Metoda Pandas DataFrame corr().

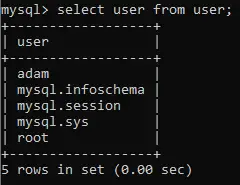
Pande dataframe.corr() se uporablja za iskanje parne korelacije vseh stolpcev v Pandas Dataframe v Pythonu. Kaj NaN vrednosti so samodejno izključene. Če želite prezreti vse neštevilske vrednosti, uporabite parameter numeric_only = True. V tem članku bomo spoznali metodo DataFrame.corr(). Python .
Sintaksa metode Pandas DataFrame corr().
Sintaksa: DataFrame.corr(self, method='pearson', min_periods=1, numeric_only = False)
Parametri:
- metoda:
- pearson: standardni korelacijski koeficient
- kendall: korelacijski koeficient Kendall Tau
- spearman: korelacija ranga spearman
- min_obdobja: Najmanjše število opazovanj, potrebnih na par stolpcev za veljaven rezultat. Trenutno na voljo samo za korelacijo Pearson in spearman
- numeric_only : ali naj se upravlja samo s številskimi vrednostmi ali ne. Privzeto je nastavljen na False.
Vrne: count :y : DataFrame
Metoda korelacije podatkov Pandas corr().
Dobra korelacija je odvisna od uporabe, vendar lahko z gotovostjo rečemo, da imate vsaj 0,6 (ali -0,6), da jo imenujemo dobra korelacija. Preprost primer, ki prikazuje, kako deluje korelacija Python .
Python3
import> pandas as pd> df> => {> > 'Array_1'> : [> 30> ,> 70> ,> 100> ],> > 'Array_2'> : [> 65.1> ,> 49.50> ,> 30.7> ]> }> data> => pd.DataFrame(df)> print> (data.corr())> |
Izhod
Array_1 Array_2 Array_1 1.000000 -0.990773 Array_2 -0.990773 1.000000
Ustvarjanje vzorčnega podatkovnega okvira
Tiskanje prvih 10 vrstic Dataframe.
Opomba: Korelacija spremenljivke s samo seboj je 1. Za povezavo do datoteke CSV, uporabljene v kodi, kliknite tukaj
Python3
# importing pandas as pd> import> pandas as pd> # Making data frame from the csv file> df> => pd.read_csv(> 'nba.csv'> )> # Printing the first 10 rows of the data frame for visualization> df[:> 10> ]> |
Izhod

Primeri metode Python Pandas DataFrame corr().
Poiščite korelacijo med stolpci z uporabo pearsonove metode
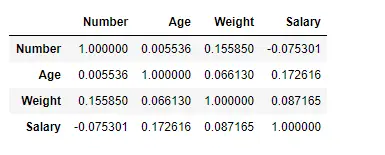
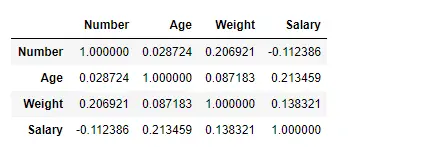
Tu uporabljamo funkcijo corr(), da poiščemo korelacijo med stolpci v Dataframeu z uporabo metode Pearson. V Dataframeu imamo samo štiri številske stolpce. Izhodni podatkovni okvir je mogoče razlagati kot za katero koli celico, korelacija spremenljivke vrstice s spremenljivko stolpca je vrednost celice. Kot smo že omenili, je korelacija spremenljivke s samo seboj 1. Zato so vse diagonalne vrednosti 1,00.
Python3
# To find the correlation among> # the columns using pearson method> df.corr(method> => 'pearson'> )> |
Izhod
Poiščite korelacijo med stolpci z uporabo Kendallove metode
Uporabite funkcijo Pandas df.corr(), da poiščete korelacijo med stolpci v Dataframeu z metodo 'kendall'. Izhodni podatkovni okvir je mogoče razlagati kot za katero koli celico, korelacija spremenljivke vrstice s spremenljivko stolpca je vrednost celice. Kot smo že omenili, je korelacija spremenljivke s samo seboj 1. Zato so vse diagonalne vrednosti 1,00.
Python3
# importing pandas as pd> import> pandas as pd> # Making data frame from the csv file> df> => pd.read_csv(> 'nba.csv'> )> # To find the correlation among> # the columns using kendall method> df.corr(method> => 'kendall'> )> |
Izhod