Huffman kódování Java

Huffmanův kódovací algoritmus navrhl David A. Huffman v roce 1950. Jedná se o a bezztrátovou kompresi dat mechanismus. Je také známý jako kódování komprese dat. Je široce používán v kompresi obrázků (JPEG nebo JPG). V této části budeme diskutovat o Huffmanovo kódování a dekódování, a také implementovat svůj algoritmus v programu Java.
Víme, že každý znak je posloupností 0 a 1 a ukládá se pomocí 8 bitů. Mechanismus se nazývá kódování s pevnou délkou protože každý znak používá stejný počet pevného bitového úložiště.
Tady vyvstává otázka, je možné snížit množství místa potřebného k uložení postavy?
Ano, je to možné pomocí kódování s proměnnou délkou. V tomto mechanismu využíváme některé znaky, které se vyskytují častěji než jiné znaky. V této technice kódování můžeme reprezentovat stejný kus textu nebo řetězec snížením počtu bitů.
Huffmanovo kódování
Huffmanovo kódování implementuje následující kroky.
- Všem daným znakům přiřadí kód proměnné délky.
- Délka kódu znaku závisí na tom, jak často se vyskytuje v daném textu nebo řetězci.
- Znak dostane nejmenší kód, pokud se vyskytuje často.
- Znak získá největší kód, pokud se vyskytuje nejméně.
Huffmanovo kódování následuje a pravidlo předpony což zabraňuje nejednoznačnosti při dekódování. Pravidlo také zajišťuje, že kód přiřazený znaku není považován za předponu kódu přiřazeného jinému znaku.
Huffmanovo kódování zahrnuje následující dva hlavní kroky:
- Nejprve sestrojte a Huffmanův strom z daného vstupního řetězce nebo znaků nebo textu.
- Přiřaďte Huffmanův kód každé postavě přecházením přes strom.
Pojďme si stručně představit dva výše uvedené kroky.
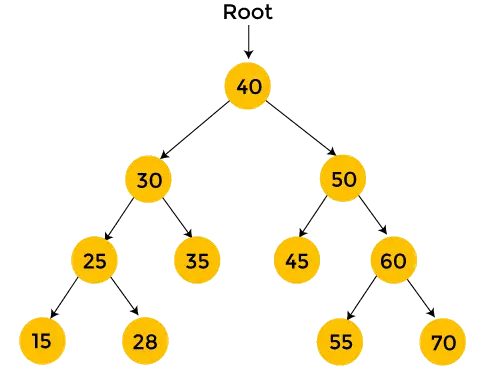
Huffmanův strom
Krok 1: Pro každý znak uzlu vytvořte listový uzel. Listový uzel znaku obsahuje frekvenci tohoto znaku.
Krok 2: Nastavte všechny uzly v seřazeném pořadí podle jejich frekvence.
Krok 3: Může existovat stav, kdy dva uzly mohou mít stejnou frekvenci. V takovém případě proveďte následující:
- Vytvořte nový vnitřní uzel.
- Frekvence uzlu bude součtem frekvence těchto dvou uzlů, které mají stejnou frekvenci.
- Označte první uzel jako levý potomek a další uzel jako pravý potomek nově vytvořeného interního uzlu.
Krok 4: Opakujte kroky 2 a 3, dokud všechny uzly nevytvoří jeden strom. Tak získáme Huffmanův strom.
Příklad Huffmanova kódování
Předpokládejme, že musíme zakódovat řetězec Abra Cadabra. Určete následující:
- Huffmanův kód pro všechny postavy
- Průměrná délka kódu pro daný řetězec
- Délka zakódovaného řetězce
(i) Huffmanův kód pro všechny postavy
Abychom určili kód pro každý znak, nejprve sestrojíme a Huffmanův strom.
Krok 1: Vytvořte dvojice znaků a jejich frekvence.
(a, 5), (b, 2), (c, 1), (d, 1), (r, 2)
Krok 2: Seřaďte dvojice podle frekvence, dostaneme:
(c, 1), (d, 1), (b, 2) (r, 2), (a, 5)
Krok 3: Vyberte první dva znaky a připojte je pod nadřazený uzel.

Pozorujeme, že nadřazený uzel nemá frekvenci, takže mu musíme frekvenci přiřadit. Frekvence nadřazeného uzlu bude součtem jeho podřízených uzlů (levý a pravý), tj. 1+1= 2.

Krok 4: Opakujte kroky 2 a 3, dokud nezískáte jediný strom.
Pozorujeme, že dvojice jsou již seřazeny (podle kroku 2) způsobem. Opět vyberte první dva páry a připojte je.

Pozorujeme, že nadřazený uzel nemá frekvenci, takže mu musíme frekvenci přiřadit. Frekvence nadřazeného uzlu bude součtem jeho podřízených uzlů (levý a pravý), tj. 2+2= 4.

Opět zkontrolujeme, zda jsou dvojice seřazené nebo ne. V tomto kroku musíme páry seřadit.

Podle kroku 3 vyberte první dva páry a spojte je, získáme:

Pozorujeme, že nadřazený uzel nemá frekvenci, takže mu musíme frekvenci přiřadit. Frekvence nadřazeného uzlu bude součtem jeho podřízených uzlů (levý a pravý), tj. 2+4= 6.

Opět zkontrolujeme, zda jsou dvojice seřazené nebo ne. V tomto kroku musíme páry seřadit. Po seřazení strom vypadá takto:

Podle kroku 3 vyberte první dva páry a spojte je, získáme:

Pozorujeme, že nadřazený uzel nemá frekvenci, takže mu musíme frekvenci přiřadit. Frekvence nadřazeného uzlu bude součtem jeho podřízených uzlů (levý a pravý), tj. 5+6= jedenáct.

Získáme tedy jediný strom.
Nakonec najdeme kód pro každý znak pomocí výše uvedeného stromu. Každé hraně přiřaďte váhu. Všimněte si, že každý vážený levý okraj je 0 a vážený pravý okraj je 1.

Pozorujeme, že vstupní znaky jsou prezentovány pouze v opouštěcích uzlech a vnitřní uzly mají hodnoty null. Chcete-li najít Huffmanův kód pro každý znak, přejděte přes Huffmanův strom od kořenového uzlu k listovému uzlu konkrétního znaku, pro který chceme najít kód. Tabulka popisuje kód a délku kódu pro každý znak.
| Charakter | Frekvence | Kód | Délka kódu |
|---|---|---|---|
| A | 5 | 0 | 1 |
| B | 2 | 111 | 3 |
| C | 1 | 1100 | 4 |
| D | 1 | 1101 | 4 |
| R | 2 | 10 | 2 |
Pozorujeme, že nejčastější znak má nejkratší délku kódu a méně častý znak má největší délku kódu.
Nyní můžeme řetězec zakódovat (Abra Cadabra) které jsme vzali výše.
0 111 10 0 1100 0 1101 0 111 10 0
(ii) Průměrná délka kódu pro řetězec
Průměrnou délku kódu Huffmanova stromu lze určit pomocí vzorce uvedeného níže:
Average Code Length = ∑ ( frequency × code length ) / ∑ ( frequency )
= { (5 x 1) + (2 x 3) + (1 x 4) + (1 x 4) + (2 x 2) } / (5+2+1+1+2)
= 2,09090909
(iii) Délka kódovaného řetězce
Délku zakódované zprávy lze určit pomocí následujícího vzorce:
length= Total number of characters in the text x Average code length per character
= 11 x 2,09090909
= 23 bitů
Huffmanův kódovací algoritmus
Huffman (C) n=|C| Q=C for i=1 to n-1 do z=allocate_Node() x=left[z]=Extract_Min(Q) y=right[z]=Extract_Min(Q) f[z]=f[x]+f[y] Insert(Q,z) return Extract_Min(Q)
Huffmanův algoritmus je chamtivý algoritmus. Protože v každé fázi algoritmus hledá nejlepší dostupné možnosti.
Časová složitost Huffmanova kódování je O(nlogn). Kde n je počet znaků v daném textu.
Huffmanovo dekódování
Huffmanovo dekódování je technika, která převádí zakódovaná data na počáteční data. Jak jsme viděli u kódování, Huffmanův strom je vytvořen pro vstupní řetězec a znaky jsou dekódovány na základě jejich pozice ve stromu. Proces dekódování je následující:
- Začněte přecházet přes strom z vykořenit uzel a vyhledejte postavu.
- Pokud se posuneme v binárním stromu doleva, přidejte 0 ke kódu.
- Pokud se pohybujeme přímo v binárním stromu, přidejte 1 ke kódu.
Podřízený uzel obsahuje vstupní znak. Je mu přiřazen kód tvořený následujícími 0s a 1s. Časová složitost dekódování řetězce je Na), kde n je délka řetězce.
Program Java pro kódování a dekódování Huffman
V následujícím programu jsme použili datové struktury, jako jsou prioritní fronty, zásobníky a stromy, k návrhu logiky komprese a dekomprese. Naše nástroje budeme zakládat na široce používané algoritmické technice Huffmanova kódování.
HuffmanCode.java
import java.util.Comparator; import java.util.HashMap; import java.util.Map; import java.util.PriorityQueue; //defining a class that creates nodes of the tree class Node { //storing character in ch variable of type character Character ch; //storing frequency in freq variable of type int Integer freq; //initially both child (left and right) are null Node left = null; Node right = null; //creating a constructor of the Node class Node(Character ch, Integer freq) { this.ch = ch; this.freq = freq; } //creating a constructor of the Node class public Node(Character ch, Integer freq, Node left, Node right) { this.ch = ch; this.freq = freq; this.left = left; this.right = right; } } //main class public class HuffmanCode { //function to build Huffman tree public static void createHuffmanTree(String text) { //base case: if user does not provides string if (text == null || text.length() == 0) { return; } //count the frequency of appearance of each character and store it in a map //creating an instance of the Map Map freq = new HashMap(); //loop iterates over the string and converts the text into character array for (char c: text.toCharArray()) { //storing character and their frequency into Map by invoking the put() method freq.put(c, freq.getOrDefault(c, 0) + 1); } //create a priority queue that stores current nodes of the Huffman tree. //here a point to note that the highest priority means the lowest frequency PriorityQueue pq = new PriorityQueue(Comparator.comparingInt(l -> l.freq)); //loop iterate over the Map and returns a Set view of the mappings contained in this Map for (var entry: freq.entrySet()) { //creates a leaf node and add it to the queue pq.add(new Node(entry.getKey(), entry.getValue())); } //while loop runs until there is more than one node in the queue while (pq.size() != 1) { //removing the nodes having the highest priority (the lowest frequency) from the queue Node left = pq.poll(); Node right = pq.poll(); //create a new internal node with these two nodes as children and with a frequency equal to the sum of both nodes' frequencies. Add the new node to the priority queue. //sum up the frequency of the nodes (left and right) that we have deleted int sum = left.freq + right.freq; //adding a new internal node (deleted nodes i.e. right and left) to the queue with a frequency that is equal to the sum of both nodes pq.add(new Node(null, sum, left, right)); } //root stores pointer to the root of Huffman Tree Node root = pq.peek(); //trace over the Huffman tree and store the Huffman codes in a map Map huffmanCode = new HashMap(); encodeData(root, '', huffmanCode); //print the Huffman codes for the characters System.out.println('Huffman Codes of the characters are: ' + huffmanCode); //prints the initial data System.out.println('The initial string is: ' + text); //creating an instance of the StringBuilder class StringBuilder sb = new StringBuilder(); //loop iterate over the character array for (char c: text.toCharArray()) { //prints encoded string by getting characters sb.append(huffmanCode.get(c)); } System.out.println('The encoded string is: ' + sb); System.out.print('The decoded string is: '); if (isLeaf(root)) { //special case: For input like a, aa, aaa, etc. while (root.freq-- > 0) { System.out.print(root.ch); } } else { //traverse over the Huffman tree again and this time, decode the encoded string int index = -1; while (index <sb.length() - 1) { index="decodeData(root," index, sb); } traverse the huffman tree and store codes in a map function that encodes data public static void encodedata(node root, string str, huffmancode) if (root="=" null) return; checks node is leaf or not (isleaf(root)) huffmancode.put(root.ch, str.length()> 0 ? str : '1'); } encodeData(root.left, str + '0', huffmanCode); encodeData(root.right, str + '1', huffmanCode); } //traverse the Huffman Tree and decode the encoded string function that decodes the encoded data public static int decodeData(Node root, int index, StringBuilder sb) { //checks if the root node is null or not if (root == null) { return index; } //checks if the node is a leaf node or not if (isLeaf(root)) { System.out.print(root.ch); return index; } index++; root = (sb.charAt(index) == '0') ? root.left : root.right; index = decodeData(root, index, sb); return index; } //function to check if the Huffman Tree contains a single node public static boolean isLeaf(Node root) { //returns true if both conditions return ture return root.left == null && root.right == null; } //driver code public static void main(String args[]) { String text = 'javatpoint'; //function calling createHuffmanTree(text); } } </sb.length()> Výstup:
Huffman Codes of the characters are: {p=000, a=110, t=111, v=001, i=010, j=011, n=100, o=101} The initial string is: javatpoint The encoded string is: 011110001110111000101010100111 The decoded string is: javatpoint