Implementácia hash tabuľky v C/C++ pomocou samostatného reťazenia
Úvod:
Skracovače adries URL sú príkladom hashovania, pretože mapujú veľké adresy URL na malé
Niektoré príklady hashovacích funkcií:
- kľúč % počet vedier
- ASCII hodnota znaku * Prvočíslo X . Kde x = 1, 2, 3….n
- Môžete si vytvoriť vlastnú hašovaciu funkciu, ale mala by to byť dobrá hašovacia funkcia, ktorá dáva menší počet kolízií.

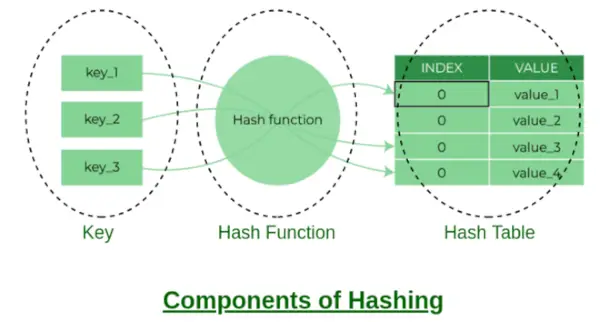
Komponenty hashovania
Index segmentu:
Hodnota vrátená funkciou Hash je index segmentu pre kľúč v samostatnej metóde reťazenia. Každý index v poli sa nazýva bucket, keďže je to bucket prepojeného zoznamu.
Opakovanie:
Rehashing je koncept, ktorý znižuje kolízie, keď sa prvky v aktuálnej hašovacej tabuľke zvýšia. Vytvorí nové pole s dvojnásobnou veľkosťou a skopíruje doň predchádzajúce prvky poľa a je to ako vnútorné fungovanie vektora v C++. Je zrejmé, že funkcia hash by mala byť dynamická, pretože by mala odrážať určité zmeny pri zvýšení kapacity. Hašovacia funkcia zahŕňa kapacitu hašovacej tabuľky v nej, preto pri kopírovaní hodnôt kľúča z predchádzajúcej hašovacej funkcie poľa poskytuje rôzne indexy segmentov, pretože závisí od kapacity (segmentov) hašovacej tabuľky. Vo všeobecnosti platí, že keď je hodnota faktora zaťaženia väčšia ako 0,5, vykonajú sa rehashingy.
- Zdvojnásobte veľkosť poľa.
- Skopírujte prvky predchádzajúceho poľa do nového poľa. Pri kopírovaní každého uzla do nového poľa znova používame hašovaciu funkciu, takže to zníži kolíziu.
- Odstráňte predchádzajúce pole z pamäte a nasmerujte interný ukazovateľ poľa hash mapy na toto nové pole.
- Vo všeobecnosti platí, že faktor zaťaženia = počet prvkov v hash mape / celkový počet segmentov (kapacita).
Zrážka:
Kolízia je situácia, keď index vedra nie je prázdny. Znamená to, že v tomto indexe segmentu sa nachádza hlavička prepojeného zoznamu. Máme dve alebo viac hodnôt, ktoré sa mapujú na rovnaký index segmentu.
Hlavné funkcie v našom programe
- Vkladanie
- Vyhľadávanie
- Hash funkcia
- Odstrániť
- Rehashing
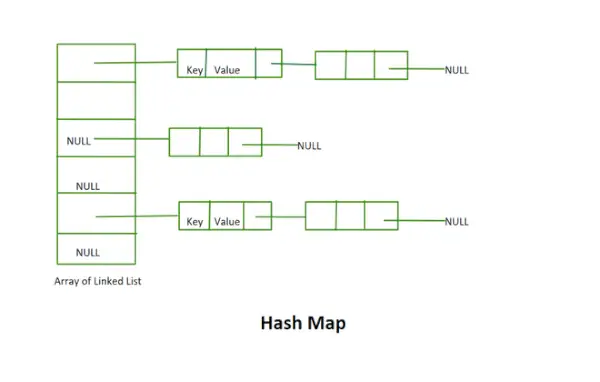
Hash Map
Implementácia bez rehašovania:
C
#include> #include> #include> // Linked List node> struct> node {> > // key is string> > char> * key;> > // value is also string> > char> * value;> > struct> node* next;> };> // like constructor> void> setNode(> struct> node* node,> char> * key,> char> * value)> {> > node->kľúč = kľúč;> > node->hodnota = hodnota;> > node->dalsi = NULL;> > return> ;> };> struct> hashMap {> > // Current number of elements in hashMap> > // and capacity of hashMap> > int> numOfElements, capacity;> > // hold base address array of linked list> > struct> node** arr;> };> // like constructor> void> initializeHashMap(> struct> hashMap* mp)> {> > // Default capacity in this case> > mp->kapacita = 100;> > mp->numOfElements = 0;> > // array of size = 1> > mp->arr = (> struct> node**)> malloc> (> sizeof> (> struct> node*)> > * mp->kapacita);> > return> ;> }> int> hashFunction(> struct> hashMap* mp,> char> * key)> {> > int> bucketIndex;> > int> sum = 0, factor = 31;> > for> (> int> i = 0; i <> strlen> (key); i++) {> > // sum = sum + (ascii value of> > // char * (primeNumber ^ x))...> > // where x = 1, 2, 3....n> > sum = ((sum % mp->kapacita)> > + (((> int> )key[i]) * factor) % mp->kapacita)> > % mp->kapacita;> > // factor = factor * prime> > // number....(prime> > // number) ^ x> > factor = ((factor % __INT16_MAX__)> > * (31 % __INT16_MAX__))> > % __INT16_MAX__;> > }> > bucketIndex = sum;> > return> bucketIndex;> }> void> insert(> struct> hashMap* mp,> char> * key,> char> * value)> {> > // Getting bucket index for the given> > // key - value pair> > int> bucketIndex = hashFunction(mp, key);> > struct> node* newNode = (> struct> node*)> malloc> (> > // Creating a new node> > sizeof> (> struct> node));> > // Setting value of node> > setNode(newNode, key, value);> > // Bucket index is empty....no collision> > if> (mp->arr[bucketIndex] == NULL) {> > mp->arr[bucketIndex] = newNode;> > }> > // Collision> > else> {> > // Adding newNode at the head of> > // linked list which is present> > // at bucket index....insertion at> > // head in linked list> > newNode->next = mp->arr[bucketIndex];> > mp->arr[bucketIndex] = newNode;> > }> > return> ;> }> void> delete> (> struct> hashMap* mp,> char> * key)> {> > // Getting bucket index for the> > // given key> > int> bucketIndex = hashFunction(mp, key);> > struct> node* prevNode = NULL;> > // Points to the head of> > // linked list present at> > // bucket index> > struct> node* currNode = mp->arr[bucketIndex];> > while> (currNode != NULL) {> > // Key is matched at delete this> > // node from linked list> > if> (> strcmp> (key, currNode->kľúč) == 0) {> > // Head node> > // deletion> > if> (currNode == mp->arr[bucketIndex]) {> > mp->arr[bucketIndex] = currNode->next;> > }> > // Last node or middle node> > else> {> > prevNode->next = currNode->next;> > }> > free> (currNode);> > break> ;> > }> > prevNode = currNode;> > currNode = currNode->ďalej;> > }> > return> ;> }> char> * search(> struct> hashMap* mp,> char> * key)> {> > // Getting the bucket index> > // for the given key> > int> bucketIndex = hashFunction(mp, key);> > // Head of the linked list> > // present at bucket index> > struct> node* bucketHead = mp->arr[bucketIndex];> > while> (bucketHead != NULL) {> > // Key is found in the hashMap> > if> (bucketHead->kľúč == kľúč) {> > return> bucketHead->hodnota;> > }> > bucketHead = bucketHead->ďalej;> > }> > // If no key found in the hashMap> > // equal to the given key> > char> * errorMssg = (> char> *)> malloc> (> sizeof> (> char> ) * 25);> > errorMssg => 'Oops! No data found.
'> ;> > return> errorMssg;> }> // Drivers code> int> main()> {> > // Initialize the value of mp> > struct> hashMap* mp> > = (> struct> hashMap*)> malloc> (> sizeof> (> struct> hashMap));> > initializeHashMap(mp);> > insert(mp,> 'Yogaholic'> ,> 'Anjali'> );> > insert(mp,> 'pluto14'> ,> 'Vartika'> );> > insert(mp,> 'elite_Programmer'> ,> 'Manish'> );> > insert(mp,> 'GFG'> ,> 'techcodeview.com'> );> > insert(mp,> 'decentBoy'> ,> 'Mayank'> );> > printf> (> '%s
'> , search(mp,> 'elite_Programmer'> ));> > printf> (> '%s
'> , search(mp,> 'Yogaholic'> ));> > printf> (> '%s
'> , search(mp,> 'pluto14'> ));> > printf> (> '%s
'> , search(mp,> 'decentBoy'> ));> > printf> (> '%s
'> , search(mp,> 'GFG'> ));> > // Key is not inserted> > printf> (> '%s
'> , search(mp,> 'randomKey'> ));> > printf> (> '
After deletion :
'> );> > // Deletion of key> > delete> (mp,> 'decentBoy'> );> > printf> (> '%s
'> , search(mp,> 'decentBoy'> ));> > return> 0;> }> |
C++
#include> #include> // Linked List node> struct> node {> > // key is string> > char> * key;> > // value is also string> > char> * value;> > struct> node* next;> };> // like constructor> void> setNode(> struct> node* node,> char> * key,> char> * value) {> > node->kľúč = kľúč;> > node->hodnota = hodnota;> > node->dalsi = NULL;> > return> ;> }> struct> hashMap {> > // Current number of elements in hashMap> > // and capacity of hashMap> > int> numOfElements, capacity;> > // hold base address array of linked list> > struct> node** arr;> };> // like constructor> void> initializeHashMap(> struct> hashMap* mp) {> > // Default capacity in this case> > mp->kapacita = 100;> > mp->numOfElements = 0;> > // array of size = 1> > mp->arr = (> struct> node**)> malloc> (> sizeof> (> struct> node*) * mp->kapacita);> > return> ;> }> int> hashFunction(> struct> hashMap* mp,> char> * key) {> > int> bucketIndex;> > int> sum = 0, factor = 31;> > for> (> int> i = 0; i <> strlen> (key); i++) {> > // sum = sum + (ascii value of> > // char * (primeNumber ^ x))...> > // where x = 1, 2, 3....n> > sum = ((sum % mp->kapacita) + (((> int> )key[i]) * factor) % mp->kapacita) % mp->kapacita;> > // factor = factor * prime> > // number....(prime> > // number) ^ x> > factor = ((factor % __INT16_MAX__) * (31 % __INT16_MAX__)) % __INT16_MAX__;> > }> > bucketIndex = sum;> > return> bucketIndex;> }> void> insert(> struct> hashMap* mp,> char> * key,> char> * value) {> > // Getting bucket index for the given> > // key - value pair> > int> bucketIndex = hashFunction(mp, key);> > struct> node* newNode = (> struct> node*)> malloc> (> > // Creating a new node> > sizeof> (> struct> node));> > // Setting value of node> > setNode(newNode, key, value);> > // Bucket index is empty....no collision> > if> (mp->arr[bucketIndex] == NULL) {> > mp->arr[bucketIndex] = newNode;> > }> > // Collision> > else> {> > // Adding newNode at the head of> > // linked list which is present> > // at bucket index....insertion at> > // head in linked list> > newNode->next = mp->arr[bucketIndex];> > mp->arr[bucketIndex] = newNode;> > }> > return> ;> }> void> deleteKey(> struct> hashMap* mp,> char> * key) {> > // Getting bucket index for the> > // given key> > int> bucketIndex = hashFunction(mp, key);> > struct> node* prevNode = NULL;> > // Points to the head of> > // linked list present at> > // bucket index> > struct> node* currNode = mp->arr[bucketIndex];> > while> (currNode != NULL) {> > // Key is matched at delete this> > // node from linked list> > if> (> strcmp> (key, currNode->kľúč) == 0) {> > // Head node> > // deletion> > if> (currNode == mp->arr[bucketIndex]) {> > mp->arr[bucketIndex] = currNode->next;> > }> > // Last node or middle node> > else> {> > prevNode->next = currNode->next;> }> free> (currNode);> break> ;> }> prevNode = currNode;> > currNode = currNode->ďalej;> > }> return> ;> }> char> * search(> struct> hashMap* mp,> char> * key) {> // Getting the bucket index for the given key> int> bucketIndex = hashFunction(mp, key);> // Head of the linked list present at bucket index> struct> node* bucketHead = mp->arr[bucketIndex];> while> (bucketHead != NULL) {> > > // Key is found in the hashMap> > if> (> strcmp> (bucketHead->kľúč, kľúč) == 0) {> > return> bucketHead->hodnota;> > }> > > bucketHead = bucketHead->ďalej;> }> // If no key found in the hashMap equal to the given key> char> * errorMssg = (> char> *)> malloc> (> sizeof> (> char> ) * 25);> strcpy> (errorMssg,> 'Oops! No data found.
'> );> return> errorMssg;> }> // Drivers code> int> main()> {> // Initialize the value of mp> struct> hashMap* mp = (> struct> hashMap*)> malloc> (> sizeof> (> struct> hashMap));> initializeHashMap(mp);> insert(mp,> 'Yogaholic'> ,> 'Anjali'> );> insert(mp,> 'pluto14'> ,> 'Vartika'> );> insert(mp,> 'elite_Programmer'> ,> 'Manish'> );> insert(mp,> 'GFG'> ,> 'techcodeview.com'> );> insert(mp,> 'decentBoy'> ,> 'Mayank'> );> printf> (> '%s
'> , search(mp,> 'elite_Programmer'> ));> printf> (> '%s
'> , search(mp,> 'Yogaholic'> ));> printf> (> '%s
'> , search(mp,> 'pluto14'> ));> printf> (> '%s
'> , search(mp,> 'decentBoy'> ));> printf> (> '%s
'> , search(mp,> 'GFG'> ));> // Key is not inserted> printf> (> '%s
'> , search(mp,> 'randomKey'> ));> printf> (> '
After deletion :
'> );> // Deletion of key> deleteKey(mp,> 'decentBoy'> );> // Searching the deleted key> printf> (> '%s
'> , search(mp,> 'decentBoy'> ));> return> 0;> }> |
Výkon
Manish Anjali Vartika Mayank techcodeview.com Oops! No data found. After deletion : Oops! No data found.
Vysvetlenie:
- insertion: Vloží pár kľúč – hodnota na začiatok prepojeného zoznamu, ktorý sa nachádza v danom indexe segmentu. hashFunction: Poskytuje index segmentu pre daný kľúč. náš hašovacia funkcia = ASCII hodnota znaku * prvočíslo X . Prvočíslo je v našom prípade 31 a hodnota x sa zvyšuje z 1 na n pre po sebe idúce znaky v kľúči. vymazanie: Odstráni pár kľúč-hodnota z hašovacej tabuľky pre daný kľúč. Vymaže uzol z prepojeného zoznamu, ktorý obsahuje pár kľúč – hodnota. Hľadať: Vyhľadajte hodnotu daného kľúča.
- Táto implementácia nepoužíva koncepciu rehashingu. Ide o pole prepojených zoznamov s pevnou veľkosťou.
- Kľúč aj hodnota sú v danom príklade reťazce.
Časová a priestorová zložitosť:
Časová zložitosť operácií vkladania a vymazávania hašovacích tabuliek je v priemere O(1). Existuje nejaký matematický výpočet, ktorý to dokazuje.
- Časová zložitosť vkladania: V priemernom prípade je konštantná. V najhoršom prípade je lineárny. Časová zložitosť vyhľadávania: V priemernom prípade je konštantná. V najhoršom prípade je lineárny. Časová zložitosť vymazania: V priemerných prípadoch je konštantná. V najhoršom prípade je lineárny. Priestorová zložitosť: O(n), keďže má n počet prvkov.
Súvisiace články:
- Samostatné reťazenie technika spracovania kolízie v hašovaní.