rslt_df> => dataframe[dataframe[> 'Percentage'> ]>> 70> ]> > print> (> '
Result dataframe :
'> , rslt_df)> |
Výstup:

Příklad 2: Výběr všech řádků z daného datového rámce, ve kterých je „Procento“ větší než 70 pomocí místo [ ] .
Python3
# selecting rows based on condition> rslt_df> => dataframe.loc[dataframe[> 'Percentage'> ]>> 70> ]> > print> (> '
Result dataframe :
'> ,> > rslt_df)> |
Výstup:
Výběr těch řádků datového rámce Pandas, jejichž hodnota sloupce je přítomna v seznamu pomocí vy() metoda datového rámce.
Příklad 1: Výběr všech řádků z daného datového rámce, ve kterém je přítomen ‚Stream‘, v seznamu možností pomocí [ ] .
Python3
options> => [> 'Science'> ,> 'Commerce'> ]> > # selecting rows based on condition> rslt_df> => dataframe[dataframe[> 'Stream'> ].isin(options)]> > print> (> '
Result dataframe :
'> ,> > rslt_df)> |
Výstup:

Příklad 2: Výběr všech řádků z daného datového rámce, ve kterém je přítomen ‚Stream‘, v seznamu možností pomocí místo [ ] .
Krajta
options> => [> 'Science'> ,> 'Commerce'> ]> > # selecting rows based on condition> rslt_df> => dataframe.loc[dataframe[> 'Stream'> ].isin(options)]> > print> (> '
Result dataframe :
'> ,> > rslt_df)> |
Výstup:
Výběr řádků datového rámce Pandas na základě podmínek více sloupců pomocí operátoru „&“.
Příklad1: Výběrem všech řádků z daného datového rámce, ve kterém se ‚Věk‘ rovná 22 a ‚Stream‘ je přítomen v seznamu možností pomocí [ ] .
Python3
options> => [> 'Commerce'> ,> 'Science'> ]> > # selecting rows based on condition> rslt_df> => dataframe[(dataframe[> 'Age'> ]> => => 22> ) &> > dataframe[> 'Stream'> ].isin(options)]> > print> (> '
Result dataframe :
'> ,> > rslt_df)> |
Výstup:

Příklad 2: Výběrem všech řádků z daného datového rámce, ve kterém se ‚Věk‘ rovná 22 a ‚Stream‘ je přítomen v seznamu možností pomocí místo [ ] .
Python3
options> => [> 'Commerce'> ,> 'Science'> ]> > # selecting rows based on condition> rslt_df> => dataframe.loc[(dataframe[> 'Age'> ]> => => 22> ) &> > dataframe[> 'Stream'> ].isin(options)]> > print> (> '
Result dataframe :
'> ,> > rslt_df)> |
Výstup: