Implementering av Hash Table i C/C++ med Separate Chaining
Introduktion:
URL-förkortare är ett exempel på hash eftersom det mappar stora webbadresser till små
Några exempel på hashfunktioner:
- nyckel % antal hinkar
- ASCII-värde för tecken * PrimeNumber x . Där x = 1, 2, 3….n
- Du kan göra din egen hashfunktion men det bör vara en bra hashfunktion som ger färre antal kollisioner.

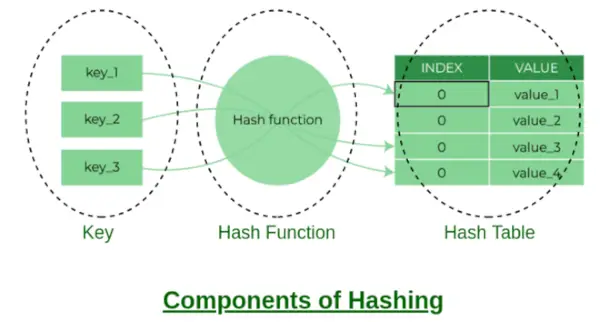
Komponenter av hashing
Hinkindex:
Värdet som returneras av Hash-funktionen är hinkindex för en nyckel i en separat kedjemetod. Varje index i arrayen kallas en bucket eftersom det är en bucket av en länkad lista.
Omhasning:
Rehashing är ett koncept som minskar kollision när elementen ökas i den aktuella hashtabellen. Det kommer att skapa en ny array med fördubblad storlek och kopiera de tidigare arrayelementen till den och det är som den interna bearbetningen av vektorn i C++. Uppenbarligen bör Hash-funktionen vara dynamisk eftersom den bör återspegla vissa förändringar när kapaciteten ökas. Hashfunktionen inkluderar kapaciteten för hashtabellen i den, därför ger medan kopiering av nyckelvärden från den tidigare array-hashfunktionen olika hinkindex eftersom det är beroende av hashtabellens kapacitet (buckets). I allmänhet görs omhasningar när belastningsfaktorns värde är större än 0,5.
- Dubbel storleken på arrayen.
- Kopiera elementen från den tidigare arrayen till den nya arrayen. Vi använder hash-funktionen medan vi kopierar varje nod till en ny array igen, därför kommer det att minska kollision.
- Ta bort den tidigare arrayen från minnet och peka din hashkartas inre arraypekare till denna nya array.
- Generellt är Load Factor = antal element i Hash Map / totalt antal hinkar (kapacitet).
Kollision:
Kollision är situationen när skopindexet inte är tomt. Det betyder att ett länkat listhuvud finns i det hinkindexet. Vi har två eller flera värden som mappar till samma hinkindex.
Huvudfunktioner i vårt program
- Införande
- Sök
- Hash-funktion
- Radera
- Omhasning
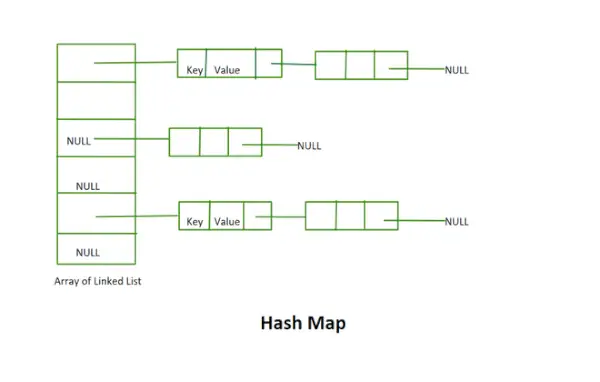
Hash karta
Implementering utan omhasning:
C
#include> #include> #include> // Linked List node> struct> node {> > // key is string> > char> * key;> > // value is also string> > char> * value;> > struct> node* next;> };> // like constructor> void> setNode(> struct> node* node,> char> * key,> char> * value)> {> > node->nyckel = nyckel;> > node->värde = värde;> > node->nästa = NULL;> > return> ;> };> struct> hashMap {> > // Current number of elements in hashMap> > // and capacity of hashMap> > int> numOfElements, capacity;> > // hold base address array of linked list> > struct> node** arr;> };> // like constructor> void> initializeHashMap(> struct> hashMap* mp)> {> > // Default capacity in this case> > mp->kapacitet = 100;> > mp->numOfElements = 0;> > // array of size = 1> > mp->arr = (> struct> node**)> malloc> (> sizeof> (> struct> node*)> > * mp->kapacitet);> > return> ;> }> int> hashFunction(> struct> hashMap* mp,> char> * key)> {> > int> bucketIndex;> > int> sum = 0, factor = 31;> > for> (> int> i = 0; i <> strlen> (key); i++) {> > // sum = sum + (ascii value of> > // char * (primeNumber ^ x))...> > // where x = 1, 2, 3....n> > sum = ((sum % mp->kapacitet)> > + (((> int> )key[i]) * factor) % mp->kapacitet)> > % mp->kapacitet;> > // factor = factor * prime> > // number....(prime> > // number) ^ x> > factor = ((factor % __INT16_MAX__)> > * (31 % __INT16_MAX__))> > % __INT16_MAX__;> > }> > bucketIndex = sum;> > return> bucketIndex;> }> void> insert(> struct> hashMap* mp,> char> * key,> char> * value)> {> > // Getting bucket index for the given> > // key - value pair> > int> bucketIndex = hashFunction(mp, key);> > struct> node* newNode = (> struct> node*)> malloc> (> > // Creating a new node> > sizeof> (> struct> node));> > // Setting value of node> > setNode(newNode, key, value);> > // Bucket index is empty....no collision> > if> (mp->arr[bucketIndex] == NULL) {> > mp->arr[bucketIndex] = newNode;> > }> > // Collision> > else> {> > // Adding newNode at the head of> > // linked list which is present> > // at bucket index....insertion at> > // head in linked list> > newNode->nästa = mp->arr[bucketIndex];> > mp->arr[bucketIndex] = newNode;> > }> > return> ;> }> void> delete> (> struct> hashMap* mp,> char> * key)> {> > // Getting bucket index for the> > // given key> > int> bucketIndex = hashFunction(mp, key);> > struct> node* prevNode = NULL;> > // Points to the head of> > // linked list present at> > // bucket index> > struct> node* currNode = mp->arr[bucketIndex];> > while> (currNode != NULL) {> > // Key is matched at delete this> > // node from linked list> > if> (> strcmp> (key, currNode->nyckel) == 0) {> > // Head node> > // deletion> > if> (currNode == mp->arr[bucketIndex]) {> > mp->arr[bucketIndex] = currNode->nästa;> > }> > // Last node or middle node> > else> {> > prevNode->nästa = currNode->nästa;> > }> > free> (currNode);> > break> ;> > }> > prevNode = currNode;> > currNode = currNode->nästa;> > }> > return> ;> }> char> * search(> struct> hashMap* mp,> char> * key)> {> > // Getting the bucket index> > // for the given key> > int> bucketIndex = hashFunction(mp, key);> > // Head of the linked list> > // present at bucket index> > struct> node* bucketHead = mp->arr[bucketIndex];> > while> (bucketHead != NULL) {> > // Key is found in the hashMap> > if> (bucketHead->nyckel == nyckel) {> > return> bucketHead->värde;> > }> > bucketHead = bucketHead->nästa;> > }> > // If no key found in the hashMap> > // equal to the given key> > char> * errorMssg = (> char> *)> malloc> (> sizeof> (> char> ) * 25);> > errorMssg => 'Oops! No data found.
'> ;> > return> errorMssg;> }> // Drivers code> int> main()> {> > // Initialize the value of mp> > struct> hashMap* mp> > = (> struct> hashMap*)> malloc> (> sizeof> (> struct> hashMap));> > initializeHashMap(mp);> > insert(mp,> 'Yogaholic'> ,> 'Anjali'> );> > insert(mp,> 'pluto14'> ,> 'Vartika'> );> > insert(mp,> 'elite_Programmer'> ,> 'Manish'> );> > insert(mp,> 'GFG'> ,> 'techcodeview.com'> );> > insert(mp,> 'decentBoy'> ,> 'Mayank'> );> > printf> (> '%s
'> , search(mp,> 'elite_Programmer'> ));> > printf> (> '%s
'> , search(mp,> 'Yogaholic'> ));> > printf> (> '%s
'> , search(mp,> 'pluto14'> ));> > printf> (> '%s
'> , search(mp,> 'decentBoy'> ));> > printf> (> '%s
'> , search(mp,> 'GFG'> ));> > // Key is not inserted> > printf> (> '%s
'> , search(mp,> 'randomKey'> ));> > printf> (> '
After deletion :
'> );> > // Deletion of key> > delete> (mp,> 'decentBoy'> );> > printf> (> '%s
'> , search(mp,> 'decentBoy'> ));> > return> 0;> }> |
C++
#include> #include> // Linked List node> struct> node {> > // key is string> > char> * key;> > // value is also string> > char> * value;> > struct> node* next;> };> // like constructor> void> setNode(> struct> node* node,> char> * key,> char> * value) {> > node->nyckel = nyckel;> > node->värde = värde;> > node->nästa = NULL;> > return> ;> }> struct> hashMap {> > // Current number of elements in hashMap> > // and capacity of hashMap> > int> numOfElements, capacity;> > // hold base address array of linked list> > struct> node** arr;> };> // like constructor> void> initializeHashMap(> struct> hashMap* mp) {> > // Default capacity in this case> > mp->kapacitet = 100;> > mp->numOfElements = 0;> > // array of size = 1> > mp->arr = (> struct> node**)> malloc> (> sizeof> (> struct> node*) * mp->kapacitet);> > return> ;> }> int> hashFunction(> struct> hashMap* mp,> char> * key) {> > int> bucketIndex;> > int> sum = 0, factor = 31;> > for> (> int> i = 0; i <> strlen> (key); i++) {> > // sum = sum + (ascii value of> > // char * (primeNumber ^ x))...> > // where x = 1, 2, 3....n> > sum = ((sum % mp->kapacitet) + (((> int> )key[i]) * factor) % mp->kapacitet) % mp->kapacitet;> > // factor = factor * prime> > // number....(prime> > // number) ^ x> > factor = ((factor % __INT16_MAX__) * (31 % __INT16_MAX__)) % __INT16_MAX__;> > }> > bucketIndex = sum;> > return> bucketIndex;> }> void> insert(> struct> hashMap* mp,> char> * key,> char> * value) {> > // Getting bucket index for the given> > // key - value pair> > int> bucketIndex = hashFunction(mp, key);> > struct> node* newNode = (> struct> node*)> malloc> (> > // Creating a new node> > sizeof> (> struct> node));> > // Setting value of node> > setNode(newNode, key, value);> > // Bucket index is empty....no collision> > if> (mp->arr[bucketIndex] == NULL) {> > mp->arr[bucketIndex] = newNode;> > }> > // Collision> > else> {> > // Adding newNode at the head of> > // linked list which is present> > // at bucket index....insertion at> > // head in linked list> > newNode->nästa = mp->arr[bucketIndex];> > mp->arr[bucketIndex] = newNode;> > }> > return> ;> }> void> deleteKey(> struct> hashMap* mp,> char> * key) {> > // Getting bucket index for the> > // given key> > int> bucketIndex = hashFunction(mp, key);> > struct> node* prevNode = NULL;> > // Points to the head of> > // linked list present at> > // bucket index> > struct> node* currNode = mp->arr[bucketIndex];> > while> (currNode != NULL) {> > // Key is matched at delete this> > // node from linked list> > if> (> strcmp> (key, currNode->nyckel) == 0) {> > // Head node> > // deletion> > if> (currNode == mp->arr[bucketIndex]) {> > mp->arr[bucketIndex] = currNode->nästa;> > }> > // Last node or middle node> > else> {> > prevNode->nästa = currNode->nästa;> }> free> (currNode);> break> ;> }> prevNode = currNode;> > currNode = currNode->nästa;> > }> return> ;> }> char> * search(> struct> hashMap* mp,> char> * key) {> // Getting the bucket index for the given key> int> bucketIndex = hashFunction(mp, key);> // Head of the linked list present at bucket index> struct> node* bucketHead = mp->arr[bucketIndex];> while> (bucketHead != NULL) {> > > // Key is found in the hashMap> > if> (> strcmp> (bucketHead->nyckel, nyckel) == 0) {> > return> bucketHead->värde;> > }> > > bucketHead = bucketHead->nästa;> }> // If no key found in the hashMap equal to the given key> char> * errorMssg = (> char> *)> malloc> (> sizeof> (> char> ) * 25);> strcpy> (errorMssg,> 'Oops! No data found.
'> );> return> errorMssg;> }> // Drivers code> int> main()> {> // Initialize the value of mp> struct> hashMap* mp = (> struct> hashMap*)> malloc> (> sizeof> (> struct> hashMap));> initializeHashMap(mp);> insert(mp,> 'Yogaholic'> ,> 'Anjali'> );> insert(mp,> 'pluto14'> ,> 'Vartika'> );> insert(mp,> 'elite_Programmer'> ,> 'Manish'> );> insert(mp,> 'GFG'> ,> 'techcodeview.com'> );> insert(mp,> 'decentBoy'> ,> 'Mayank'> );> printf> (> '%s
'> , search(mp,> 'elite_Programmer'> ));> printf> (> '%s
'> , search(mp,> 'Yogaholic'> ));> printf> (> '%s
'> , search(mp,> 'pluto14'> ));> printf> (> '%s
'> , search(mp,> 'decentBoy'> ));> printf> (> '%s
'> , search(mp,> 'GFG'> ));> // Key is not inserted> printf> (> '%s
'> , search(mp,> 'randomKey'> ));> printf> (> '
After deletion :
'> );> // Deletion of key> deleteKey(mp,> 'decentBoy'> );> // Searching the deleted key> printf> (> '%s
'> , search(mp,> 'decentBoy'> ));> return> 0;> }> |
Produktion
Manish Anjali Vartika Mayank techcodeview.com Oops! No data found. After deletion : Oops! No data found.
Förklaring:
- infogning: Infogar nyckel-värdeparet i spetsen av en länkad lista som finns i det givna hinkindexet. hashFunction: Ger hinkindex för den givna nyckeln. Vår hash-funktion = ASCII-värdet för tecknet * primeNumber x . Primtalet i vårt fall är 31 och värdet på x ökar från 1 till n för på varandra följande tecken i en nyckel. radering: Tar bort nyckel-värdepar från hashtabellen för den givna nyckeln. Den tar bort noden från den länkade listan som innehåller nyckel-värdeparet. Sök: Sök efter värdet på den givna nyckeln.
- Denna implementering använder inte rehashing-konceptet. Det är en uppsättning länkade listor med fast storlek.
- Nyckel och värde är båda strängar i det givna exemplet.
Tidskomplexitet och rymdkomplexitet:
Tidskomplexiteten för insättning och radering av hashtabeller är O(1) i genomsnitt. Det finns någon matematisk beräkning som bevisar det.
- Tidskomplexitet för insättning: I genomsnittsfallet är den konstant. I värsta fall är det linjärt. Sökningens tidskomplexitet: I genomsnittsfallet är den konstant. I värsta fall är det linjärt. Tidskomplexitet för radering: I genomsnitt är den konstant. I värsta fall är det linjärt. Rymdkomplexitet: O(n) eftersom det har n antal element.
Relaterade artiklar:
- Separat kedjekollisionshanteringsteknik i hashing.