Implementace hash tabulky v C/C++ pomocí samostatného řetězení
Úvod:
Zkracovače adres URL jsou příkladem hašování, protože mapují velké adresy URL na malé velikosti
Některé příklady hashovacích funkcí:
- klíč % počet kbelíků
- ASCII hodnota znaku * Prvočíslo X . Kde x = 1, 2, 3….n
- Můžete si vytvořit vlastní hašovací funkci, ale měla by to být dobrá hašovací funkce, která dává menší počet kolizí.

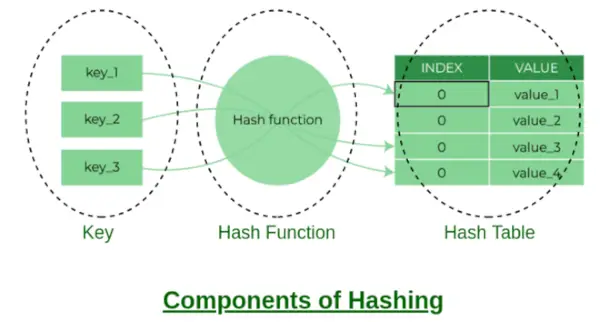
Komponenty hashování
Index segmentu:
Hodnota vrácená funkcí Hash je index segmentu pro klíč v samostatné metodě řetězení. Každý index v poli se nazývá segment, protože se jedná o segment propojeného seznamu.
Opakování:
Rehashing je koncept, který snižuje kolize při zvýšení prvků v aktuální hashovací tabulce. Vytvoří nové pole o dvojnásobné velikosti a zkopíruje do něj předchozí prvky pole a je to jako vnitřní práce vektoru v C++. Je zřejmé, že funkce hash by měla být dynamická, protože by měla odrážet některé změny při zvýšení kapacity. Hašovací funkce v ní zahrnuje kapacitu hašovací tabulky, proto při kopírování klíčových hodnot z předchozí hašovací funkce pole poskytuje různé indexy segmentu, protože závisí na kapacitě (segmentech) hašovací tabulky. Obecně platí, že když je hodnota zátěžového faktoru větší než 0,5, provádějí se rehashingy.
- Zdvojnásobte velikost pole.
- Zkopírujte prvky předchozího pole do nového pole. Při kopírování každého uzlu do nového pole používáme hašovací funkci, takže to sníží kolizi.
- Odstraňte předchozí pole z paměti a nasměrujte ukazatel uvnitř pole hash mapy na toto nové pole.
- Obecně platí, že Load Factor = počet prvků v Hash Map / celkový počet bucketů (kapacita).
Srážka:
Kolize je situace, kdy index bucketu není prázdný. Znamená to, že v tomto indexu segmentu je přítomna hlavička propojeného seznamu. Máme dvě nebo více hodnot, které se mapují na stejný index segmentu.
Hlavní funkce v našem programu
- Vložení
- Vyhledávání
- Hashovací funkce
- Vymazat
- Rehashing
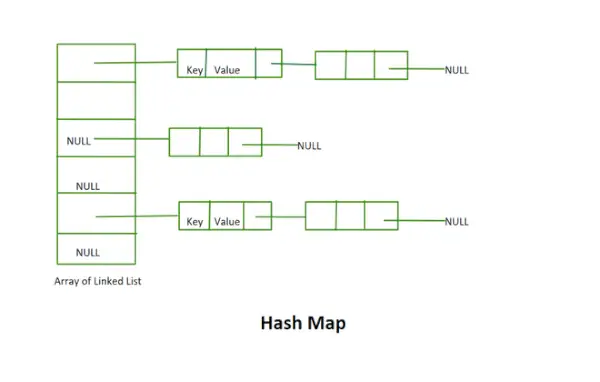
Hashová mapa
Implementace bez přehánění:
C
#include> #include> #include> // Linked List node> struct> node {> > // key is string> > char> * key;> > // value is also string> > char> * value;> > struct> node* next;> };> // like constructor> void> setNode(> struct> node* node,> char> * key,> char> * value)> {> > node->klíč = klíč;> > node->hodnota = hodnota;> > node->další = NULL;> > return> ;> };> struct> hashMap {> > // Current number of elements in hashMap> > // and capacity of hashMap> > int> numOfElements, capacity;> > // hold base address array of linked list> > struct> node** arr;> };> // like constructor> void> initializeHashMap(> struct> hashMap* mp)> {> > // Default capacity in this case> > mp->kapacita = 100;> > mp->numOfElements = 0;> > // array of size = 1> > mp->arr = (> struct> node**)> malloc> (> sizeof> (> struct> node*)> > * mp->kapacita);> > return> ;> }> int> hashFunction(> struct> hashMap* mp,> char> * key)> {> > int> bucketIndex;> > int> sum = 0, factor = 31;> > for> (> int> i = 0; i <> strlen> (key); i++) {> > // sum = sum + (ascii value of> > // char * (primeNumber ^ x))...> > // where x = 1, 2, 3....n> > sum = ((sum % mp->kapacita)> > + (((> int> )key[i]) * factor) % mp->kapacita)> > % mp->kapacita;> > // factor = factor * prime> > // number....(prime> > // number) ^ x> > factor = ((factor % __INT16_MAX__)> > * (31 % __INT16_MAX__))> > % __INT16_MAX__;> > }> > bucketIndex = sum;> > return> bucketIndex;> }> void> insert(> struct> hashMap* mp,> char> * key,> char> * value)> {> > // Getting bucket index for the given> > // key - value pair> > int> bucketIndex = hashFunction(mp, key);> > struct> node* newNode = (> struct> node*)> malloc> (> > // Creating a new node> > sizeof> (> struct> node));> > // Setting value of node> > setNode(newNode, key, value);> > // Bucket index is empty....no collision> > if> (mp->arr[bucketIndex] == NULL) {> > mp->arr[bucketIndex] = newNode;> > }> > // Collision> > else> {> > // Adding newNode at the head of> > // linked list which is present> > // at bucket index....insertion at> > // head in linked list> > newNode->next = mp->arr[bucketIndex];> > mp->arr[bucketIndex] = newNode;> > }> > return> ;> }> void> delete> (> struct> hashMap* mp,> char> * key)> {> > // Getting bucket index for the> > // given key> > int> bucketIndex = hashFunction(mp, key);> > struct> node* prevNode = NULL;> > // Points to the head of> > // linked list present at> > // bucket index> > struct> node* currNode = mp->arr[bucketIndex];> > while> (currNode != NULL) {> > // Key is matched at delete this> > // node from linked list> > if> (> strcmp> (key, currNode->klíč) == 0) {> > // Head node> > // deletion> > if> (currNode == mp->arr[bucketIndex]) {> > mp->arr[bucketIndex] = currNode->next;> > }> > // Last node or middle node> > else> {> > prevNode->next = currNode->next;> > }> > free> (currNode);> > break> ;> > }> > prevNode = currNode;> > currNode = currNode->další;> > }> > return> ;> }> char> * search(> struct> hashMap* mp,> char> * key)> {> > // Getting the bucket index> > // for the given key> > int> bucketIndex = hashFunction(mp, key);> > // Head of the linked list> > // present at bucket index> > struct> node* bucketHead = mp->arr[bucketIndex];> > while> (bucketHead != NULL) {> > // Key is found in the hashMap> > if> (bucketHead->klíč == klíč) {> > return> bucketHead->hodnota;> > }> > bucketHead = bucketHead->další;> > }> > // If no key found in the hashMap> > // equal to the given key> > char> * errorMssg = (> char> *)> malloc> (> sizeof> (> char> ) * 25);> > errorMssg => 'Oops! No data found.
'> ;> > return> errorMssg;> }> // Drivers code> int> main()> {> > // Initialize the value of mp> > struct> hashMap* mp> > = (> struct> hashMap*)> malloc> (> sizeof> (> struct> hashMap));> > initializeHashMap(mp);> > insert(mp,> 'Yogaholic'> ,> 'Anjali'> );> > insert(mp,> 'pluto14'> ,> 'Vartika'> );> > insert(mp,> 'elite_Programmer'> ,> 'Manish'> );> > insert(mp,> 'GFG'> ,> 'techcodeview.com'> );> > insert(mp,> 'decentBoy'> ,> 'Mayank'> );> > printf> (> '%s
'> , search(mp,> 'elite_Programmer'> ));> > printf> (> '%s
'> , search(mp,> 'Yogaholic'> ));> > printf> (> '%s
'> , search(mp,> 'pluto14'> ));> > printf> (> '%s
'> , search(mp,> 'decentBoy'> ));> > printf> (> '%s
'> , search(mp,> 'GFG'> ));> > // Key is not inserted> > printf> (> '%s
'> , search(mp,> 'randomKey'> ));> > printf> (> '
After deletion :
'> );> > // Deletion of key> > delete> (mp,> 'decentBoy'> );> > printf> (> '%s
'> , search(mp,> 'decentBoy'> ));> > return> 0;> }> |
C++
#include> #include> // Linked List node> struct> node {> > // key is string> > char> * key;> > // value is also string> > char> * value;> > struct> node* next;> };> // like constructor> void> setNode(> struct> node* node,> char> * key,> char> * value) {> > node->klíč = klíč;> > node->hodnota = hodnota;> > node->další = NULL;> > return> ;> }> struct> hashMap {> > // Current number of elements in hashMap> > // and capacity of hashMap> > int> numOfElements, capacity;> > // hold base address array of linked list> > struct> node** arr;> };> // like constructor> void> initializeHashMap(> struct> hashMap* mp) {> > // Default capacity in this case> > mp->kapacita = 100;> > mp->numOfElements = 0;> > // array of size = 1> > mp->arr = (> struct> node**)> malloc> (> sizeof> (> struct> node*) * mp->kapacita);> > return> ;> }> int> hashFunction(> struct> hashMap* mp,> char> * key) {> > int> bucketIndex;> > int> sum = 0, factor = 31;> > for> (> int> i = 0; i <> strlen> (key); i++) {> > // sum = sum + (ascii value of> > // char * (primeNumber ^ x))...> > // where x = 1, 2, 3....n> > sum = ((sum % mp->kapacita) + (((> int> )key[i]) * factor) % mp->kapacita) % mp->kapacita;> > // factor = factor * prime> > // number....(prime> > // number) ^ x> > factor = ((factor % __INT16_MAX__) * (31 % __INT16_MAX__)) % __INT16_MAX__;> > }> > bucketIndex = sum;> > return> bucketIndex;> }> void> insert(> struct> hashMap* mp,> char> * key,> char> * value) {> > // Getting bucket index for the given> > // key - value pair> > int> bucketIndex = hashFunction(mp, key);> > struct> node* newNode = (> struct> node*)> malloc> (> > // Creating a new node> > sizeof> (> struct> node));> > // Setting value of node> > setNode(newNode, key, value);> > // Bucket index is empty....no collision> > if> (mp->arr[bucketIndex] == NULL) {> > mp->arr[bucketIndex] = newNode;> > }> > // Collision> > else> {> > // Adding newNode at the head of> > // linked list which is present> > // at bucket index....insertion at> > // head in linked list> > newNode->next = mp->arr[bucketIndex];> > mp->arr[bucketIndex] = newNode;> > }> > return> ;> }> void> deleteKey(> struct> hashMap* mp,> char> * key) {> > // Getting bucket index for the> > // given key> > int> bucketIndex = hashFunction(mp, key);> > struct> node* prevNode = NULL;> > // Points to the head of> > // linked list present at> > // bucket index> > struct> node* currNode = mp->arr[bucketIndex];> > while> (currNode != NULL) {> > // Key is matched at delete this> > // node from linked list> > if> (> strcmp> (key, currNode->klíč) == 0) {> > // Head node> > // deletion> > if> (currNode == mp->arr[bucketIndex]) {> > mp->arr[bucketIndex] = currNode->next;> > }> > // Last node or middle node> > else> {> > prevNode->next = currNode->next;> }> free> (currNode);> break> ;> }> prevNode = currNode;> > currNode = currNode->další;> > }> return> ;> }> char> * search(> struct> hashMap* mp,> char> * key) {> // Getting the bucket index for the given key> int> bucketIndex = hashFunction(mp, key);> // Head of the linked list present at bucket index> struct> node* bucketHead = mp->arr[bucketIndex];> while> (bucketHead != NULL) {> > > // Key is found in the hashMap> > if> (> strcmp> (bucketHead->klíč, klíč) == 0) {> > return> bucketHead->hodnota;> > }> > > bucketHead = bucketHead->další;> }> // If no key found in the hashMap equal to the given key> char> * errorMssg = (> char> *)> malloc> (> sizeof> (> char> ) * 25);> strcpy> (errorMssg,> 'Oops! No data found.
'> );> return> errorMssg;> }> // Drivers code> int> main()> {> // Initialize the value of mp> struct> hashMap* mp = (> struct> hashMap*)> malloc> (> sizeof> (> struct> hashMap));> initializeHashMap(mp);> insert(mp,> 'Yogaholic'> ,> 'Anjali'> );> insert(mp,> 'pluto14'> ,> 'Vartika'> );> insert(mp,> 'elite_Programmer'> ,> 'Manish'> );> insert(mp,> 'GFG'> ,> 'techcodeview.com'> );> insert(mp,> 'decentBoy'> ,> 'Mayank'> );> printf> (> '%s
'> , search(mp,> 'elite_Programmer'> ));> printf> (> '%s
'> , search(mp,> 'Yogaholic'> ));> printf> (> '%s
'> , search(mp,> 'pluto14'> ));> printf> (> '%s
'> , search(mp,> 'decentBoy'> ));> printf> (> '%s
'> , search(mp,> 'GFG'> ));> // Key is not inserted> printf> (> '%s
'> , search(mp,> 'randomKey'> ));> printf> (> '
After deletion :
'> );> // Deletion of key> deleteKey(mp,> 'decentBoy'> );> // Searching the deleted key> printf> (> '%s
'> , search(mp,> 'decentBoy'> ));> return> 0;> }> |
Výstup
Manish Anjali Vartika Mayank techcodeview.com Oops! No data found. After deletion : Oops! No data found.
Vysvětlení:
- insertion: Vloží pár klíč–hodnota na začátek propojeného seznamu, který je přítomen v daném indexu segmentu. hashFunction: Poskytuje index segmentu pro daný klíč. Náš hashovací funkce = ASCII hodnota znaku * prvočíslo X . Prvočíslo je v našem případě 31 a hodnota x se zvyšuje z 1 na n pro po sobě jdoucí znaky v klíči. deletion: Odstraní pár klíč-hodnota z hašovací tabulky pro daný klíč. Odstraní uzel z propojeného seznamu, který obsahuje pár klíč–hodnota. Hledat: Vyhledání hodnoty daného klíče.
- Tato implementace nepoužívá koncept rehashingu. Jedná se o pole propojených seznamů s pevnou velikostí.
- Klíč i hodnota jsou v daném příkladu řetězce.
Časová a prostorová složitost:
Časová složitost operací vkládání a mazání hashovací tabulky je v průměru O(1). Existuje nějaký matematický výpočet, který to dokazuje.
- Časová složitost vkládání: V průměrném případě je konstantní. V nejhorším případě je lineární. Časová složitost vyhledávání: V průměrném případě je konstantní. V nejhorším případě je lineární. Časová složitost mazání: V průměrných případech je konstantní. V nejhorším případě je lineární. Prostorová složitost: O(n), protože má n počet prvků.
Související články:
- Samostatná technika řetězení při hašování kolizí.