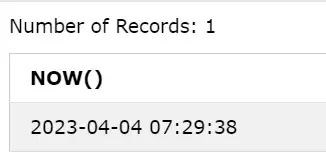
Підручник Apache Spark


Підручник Apache Spark містить базові та розширені концепції Spark. Наш підручник Spark призначений для початківців і професіоналів.
Spark — це уніфікований механізм аналітики для великомасштабної обробки даних, включаючи вбудовані модулі для SQL, потокової передачі, машинного навчання та обробки графіків.
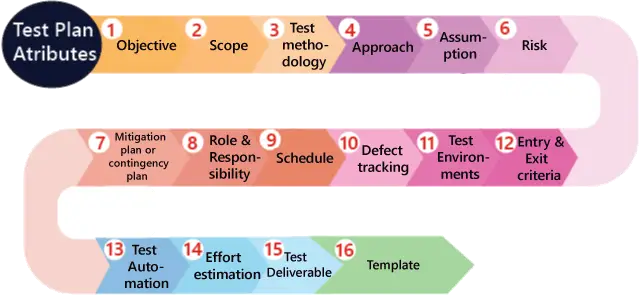
Наш навчальний посібник із Spark включає всі теми Apache Spark із вступом до Spark, інсталяцією Spark, архітектурою Spark, компонентами Spark, RDD, прикладами Spark у реальному часі тощо.
Що таке Spark?
Apache Spark — це платформа кластерних обчислень з відкритим кодом. Його основна мета — обробка даних, згенерованих у реальному часі.
Spark було створено на основі Hadoop MapReduce. Він був оптимізований для роботи в пам’яті, тоді як альтернативні підходи, такі як MapReduce від Hadoop, записують дані на жорсткі диски комп’ютера та з них. Таким чином, Spark обробляє дані набагато швидше, ніж інші альтернативи.
Історія Apache Spark
Іскра була ініційована Матеєм Захарією з UC Berkeley's AMLab у 2009 році. У 2010 році він був відкритий за ліцензією BSD.
У 2013 році проект придбала Apache Software Foundation. У 2014 році Spark став проектом Apache верхнього рівня.
Особливості Apache Spark
Використання Spark
Передумова
Перш ніж вивчати Spark, ви повинні мати базові знання про Hadoop.
Аудиторія
Наш підручник Spark розроблений, щоб допомогти новачкам і професіоналам.
Проблеми
Ми запевняємо вас, що ви не знайдете жодних проблем із цим підручником Spark. Однак, якщо виникне будь-яка помилка, опублікуйте проблему в контактній формі.