Práca so súbormi Excel pomocou Pandas

Tabuľky programu Excel sú veľmi inštinktívne a užívateľsky prívetivé, vďaka čomu sú ideálne na manipuláciu s veľkými súbormi údajov aj pre menej technických ľudí. Ak hľadáte miesta, kde sa môžete naučiť manipulovať a automatizovať veci v súboroch Excelu Python , nehľadaj ďalej. Ste na správnom mieste.
V tomto článku sa dozviete, ako používať pandy pracovať s tabuľkami Excel. V tomto článku sa dozvieme o:
- Čítať Súbor Excel pomocou Pandy v Pythone
- Inštalácia a import Pandy
- Čítanie viacerých hárkov Excelu pomocou Pandas
- Aplikácia rôznych funkcií Pandas
Čítanie súboru Excel pomocou Pandas v Pythone
Inštalácia Pandy
Na inštaláciu Pandy v Pythone môžeme použiť nasledujúci príkaz v príkazovom riadku:
pip install pandas
Ak chcete nainštalovať Pandy v Anaconda, môžeme použiť nasledujúci príkaz v Anaconda Terminal:
conda install pandas
Import Pandy
Najprv musíme importovať modul Pandas, čo je možné vykonať spustením príkazu:
Python3
import> pandas as pd> |
Vstupný súbor: Predpokladajme, že súbor programu Excel vyzerá takto
Hárok 1:

List 1
Hárok 2:
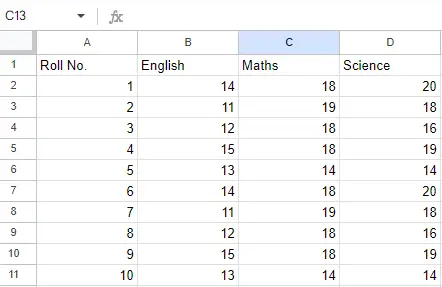
List 2
Teraz môžeme importovať súbor Excel pomocou funkcie read_excel v Pandas na čítanie súboru Excel pomocou Pandas v Pythone. Druhý príkaz načíta údaje z Excelu a uloží ich do dátového rámca pandas, ktorý predstavuje premenná newData.
Python3
df> => pd.read_excel(> 'Example.xlsx'> )> print> (df)> |
Výkon:
Roll No. English Maths Science 0 1 19 13 17 1 2 14 20 18 2 3 15 18 19 3 4 13 14 14 4 5 17 16 20 5 6 19 13 17 6 7 14 20 18 7 8 15 18 19 8 9 13 14 14 9 10 17 16 20
Načítanie viacerých listov pomocou metódy Concat().
Ak je v zošite programu Excel viacero hárkov, príkaz importuje údaje z prvého hárka. Ak chcete vytvoriť dátový rámec so všetkými hárkami v zošite, najjednoduchším spôsobom je vytvoriť rôzne dátové rámce samostatne a potom ich zreťaziť. Metóda read_excel preberá argument názov_hárka a index_col, kde môžeme určiť hárok, z ktorého by mal byť rám vyrobený, a index_col určuje stĺpec nadpisu, ako je uvedené nižšie:
Príklad:
Tretí príkaz spája oba listy. Teraz, aby sme skontrolovali celý dátový rámec, môžeme jednoducho spustiť nasledujúci príkaz:
Python3
file> => 'Example.xlsx'> sheet1> => pd.read_excel(> file> ,> > sheet_name> => 0> ,> > index_col> => 0> )> sheet2> => pd.read_excel(> file> ,> > sheet_name> => 1> ,> > index_col> => 0> )> # concatinating both the sheets> newData> => pd.concat([sheet1, sheet2])> print> (newData)> |
Výkon:
Roll No. English Maths Science 1 19 13 17 2 14 20 18 3 15 18 19 4 13 14 14 5 17 16 20 6 19 13 17 7 14 20 18 8 15 18 19 9 13 14 14 10 17 16 20 1 14 18 20 2 11 19 18 3 12 18 16 4 15 18 19 5 13 14 14 6 14 18 20 7 11 19 18 8 12 18 16 9 15 18 19 10 13 14 14
Metódy Head() a Tail() v Pandas
Na zobrazenie 5 stĺpcov zhora a zospodu dátového rámca môžeme spustiť príkaz. Toto hlava () a chvost() metóda tiež berie argumenty ako čísla pre počet stĺpcov, ktoré sa majú zobraziť.
Python3
print> (newData.head())> print> (newData.tail())> |
Výkon:
English Maths Science Roll No. 1 19 13 17 2 14 20 18 3 15 18 19 4 13 14 14 5 17 16 20 English Maths Science Roll No. 6 14 18 20 7 11 19 18 8 12 18 16 9 15 18 19 10 13 14 14
metóda Shape().
The metóda shape(). možno použiť na zobrazenie počtu riadkov a stĺpcov v dátovom rámci takto:
Python3
newData.shape> |
Výkon:
(20, 3)
Metóda Sort_values() v Pandas
Ak niektorý stĺpec obsahuje číselné údaje, môžeme tento stĺpec zoradiť pomocou sort_values() metóda v pandách takto:
Python3
sorted_column> => newData.sort_values([> 'English'> ], ascending> => False> )> |
Teraz predpokladajme, že chceme prvých 5 hodnôt zoradeného stĺpca, môžeme tu použiť metódu head():
Python3
sorted_column.head(> 5> )> |
Výkon:
English Maths Science Roll No. 1 19 13 17 6 19 13 17 5 17 16 20 10 17 16 20 3 15 18 19
Môžeme to urobiť pomocou ľubovoľného číselného stĺpca dátového rámca, ako je uvedené nižšie:
Python3
newData[> 'Maths'> ].head()> |
Výkon:
Roll No. 1 13 2 20 3 18 4 14 5 16 Name: Maths, dtype: int64
Metóda Pandas Describe().
Teraz predpokladajme, že naše údaje sú väčšinou číselné. Štatistické informácie ako priemer, max, min atď. o dátovom rámci môžeme získať pomocou opísať () metóda, ako je uvedené nižšie:
Python3
newData.describe()> |
Výkon:
English Maths Science count 20.00000 20.000000 20.000000 mean 14.30000 16.800000 17.500000 std 2.29645 2.330575 2.164304 min 11.00000 13.000000 14.000000 25% 13.00000 14.000000 16.000000 50% 14.00000 18.000000 18.000000 75% 15.00000 18.000000 19.000000 max 19.00000 20.000000 20.000000
Môžete to urobiť aj samostatne pre všetky číselné stĺpce pomocou nasledujúceho príkazu:
Python3
newData[> 'English'> ].mean()> |
Výkon:
14.3
Pomocou príslušných metód je možné vypočítať aj ďalšie štatistické informácie. Podobne ako v Exceli je možné použiť aj vzorce a vytvoriť vypočítané stĺpce takto:
Python3
newData[> 'Total Marks'> ]> => > newData[> 'English'> ]> +> newData[> 'Maths'> ]> +> newData[> 'Science'> ]> newData[> 'Total Marks'> ].head()> |
Výkon:
Roll No. 1 49 2 52 3 52 4 41 5 53 Name: Total Marks, dtype: int64
Po operácii s dátami v dátovom rámci môžeme dáta exportovať späť do excelovského súboru metódou to_excel. Na tento účel musíme špecifikovať výstupný súbor Excel, do ktorého sa majú zapísať transformované údaje, ako je uvedené nižšie:
Python3
newData.to_excel(> 'Output File.xlsx'> )> |
Výkon:
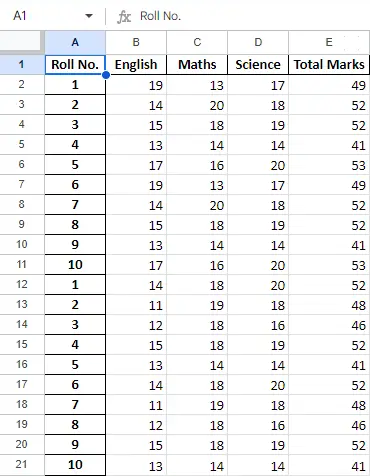
Záverečný list