Hur skapar man en DataFrame i Python?
En dataram är en tvådimensionell samling av data. Det är en datastruktur där data lagras i tabellform. Datauppsättningar är ordnade i rader och kolumner; vi kan lagra flera datamängder i dataramen. Vi kan utföra olika aritmetiska operationer, som att lägga till kolumn/radval och kolumner/rader i dataramen.
I Python fungerar en DataFrame, en central komponent i Pandas-biblioteket, som en omfattande tvådimensionell databehållare. Den liknar en tabell och kapslar in data med klarhet och använder rader och kolumner, var och en utrustad med ett distinkt index. Dess mångsidighet tillåter inkvartering av olika datatyper inom kolumner, vilket ger flexibilitet vid hantering av komplexa datauppsättningar.
Pandas DataFrames ger användarna ett brett utbud av funktioner. Från skapandet av strukturerad data med hjälp av ordböcker eller andra datastrukturer till att använda robust indexering för sömlös dataåtkomst, Pandas underlättar enkel datamanipulation. Biblioteket tillhandahåller ett intuitivt gränssnitt för att utföra operationer som att filtrera rader baserat på villkor, gruppera data för aggregering och utföra statistiska analyser med lätthet.
Vi kan importera DataFrames från den externa lagringen; dessa lagringar kan kallas SQL Databas, CSV-fil och en Excel-fil. Vi kan också använda listor, ordbok, och från en lista med ordbok, etc.
I den här handledningen kommer vi att lära oss att skapa dataramen på flera sätt. Låt oss förstå dessa olika sätt.
Först måste vi installera pandasbiblioteket i Pytonorm miljö.
En tom dataram
Vi kan skapa en grundläggande tom Dataframe. Dataframe-konstruktorn måste anropas för att skapa DataFrame. Låt oss förstå följande exempel.
Exempel -
# Here, we are importing the pandas library as pd import pandas as pd # Here, we are Calling DataFrame constructor df = pd.DataFrame() print(df) # here, we are printing the dataframe
Produktion:
Empty DataFrame Columns: [] Index: []
Metod - 2: Skapa en dataram med hjälp av List
Vi kan skapa en dataram med en enda lista eller lista med listor. Låt oss förstå följande exempel.
Exempel -
# Here, we are importing the pandas library as pd import pandas as pd # Here, we are declaring the string values in the list lst = ['Java', 'Python', 'C', 'C++', 'JavaScript', 'Swift', 'Go'] # Here, we are calling DataFrame constructor on list dframe = pd.DataFrame(lst) print(dframe) # here, we are printing the dataframe
Produktion:
0 Java 1 Python 2 C 3 C++ 4 JavaScript 5 Swift 6 Go
Förklaring:
- Importera pandor: importera pandor som pd importerar Pandas bibliotek och kallar det som pd för korthet.
- Skapa lista: lst är en sammanfattning som innehåller strängvärden som adresserar programmeringsdialekter.
- DataFrame Development: pd.DataFrame(lst) bygger en DataFrame från den sammanfattade lst. Naturligtvis, när en ensam genomgång ges, gör Pandas en DataFrame med en ensam sektion.
- Utskrift av DataFrame: print(dframe) skriver ut den efterföljande DataFrame.
Metod - 3: Skapa dataram från dict of ndarray/lists
Dict av ndarray/lists kan användas för att skapa en dataram, alla ndarray måste vara av samma längd. Indexet kommer att vara ett område(n) som standard; där n anger arraylängden. Låt oss förstå följande exempel.
Exempel -
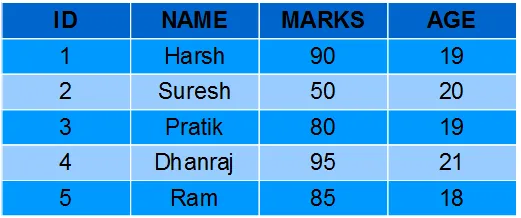
# Here, we are importing the pandas library as pd import pandas as pd # Here, we are assigning the data of lists. data = {'Name': ['Tom', 'Joseph', 'Krish', 'John'], 'Age': [20, 21, 19, 18]} # Here, we are creating the DataFrame df = pd.DataFrame(data) # here, we are printing the dataframe # Here, we are printing the output. print(df) # here, we are printing the dataframe Produktion:
Name Age 0 Tom 20 1 Joseph 21 2 Krish 19 3 John 18
Förklaring:
- Importera pandor: importera pandor som pd importerar Pandas-biblioteket och kallar det pd.
- Skapa ordbok: information är en ordreferens där nycklar är segmentnamn ('Namn' och 'Ålder'), och värden är poster som innehåller relaterad information.
- DataFrame Development: pd.DataFrame(data) bygger en DataFrame från ordreferensen. Nycklarna blir avsnittsnamn och sammanfattningarna blir segment.
- Utskrift av DataFrame: print(df) skriver ut den efterföljande DataFrame.
Metod - 4: Skapa en indexdataram med hjälp av arrayer
Låt oss förstå följande exempel för att skapa indexdataramen med hjälp av arrayer.
Exempel -
# Here, we are implementing the DataFrame using arrays. import pandas as pd # Here, we are importing the pandas library as pd # Here, we are assigning the data of lists. data = {'Name':['Renault', 'Duster', 'Maruti', 'Honda City'], 'Ratings':[9.0, 8.0, 5.0, 3.0]} # Here, we are creating the pandas DataFrame. df = pd.DataFrame(data, index =['position1', 'position2', 'position3', 'position4']) # Here, we are printing the data print(df) Produktion:
Name Ratings position1 Renault 9.0 position2 Duster 8.0 position3 Maruti 5.0 position4 Honda City 3.0
Förklaring:
- Importera pandor: importera pandor som pd importerar Pandas-biblioteket och kallar det pd.
- Skapa ordbok: information är en ordreferens där nycklar är segmentnamn ('Namn' och 'Utvärderingar'), och värden är poster som innehåller relaterad information.
- DataFrame-utveckling: pd.DataFrame(data, index=['position1', 'position2', 'position3', 'position4']) bygger en DataFrame från ordreferensen. Den fördefinierade listan tilldelas raderna.
- Utskrift av DataFrame: print(df) skriver ut den efterföljande DataFrame.
Metod - 5: Skapa dataram från listan över diktat
Vi kan skicka listorna med ordböcker som indata för att skapa Pandas dataram. Kolumnnamnen tas som nycklar som standard. Låt oss förstå följande exempel.
Exempel -
# Here, we are implementing an example to create # Pandas DataFrame by using the lists of dicts. import pandas as pd # Here, we are importing the pandas library as pd # Here, we are assigning the values to lists. data = [{'A': 10, 'B': 20, 'C':30}, {'x':100, 'y': 200, 'z': 300}] # Here, we are creating the DataFrame. df = pd.DataFrame(data) # Here, we are printing the data of the dataframe print(df) Produktion:
A B C x y z 0 10.0 20.0 30.0 NaN NaN NaN 1 NaN NaN NaN 100.0 200.0 300.0
Låt oss förstå ett annat exempel för att skapa pandas dataram från lista över ordböcker med både radindex och kolumnindex.
Förklaring:
- Importera pandor: importera pandor som pd importerar Pandas-biblioteket och kallar det pd.
- Skapa lista och ordbok: information är en sammanfattning där varje komponent är en ordreferens som adresserar en kolumn i DataFrame. Nycklarna till ordreferenserna blir segmentnamn.
- DataFrame-utveckling: pd.DataFrame(data) bygger en DataFrame från sammanfattningen av ordreferenser. Nycklarna till ordet referenser blir sektioner, och kvaliteterna blir informationen i DataFrame.
- Utskrift av DataFrame: print(df) skriver ut den efterföljande DataFrame.
Exempel - 2:
# Here, we are importing the pandas library as pd import pandas as pd # Here, we are assigning the values to the lists. data = [{'x': 1, 'y': 2}, {'A': 15, 'B': 17, 'C': 19}] # Here, we are declaring the two column indices, values same as the dictionary keys dframe1 = pd.DataFrame(data, index =['first', 'second'], columns =['x', 'y']) # Here, we are declaring the variable dframe1 with the parameters data and the indexes # Here, we are declaring the two column indices with # one index with other name dframe2 = pd.DataFrame(data, index =['first', 'second'], columns =['x', 'y1']) # Here, we are declaring the variable dframe2 with the parameters data and the indexes # Here, we are printing the first data frame i.e., dframe1 print (dframe1, '
') # Here, we are printing the first data frame i.e., dframe2 print (dframe2) Produktion:
x y first 1.0 2.0 second NaN NaN x y1 first 1.0 NaN second NaN NaN
Förklaring:
Panda-biblioteket används för att göra två omisskännliga DataFrames, menade som dframe1 och dframe2, med början från en sammanfattning av ordreferenser med namnet information. Dessa ordreferenser fungerar som skildringar av individuella linjer inuti DataFrames, där nycklarna relaterar till segmentnamn och de relaterade egenskaperna adresserar relevant information. Den underliggande DataFrame, dframe1, startas upp med explicita linjefiler ('första' och 'andra') och sektionsposter ('x' och 'y'). Således skapas en andra DataFrame, dframe2, med hjälp av liknande informationsinsamling men med en skillnad i avsnittsfiler, uttryckligen betecknade som 'x' och 'y1'. Koden stängs genom att skriva ut båda DataFrames till kontrollcentret, vilket förtydligar de särskilda sektionsdesignerna för varje DataFrame. Den här koden fylls i som en omfattande översikt över skapande och kontroll av DataFrame inuti pandas-biblioteket, och erbjuder erfarenheter av hur varianter i sektionsposter kan exekveras.
Exempel - 3
# The example is to create # Pandas DataFrame by passing lists of # Dictionaries and row indices. import pandas as pd # Here, we are importing the pandas library as pd # assign values to lists data = [{'x': 2, 'z':3}, {'x': 10, 'y': 20, 'z': 30}] # Creates padas DataFrame by passing # Lists of dictionaries and row index. dframe = pd.DataFrame(data, index =['first', 'second']) # Print the dataframe print(dframe) Produktion:
x y z first 2 NaN 3 second 10 20.0 30
Förklaring:
I denna Python-kod utvecklas en Pandas DataFrame som använder pandasbiblioteket genom att ordna ordreferenser och bestämma kolumnposter. Cykeln börjar med importen av pandasbiblioteket, tilldelat med det falska namnet 'pd' för korthetens skull. Följaktligen karaktäriseras en sammanfattning av ordreferenser benämnd information, där varje ordreferens adresserar en rad i DataFrame. Nycklarna inuti dessa ordreferenser betyder segmentnamnen, medan de relaterade värdena indikerar de viktiga informationsbitarna.
DataFrame, indikerad som dframe, görs sedan genom att använda pd.DataFrame()-konstruktorn, som konsoliderar den angivna informationen och uttryckligen ställer in linjeposterna till 'första' och 'andra'. Den efterföljande DataFrame visar en jämn design med sektioner som heter 'x', 'y' och 'z'. Eventuella saknade egenskaper betecknas som 'NaN.'
Metod - 6: Skapa dataram med hjälp av zip()-funktionen
Zip()-funktionen används för att slå samman de två listorna. Låt oss förstå följande exempel.
Exempel -
# The example is to create # pandas dataframe from lists using zip. import pandas as pd # Here, we are importing the pandas library as pd # List1 Name = ['tom', 'krish', 'arun', 'juli'] # List2 Marks = [95, 63, 54, 47] # two lists. # and merge them by using zip(). list_tuples = list(zip(Name, Marks)) # Assign data to tuples. print(list_tuples) # Converting lists of tuples into # pandas Dataframe. dframe = pd.DataFrame(list_tuples, columns=['Name', 'Marks']) # Print data. print(dframe)
Produktion:
[('john', 95), ('krish', 63), ('arun', 54), ('juli', 47)] Name Marks 0 john 95 1 krish 63 2 arun 54 3 juli 47
Förklaring:
Den här Python-koden visar produktionen av en Pandas DataFrame från två poster, specifikt 'Name' och 'Stamps', genom att använda pandasbiblioteket och komprimeringsförmågan. Efter importen av pandas-biblioteket karakteriseras 'Name'- och 'Checks'-posterna, som adresserar de ideala delarna av DataFrame. Zip-förmågan används för att jämföra komponenter från dessa sammanställningar till tuples, och rama in en annan sammanfattning som heter list_tuples.
Koden skriver sedan ut en sammanfattning av tupler för att ge en kort titt på den sammanfogade informationen. Följaktligen görs en Pandas DataFrame med namnet dframe med hjälp av pd.DataFrame()-konstruktorn, där sammanfattningen av tupler ändras till en organiserad jämn konfiguration. Segmenten 'Namn' och 'Stämplar' tilldelas otvetydigt under denna DataFrame-skapandeprocess.
Metod - 7: Skapa Dataframe från Dicts of series
Ordlistan kan skickas för att skapa en dataram. Vi kan använda Dicts of series där det efterföljande indexet är föreningen av alla serier av passerade indexvärden. Låt oss förstå följande exempel.
Exempel -
# Pandas Dataframe from Dicts of series. import pandas as pd # Here, we are importing the pandas library as pd # Initialize data to Dicts of series. d = {'Electronics' : pd.Series([97, 56, 87, 45], index =['John', 'Abhinay', 'Peter', 'Andrew']), 'Civil' : pd.Series([97, 88, 44, 96], index =['John', 'Abhinay', 'Peter', 'Andrew'])} # creates Dataframe. dframe = pd.DataFrame(d) # print the data. print(dframe) Produktion:
Electronics Civil John 97 97 Abhinay 56 88 Peter 87 44 Andrew 45 96
Förklaring:
I denna Python-kod är en Pandas DataFrame gjord av ordreferenser från serier som använder pandasbiblioteket. Två ämnen, 'Prylar' och 'Common', behandlas som sektioner, och individuella poäng med explicita filer koordineras till en DataFrame som heter dframe. Den efterföljande enkla konstruktionen skrivs ut till kontrollcentret och visar en kompakt teknik för att koordinera och undersöka markerad information med hjälp av pandor.
I den här handledningen har vi diskuterat de olika sätten att skapa DataFrames.