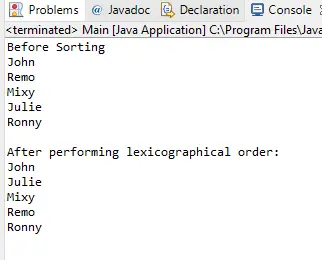
Метод Pandas DataFrame.loc[].
Pandas DataFrame — це двовимірна, що змінює розмір, потенційно неоднорідна таблична структура даних із позначеними осями (рядки та стовпці). Арифметичні операції вирівнюються на мітках рядків і стовпців. Його можна розглядати як dict-подібний контейнер для об’єктів Series. Це первинна структура даних панди .
Синтаксис Pandas DataFrame loc[].
панди DataFrame.loc атрибут отримує доступ до групи рядків і стовпців за мітками або логічним масивом у заданому Pandas DataFrame .
Синтаксис: DataFrame.loc
Параметр: Жодного
Повернення: Скаляр, ряд, DataFrame
Властивість Pandas DataFrame loc
Нижче наведено кілька прикладів, за допомогою яких ми можемо використовувати Pandas DataFrame loc[]:
приклад 1: Виберіть один рядок і стовпець за міткою за допомогою loc[]
Використовуйте атрибут DataFrame.loc для доступу до певної комірки в заданому Pandas Data Frame за допомогою індексу та міток стовпців. Потім ми вибираємо один рядок і стовпець за міткою за допомогою loc[].
Python3
# importing pandas as pd> import> pandas as pd> # Creating the DataFrame> df> => pd.DataFrame({> 'Weight'> : [> 45> ,> 88> ,> 56> ,> 15> ,> 71> ],> > 'Name'> : [> 'Sam'> ,> 'Andrea'> ,> 'Alex'> ,> 'Robin'> ,> 'Kia'> ],> > 'Age'> : [> 14> ,> 25> ,> 55> ,> 8> ,> 21> ]})> # Create the index> index_> => [> 'Row_1'> ,> 'Row_2'> ,> 'Row_3'> ,> 'Row_4'> ,> 'Row_5'> ]> # Set the index> df.index> => index_> # Print the DataFrame> print> (> 'Original DataFrame:'> )> print> (df)> # Corrected selection using loc for a specific cell> result> => df.loc[> 'Row_2'> ,> 'Name'> ]> # Print the result> print> (> '
Selected Value at Row_2, Column 'Name':'> )> print> (result)> |
Вихід
Original DataFrame: Weight Name Age Row_1 45 Sam 14 Row_2 88 Andrea 25 Row_3 56 Alex 55 Row_4 15 Robin 8 Row_5 71 Kia 21 Selected Value at Row_2, Column 'Name': Andrea
приклад 2: Виберіть кілька рядків і стовпців
Використовуйте атрибут DataFrame.loc, щоб повернути два стовпці в заданому Dataframe, а потім виберіть кілька рядків і стовпців, як це зроблено в прикладі нижче.
Python3
# importing pandas as pd> import> pandas as pd> # Creating the DataFrame> df> => pd.DataFrame({> 'A'> :[> 12> ,> 4> ,> 5> ,> None> ,> 1> ],> > 'B'> :[> 7> ,> 2> ,> 54> ,> 3> ,> None> ],> > 'C'> :[> 20> ,> 16> ,> 11> ,> 3> ,> 8> ],> > 'D'> :[> 14> ,> 3> ,> None> ,> 2> ,> 6> ]})> # Create the index> index_> => [> 'Row_1'> ,> 'Row_2'> ,> 'Row_3'> ,> 'Row_4'> ,> 'Row_5'> ]> # Set the index> df.index> => index_> # Print the DataFrame> print> (> 'Original DataFrame:'> )> print> (df)> # Corrected column names ('A' and 'D') in the result> result> => df.loc[:, [> 'A'> ,> 'D'> ]]> # Print the result> print> (> '
Selected Columns 'A' and 'D':'> )> print> (result)> |
Вихід
Original DataFrame: A B C D Row_1 12.0 7 20 14.0 Row_2 4.0 2 16 3.0 Row_3 5.0 54 11 NaN Row_4 NaN 3 3 2.0 Row_5 1.0 NaN 8 6.0 Selected Columns 'A' and 'D': A D Row_1 12.0 14.0 Row_2 4.0 3.0 Row_3 5.0 NaN Row_4 NaN 2.0 Row_5 1.0 6.0
Приклад 3: вибір між двома рядками або стовпцями
У цьому прикладі ми створюємо pandas DataFrame під назвою «df», встановлюємо спеціальні індекси рядків, а потім використовуємо loc> засіб доступу для вибору рядків між «Рядок_2» і «Рядок_4» включно та стовпців «B» — «D». Вибрані рядки та стовпці друкуються, демонструючи використання індексування на основі міток loc> .
Python3
# importing pandas as pd> import> pandas as pd> # Creating the DataFrame> df> => pd.DataFrame({> 'A'> : [> 12> ,> 4> ,> 5> ,> None> ,> 1> ],> > 'B'> : [> 7> ,> 2> ,> 54> ,> 3> ,> None> ],> > 'C'> : [> 20> ,> 16> ,> 11> ,> 3> ,> 8> ],> > 'D'> : [> 14> ,> 3> ,> None> ,> 2> ,> 6> ]})> # Create the index> index_> => [> 'Row_1'> ,> 'Row_2'> ,> 'Row_3'> ,> 'Row_4'> ,> 'Row_5'> ]> # Set the index> df.index> => index_> # Print the original DataFrame> print> (> 'Original DataFrame:'> )> print> (df)> # Select Rows Between 'Row_2' and 'Row_4'> selected_rows> => df.loc[> 'Row_2'> :> 'Row_4'> ]> print> (> '
Selected Rows:'> )> print> (selected_rows)> # Select Columns 'B' through 'D'> selected_columns> => df.loc[:,> 'B'> :> 'D'> ]> print> (> '
Selected Columns:'> )> print> (selected_columns)> |
Вихід
Original DataFrame: A B C D Row_1 12.0 7 20 14.0 Row_2 4.0 2 16 3.0 Row_3 5.0 54 11 NaN Row_4 NaN 3 3 2.0 Row_5 1.0 NaN 8 6.0 Selected Rows: A B C D Row_2 4 2 16 3.0 Row_3 5 54 11 NaN Row_4 NaN 3 3 2.0 Selected Columns: B C D Row_1 7 20 14.0 Row_2 2 16 3.0 Row_3 54 11 NaN Row_4 3 3 2.0 Row_5 NaN 8 6.0
Приклад 4: Виберіть альтернативні рядки або стовпці
У цьому прикладі ми створюємо pandas DataFrame під назвою «df», встановлюємо спеціальні індекси рядків, а потім використовуємо iloc> засіб доступу для вибору альтернативних рядків (кожен другий рядок) і альтернативних стовпців (кожен другий стовпець). Отримані вибірки друкуються, демонструючи використання індексування на основі цілих чисел iloc> .
Python3
# importing pandas as pd> import> pandas as pd> # Creating the DataFrame> df> => pd.DataFrame({> 'A'> : [> 12> ,> 4> ,> 5> ,> None> ,> 1> ],> > 'B'> : [> 7> ,> 2> ,> 54> ,> 3> ,> None> ],> > 'C'> : [> 20> ,> 16> ,> 11> ,> 3> ,> 8> ],> > 'D'> : [> 14> ,> 3> ,> None> ,> 2> ,> 6> ]})> # Create the index> index_> => [> 'Row_1'> ,> 'Row_2'> ,> 'Row_3'> ,> 'Row_4'> ,> 'Row_5'> ]> # Set the index> df.index> => index_> # Print the original DataFrame> print> (> 'Original DataFrame:'> )> print> (df)> # Select Alternate Rows> alternate_rows> => df.iloc[::> 2> ]> print> (> '
Alternate Rows:'> )> print> (alternate_rows)> # Select Alternate Columns> alternate_columns> => df.iloc[:, ::> 2> ]> print> (> '
Alternate Columns:'> )> print> (alternate_columns)> |
Вихід
Original DataFrame: A B C D Row_1 12.0 7 20 14.0 Row_2 4.0 2 16 3.0 Row_3 5.0 54 11 NaN Row_4 NaN 3 3 2.0 Row_5 1.0 NaN 8 6.0 Alternate Rows: A B C D Row_1 12.0 7 20 14.0 Row_3 5.0 54 11 NaN Row_5 1.0 NaN 8 6.0 Alternate Columns: A C Row_1 12.0 20 Row_2 4.0 16 Row_3 5.0 11 Row_4 NaN 3 Row_5 1.0 8
Приклад 5: Використання умов із Pandas loc
У цьому прикладі ми створюємо pandas DataFrame під назвою «df», встановлюємо спеціальні індекси рядків і використовуємо loc> засіб доступу для вибору рядків на основі умов. Він демонструє вибір рядків, де стовпець «A» має значення, більші за 5, і вибір рядків, де стовпець «B» не є нульовим. Отримані виділення потім друкуються, демонструючи використання умовного фільтрування loc> .
Python3
# importing pandas as pd> import> pandas as pd> # Creating the DataFrame> df> => pd.DataFrame({> 'A'> : [> 12> ,> 4> ,> 5> ,> None> ,> 1> ],> > 'B'> : [> 7> ,> 2> ,> 54> ,> 3> ,> None> ],> > 'C'> : [> 20> ,> 16> ,> 11> ,> 3> ,> 8> ],> > 'D'> : [> 14> ,> 3> ,> None> ,> 2> ,> 6> ]})> # Create the index> index_> => [> 'Row_1'> ,> 'Row_2'> ,> 'Row_3'> ,> 'Row_4'> ,> 'Row_5'> ]> # Set the index> df.index> => index_> # Print the original DataFrame> print> (> 'Original DataFrame:'> )> print> (df)> # Using Conditions with loc> # Example: Select rows where column 'A' is greater than 5> selected_rows> => df.loc[df[> 'A'> ]>> 5> ]> print> (> '
Rows where column 'A' is greater than 5:'> )> print> (selected_rows)> # Example: Select rows where column 'B' is not null> non_null_rows> => df.loc[df[> 'B'> ].notnull()]> print> (> '
Rows where column 'B' is not null:'> )> print> (non_null_rows)> |
Вихід
Original DataFrame: A B C D Row_1 12.0 7 20 14.0 Row_2 4.0 2 16 3.0 Row_3 5.0 54 11 NaN Row_4 NaN 3 3 2.0 Row_5 1.0 NaN 8 6.0 Rows where column 'A' is greater than 5: A B C D Row_1 12.0 7 20 14.0 Row_3 5.0 54 11 NaN Rows where column 'B' is not null: A B C D Row_1 12.0 7 20 14.0 Row_2 4.0 2 16 3.0 Row_3 5.0 54 11 NaN Row_4 NaN 3 3 2.0