Analiza datelor cu Python
În acest articol, vom discuta despre cum să facem analiza datelor cu Python. Vom discuta despre toate tipurile de analize de date, adică analiza datelor numerice cu NumPy, date tabulare cu Pandas, vizualizarea datelor Matplotlib și analiza datelor exploratorii.
Analiza datelor cu Python
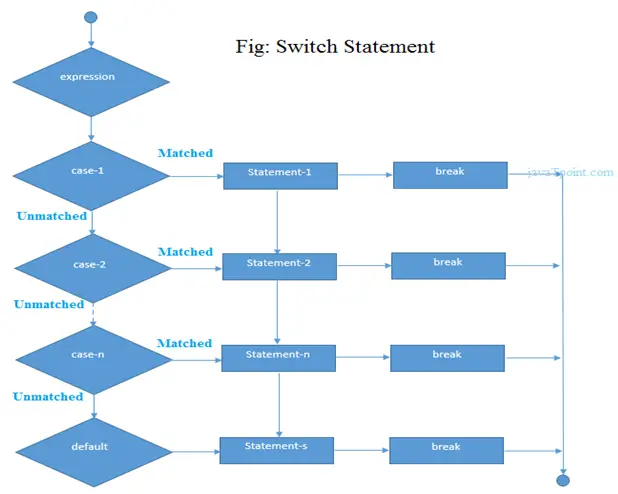
Analiza datelor este tehnica de colectare, transformare și organizare a datelor pentru a face previziuni viitoare și decizii informate bazate pe date. De asemenea, ajută la găsirea posibilelor soluții pentru o problemă de afaceri. Există șase pași pentru analiza datelor. Sunt:
- Întrebați sau specificați cerințele de date
- Pregătiți sau Colectați Date
- Curățați și procesați
- A analiza
- Acțiune
- Act sau Raport
Analiza datelor cu Python
Notă: Pentru a afla mai multe despre acești pași, consultați pagina noastră NumPy este un pachet de procesare a matricei în Python și oferă un obiect matrice multidimensional de înaltă performanță și instrumente pentru lucrul cu aceste matrice. Este pachetul fundamental pentru calculul științific cu Python.
Matrice în NumPy
NumPy Array este un tabel de elemente (de obicei numere), toate de aceleași tipuri, indexate printr-un tuplu de numere întregi pozitive. În Numpy, numărul de dimensiuni ale matricei se numește rangul matricei. Un tuplu de numere întregi care oferă dimensiunea matricei de-a lungul fiecărei dimensiuni este cunoscut sub numele de forma matricei.
Crearea matricei NumPy
Matricele NumPy pot fi create în mai multe moduri, cu diferite ranguri. De asemenea, poate fi creat folosind diferite tipuri de date, cum ar fi liste, tupluri etc. Tipul matricei rezultate este dedus din tipul de elemente din secvențe. NumPy oferă mai multe funcții pentru a crea matrice cu conținut inițial de substituent. Acestea minimizează necesitatea creșterii matricelor, o operațiune costisitoare.
Creați matrice folosind numpy.empty(shape, dtype=float, order=’C’)
Python3import numpy as np b = np.empty(2, dtype = int) print('Matrix b :
', b) a = np.empty([2, 2], dtype = int) print('
Matrix a :
', a) c = np.empty([3, 3]) print('
Matrix c :
', c) Ieșire:

Goliți Matrix folosind panda
Creați matrice folosind numpy.zeros(formă, dtype = Nici unul, ordine = „C”)
Python3import numpy as np b = np.zeros(2, dtype = int) print('Matrix b :
', b) a = np.zeros([2, 2], dtype = int) print('
Matrix a :
', a) c = np.zeros([3, 3]) print('
Matrix c :
', c) Ieșire:
Matrix b : [0 0] Matrix a : [[0 0] [0 0]] Matrix c : [[0. 0. 0.] [0. 0. 0.] [0. 0. 0.]]
Operațiuni pe Numpy Arrays
Operatii aritmetice
- Plus:
import numpy as np # Defining both the matrices a = np.array([5, 72, 13, 100]) b = np.array([2, 5, 10, 30]) # Performing addition using arithmetic operator add_ans = a+b print(add_ans) # Performing addition using numpy function add_ans = np.add(a, b) print(add_ans) # The same functions and operations can be used for # multiple matrices c = np.array([1, 2, 3, 4]) add_ans = a+b+c print(add_ans) add_ans = np.add(a, b, c) print(add_ans)
Ieșire:
[ 7 77 23 130] [ 7 77 23 130] [ 8 79 26 134] [ 7 77 23 130]
- Scădere:
import numpy as np # Defining both the matrices a = np.array([5, 72, 13, 100]) b = np.array([2, 5, 10, 30]) # Performing subtraction using arithmetic operator sub_ans = a-b print(sub_ans) # Performing subtraction using numpy function sub_ans = np.subtract(a, b) print(sub_ans)
Ieșire:
[ 3 67 3 70] [ 3 67 3 70]
- Multiplicare:
import numpy as np # Defining both the matrices a = np.array([5, 72, 13, 100]) b = np.array([2, 5, 10, 30]) # Performing multiplication using arithmetic # operator mul_ans = a*b print(mul_ans) # Performing multiplication using numpy function mul_ans = np.multiply(a, b) print(mul_ans)
Ieșire:
[ 10 360 130 3000] [ 10 360 130 3000]
- Divizia:
import numpy as np # Defining both the matrices a = np.array([5, 72, 13, 100]) b = np.array([2, 5, 10, 30]) # Performing division using arithmetic operators div_ans = a/b print(div_ans) # Performing division using numpy functions div_ans = np.divide(a, b) print(div_ans)
Ieșire:
[ 2.5 14.4 1.3 3.33333333] [ 2.5 14.4 1.3 3.33333333]
Pentru mai multe informații, consultați pagina noastră NumPy – Tutorial operații aritmetice
Indexarea matricei NumPy
Indexarea se poate face în NumPy folosind o matrice ca index. În cazul slice, se returnează o vedere sau o copie superficială a matricei, dar în matricea index este returnată o copie a matricei originale. Matricele Numpy pot fi indexate cu alte matrice sau cu orice altă secvență, cu excepția tuplurilor. Ultimul element este indexat cu -1 secundă ultima cu -2 și așa mai departe.
Indexarea matricei Python NumPy
Python3# Python program to demonstrate # the use of index arrays. import numpy as np # Create a sequence of integers from # 10 to 1 with a step of -2 a = np.arange(10, 1, -2) print('
A sequential array with a negative step:
',a) # Indexes are specified inside the np.array method. newarr = a[np.array([3, 1, 2 ])] print('
Elements at these indices are:
',newarr) Ieșire:
A sequential array with a negative step: [10 8 6 4 2] Elements at these indices are: [4 8 6]
NumPy Array Slicing
Luați în considerare sintaxa x[obj] unde x este matricea și obj este indexul. Obiectul felie este indexul în cazul feliere de bază . Tăierea de bază are loc atunci când obj este:
- un obiect felie care are forma start: stop: step
- un număr întreg
- sau un tuplu de obiecte slice și numere întregi
Toate matricele generate prin tăierea de bază sunt întotdeauna vizualizarea din matricea originală.
Python3# Python program for basic slicing. import numpy as np # Arrange elements from 0 to 19 a = np.arange(20) print('
Array is:
',a) # a[start:stop:step] print('
a[-8:17:1] = ',a[-8:17:1]) # The : operator means all elements till the end. print('
a[10:] = ',a[10:]) Ieșire:
Array is: [ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19] a[-8:17:1] = [12 13 14 15 16] a[10:] = [10 11 12 13 14 15 16 17 18 19]
Elipsis poate fi folosit și împreună cu felierea de bază. Punctele de suspensie (…) este numărul de : obiecte necesare pentru a face un tuplu de selecție de aceeași lungime cu dimensiunile matricei.
Python3# Python program for indexing using basic slicing with ellipsis import numpy as np # A 3 dimensional array. b = np.array([[[1, 2, 3],[4, 5, 6]], [[7, 8, 9],[10, 11, 12]]]) print(b[...,1]) #Equivalent to b[: ,: ,1 ]
Ieșire:
[[ 2 5] [ 8 11]]
NumPy Array Broadcasting
Termenul de difuzare se referă la modul în care numpy tratează matricele cu dimensiuni diferite în timpul operațiilor aritmetice care conduc la anumite constrângeri, matricea mai mică este difuzată în matricea mai mare, astfel încât acestea să aibă forme compatibile.
Să presupunem că avem un set mare de date, fiecare datum este o listă de parametri. În Numpy avem o matrice 2-D, în care fiecare rând este un datum, iar numărul de rânduri este dimensiunea setului de date. Să presupunem că vrem să aplicăm un fel de scalare tuturor acestor date, fiecare parametru primește propriul factor de scalare sau spunem că Fiecare parametru este înmulțit cu un anumit factor.
Doar pentru a înțelege clar, să numărăm caloriile din alimente folosind o descompunere a macronutrienților. Pe scurt, părțile calorice ale alimentelor sunt făcute din grăsimi (9 calorii pe gram), proteine (4 CPG) și carbohidrați (4 CPG). Deci, dacă enumerăm unele alimente (datele noastre) și pentru fiecare aliment listăm defalcarea macro-nutrienților (parametrii), putem apoi înmulți fiecare nutrient cu valoarea sa calorică (aplicați scalarea) pentru a calcula defalcarea calorică a fiecărui aliment.

Cu această transformare, acum putem calcula tot felul de informații utile. De exemplu, care este numărul total de calorii prezente în unele alimente sau, având în vedere o defalcare a cinei mele, știu câte calorii am primit din proteine și așa mai departe.
Să vedem un mod naiv de a produce acest calcul cu Numpy:
Python3import numpy as np macros = np.array([ [0.8, 2.9, 3.9], [52.4, 23.6, 36.5], [55.2, 31.7, 23.9], [14.4, 11, 4.9] ]) # Create a new array filled with zeros, # of the same shape as macros. result = np.zeros_like(macros) cal_per_macro = np.array([3, 3, 8]) # Now multiply each row of macros by # cal_per_macro. In Numpy, `*` is # element-wise multiplication between two arrays. for i in range(macros.shape[0]): result[i, :] = macros[i, :] * cal_per_macro result
Ieșire:
array([[ 2.4, 8.7, 31.2], [157.2, 70.8, 292. ], [165.6, 95.1, 191.2], [ 43.2, 33. , 39.2]])
Reguli de difuzare: Difuzarea a două matrice împreună urmează aceste reguli:
- Dacă matricele nu au același rang, atunci înaintează forma matricei de rang inferior cu 1 până când ambele forme au aceeași lungime.
- Cele două matrice sunt compatibile într-o dimensiune dacă au aceeași dimensiune în dimensiune sau dacă una dintre matrice are dimensiunea 1 în acea dimensiune.
- Matricele pot fi difuzate împreună dacă sunt compatibile cu toate dimensiunile.
- După difuzare, fiecare matrice se comportă ca și cum ar avea o formă egală cu maximumul de forme din punct de vedere al elementelor ale celor două matrice de intrare.
- În orice dimensiune în care o matrice avea o dimensiune de 1 și cealaltă matrice avea o dimensiune mai mare decât 1, prima matrice se comportă ca și cum ar fi copiată de-a lungul acelei dimensiuni.
import numpy as np v = np.array([12, 24, 36]) w = np.array([45, 55]) # To compute an outer product we first # reshape v to a column vector of shape 3x1 # then broadcast it against w to yield an output # of shape 3x2 which is the outer product of v and w print(np.reshape(v, (3, 1)) * w) X = np.array([[12, 22, 33], [45, 55, 66]]) # x has shape 2x3 and v has shape (3, ) # so they broadcast to 2x3, print(X + v) # Add a vector to each column of a matrix X has # shape 2x3 and w has shape (2, ) If we transpose X # then it has shape 3x2 and can be broadcast against w # to yield a result of shape 3x2. # Transposing this yields the final result # of shape 2x3 which is the matrix. print((X.T + w).T) # Another solution is to reshape w to be a column # vector of shape 2X1 we can then broadcast it # directly against X to produce the same output. print(X + np.reshape(w, (2, 1))) # Multiply a matrix by a constant, X has shape 2x3. # Numpy treats scalars as arrays of shape(); # these can be broadcast together to shape 2x3. print(X * 2)
Ieșire:
[[ 540 660] [1080 1320] [1620 1980]] [[ 24 46 69] [ 57 79 102]] [[ 57 67 78] [100 110 121]] [[ 57 67 78] [100 110 121]] [[ 24 44 66] [ 90 110 132]]
Notă: Pentru mai multe informații, consultați pagina noastră Tutorial Python NumPy .
Analizarea datelor folosind Pandas
Python Pandas este utilizat pentru date relaționale sau etichetate și oferă diverse structuri de date pentru manipularea unor astfel de date și serii de timp. Această bibliotecă este construită deasupra bibliotecii NumPy. Acest modul este în general importat ca:
import pandas as pd
Aici, pd este denumit un alias pentru Pandas. Cu toate acestea, nu este necesar să importați biblioteca folosind aliasul, ci doar ajută la scrierea unui cod mai mic de fiecare dată când este apelată o metodă sau o proprietate. Pandas oferă în general două structuri de date pentru manipularea datelor, acestea sunt:
- Serie
- Cadrul de date
Serie:
Seria Pandas este o matrice etichetată unidimensională capabilă să dețină date de orice tip (intreg, șir, float, obiecte Python etc.). Etichetele axelor sunt denumite colectiv indici. Seria Pandas nu este altceva decât o coloană într-o foaie Excel. Etichetele nu trebuie să fie unice, ci trebuie să fie de tip hashable. Obiectul acceptă atât indexarea pe bază de numere întregi, cât și pe etichete și oferă o serie de metode pentru efectuarea operațiunilor care implică indexul.
Seria Pandas
Poate fi creat folosind funcția Series() prin încărcarea setului de date din stocarea existentă, cum ar fi SQL, Bază de date, fișiere CSV, fișiere Excel etc., sau din structuri de date precum liste, dicționare etc.
Seria de creare a pandalor Python
Python3import pandas as pd import numpy as np # Creating empty series ser = pd.Series() print(ser) # simple array data = np.array(['g', 'e', 'e', 'k', 's']) ser = pd.Series(data) print(ser)
Ieșire:

seria pnadas
Cadrul de date:
Pandas DataFrame este o structură de date tabulară bidimensională, care poate varia în funcție de dimensiune, potențial eterogenă, cu axe etichetate (rânduri și coloane). Un cadru de date este o structură de date bidimensională, adică datele sunt aliniate într-un mod tabelar în rânduri și coloane. Pandas DataFrame constă din trei componente principale, date, rânduri și coloane.
Pandas Dataframe
Poate fi creat folosind metoda Dataframe() și, la fel ca o serie, poate fi, de asemenea, din diferite tipuri de fișiere și structuri de date.
Python Pandas creând un cadru de date
Python3import pandas as pd # Calling DataFrame constructor df = pd.DataFrame() print(df) # list of strings lst = ['Geeks', 'For', 'Geeks', 'is', 'portal', 'for', 'Geeks'] # Calling DataFrame constructor on list df = pd.DataFrame(lst) df
Ieșire:

Crearea unui Dataframe din lista Python
Se creează un cadru de date din CSV
Putem creați un cadru de date din CSV fișierele care utilizează read_csv() funcţie.
Python Pandas citește CSV
Python3import pandas as pd # Reading the CSV file df = pd.read_csv('Iris.csv') # Printing top 5 rows df.head() Ieșire:

capul unui cadru de date
Filtrarea DataFrame
panda dataframe.filter() funcția este utilizată pentru a subseta rânduri sau coloane ale cadrului de date conform etichetelor din indexul specificat. Rețineți că această rutină nu filtrează un cadru de date pe conținutul său. Filtrul este aplicat etichetelor indexului.
Python Pandas Filter Dataframe
Python3import pandas as pd # Reading the CSV file df = pd.read_csv('Iris.csv') # applying filter function df.filter(['Species', 'SepalLengthCm', 'SepalLengthCm']).head() Ieșire:

Aplicarea filtrului pe setul de date
Sortarea DataFrame
Pentru a sorta cadrul de date în panda, funcția sort_values() este folosit. Pandas sort_values() poate sorta cadrul de date în ordine Crescătoare sau Descrescătoare.
Python Pandas Sortează cadrul de date în ordine crescătoare
Ieșire:

Setul de date sortat pe baza unei valori de coloană
Pandas GroupBy
A se grupa cu este un concept destul de simplu. Putem crea o grupare de categorii și aplicam o funcție categoriilor. În proiectele reale de știință a datelor, veți avea de-a face cu cantități mari de date și veți încerca lucruri din nou și din nou, așa că pentru eficiență, folosim conceptul Groupby. Groupby se referă în principal la un proces care implică unul sau mai mulți dintre următorii pași:
- Despicare: Este un proces în care împărțim datele în grup, aplicând anumite condiții asupra seturilor de date.
- Punerea în aplicare: Este un proces în care aplicăm o funcție fiecărui grup în mod independent.
- Combinând: Este un proces în care combinăm diferite seturi de date după aplicarea groupby și rezultatele într-o structură de date.
Următoarea imagine va ajuta la înțelegerea procesului implicat în conceptul Groupby.
1. Grupați valorile unice din coloana Echipă
Metoda Pandas Groupby
2. Acum există o găleată pentru fiecare grup
3. Aruncă celelalte date în găleți

4. Aplicați o funcție pe coloana de greutate a fiecărei găleți.
Aplicarea funcției pe coloana de greutate a fiecărei coloane
Python Pandas GroupBy
Python3# importing pandas module import pandas as pd # Define a dictionary containing employee data data1 = {'Name': ['Jai', 'Anuj', 'Jai', 'Princi', 'Gaurav', 'Anuj', 'Princi', 'Abhi'], 'Age': [27, 24, 22, 32, 33, 36, 27, 32], 'Address': ['Nagpur', 'Kanpur', 'Allahabad', 'Kannuaj', 'Jaunpur', 'Kanpur', 'Allahabad', 'Aligarh'], 'Qualification': ['Msc', 'MA', 'MCA', 'Phd', 'B.Tech', 'B.com', 'Msc', 'MA']} # Convert the dictionary into DataFrame df = pd.DataFrame(data1) print('Original Dataframe') display(df) # applying groupby() function to # group the data on Name value. gk = df.groupby('Name') # Let's print the first entries # in all the groups formed. print('After Creating Groups') gk.first() Ieșire:

panda groupby
Aplicarea funcției la grup:
După împărțirea unei date într-un grup, aplicăm câte o funcție fiecărui grup, astfel încât să efectuăm câteva operații care sunt:
- Agregare: Este un proces în care calculăm o statistică rezumativă (sau statistici) despre fiecare grup. De exemplu, Calculați sume sau medii de grup
- Transformare: Este un proces în care efectuăm unele calcule specifice grupului și returnăm un index similar. De exemplu, completarea NA în grupuri cu o valoare derivată din fiecare grup
- Filtrare: Este un proces în care aruncăm unele grupuri, conform unui calcul în funcție de grup care evaluează Adevărat sau Fals. De exemplu, filtrarea datelor pe baza sumei sau a mediei grupului
Agregarea panda
Agregare este un proces în care calculăm o statistică sumar despre fiecare grup. Funcția agregată returnează o singură valoare agregată pentru fiecare grup. După împărțirea datelor în grupuri folosind funcția groupby, pot fi efectuate mai multe operațiuni de agregare asupra datelor grupate.
Python Pandas Aggregation
Python3# importing pandas module import pandas as pd # importing numpy as np import numpy as np # Define a dictionary containing employee data data1 = {'Name': ['Jai', 'Anuj', 'Jai', 'Princi', 'Gaurav', 'Anuj', 'Princi', 'Abhi'], 'Age': [27, 24, 22, 32, 33, 36, 27, 32], 'Address': ['Nagpur', 'Kanpur', 'Allahabad', 'Kannuaj', 'Jaunpur', 'Kanpur', 'Allahabad', 'Aligarh'], 'Qualification': ['Msc', 'MA', 'MCA', 'Phd', 'B.Tech', 'B.com', 'Msc', 'MA']} # Convert the dictionary into DataFrame df = pd.DataFrame(data1) # performing aggregation using # aggregate method grp1 = df.groupby('Name') grp1.aggregate(np.sum) Ieșire:

Utilizarea funcției de sumă agregată pe setul de date
Concatenarea DataFrame
Pentru a conecta cadrul de date, folosim concat() funcție care ajută la concatenarea cadrului de date. Această funcție face toate sarcinile grele de a efectua operațiuni de concatenare împreună cu o axă de obiecte Pandas în timp ce efectuează logica setată opțională (unire sau intersecție) a indicilor (dacă există) pe celelalte axe.
Python Pandas Concatena Dataframe
Python3# importing pandas module import pandas as pd # Define a dictionary containing employee data data1 = {'key': ['K0', 'K1', 'K2', 'K3'], 'Name':['Jai', 'Princi', 'Gaurav', 'Anuj'], 'Age':[27, 24, 22, 32],} # Define a dictionary containing employee data data2 = {'key': ['K0', 'K1', 'K2', 'K3'], 'Address':['Nagpur', 'Kanpur', 'Allahabad', 'Kannuaj'], 'Qualification':['Btech', 'B.A', 'Bcom', 'B.hons']} # Convert the dictionary into DataFrame df = pd.DataFrame(data1) # Convert the dictionary into DataFrame df1 = pd.DataFrame(data2) display(df, df1) # combining series and dataframe res = pd.concat([df, df1], axis=1) res Ieșire:

Îmbinarea DataFrame
Când trebuie să combinăm DataFrame foarte mari, îmbinările servesc ca o modalitate puternică de a efectua rapid aceste operațiuni. Îmbinările pot fi făcute numai pe două DataFrames la un moment dat, notate ca tabele din stânga și din dreapta. Cheia este coloana comună pe care vor fi unite cele două DataFrames. Este o practică bună să folosiți chei care au valori unice în întreaga coloană pentru a evita duplicarea neintenționată a valorilor rândurilor. Panda oferă o singură funcție, combina() , ca punct de intrare pentru toate operațiunile standard de îmbinare a bazei de date între obiectele DataFrame.
Există patru moduri de bază de a gestiona îmbinarea (intern, stânga, dreapta și exterior), în funcție de rândurile care trebuie să-și păstreze datele.

Python Pandas Merge Dataframe
Python3# importing pandas module import pandas as pd # Define a dictionary containing employee data data1 = {'key': ['K0', 'K1', 'K2', 'K3'], 'Name':['Jai', 'Princi', 'Gaurav', 'Anuj'], 'Age':[27, 24, 22, 32],} # Define a dictionary containing employee data data2 = {'key': ['K0', 'K1', 'K2', 'K3'], 'Address':['Nagpur', 'Kanpur', 'Allahabad', 'Kannuaj'], 'Qualification':['Btech', 'B.A', 'Bcom', 'B.hons']} # Convert the dictionary into DataFrame df = pd.DataFrame(data1) # Convert the dictionary into DataFrame df1 = pd.DataFrame(data2) display(df, df1) # using .merge() function res = pd.merge(df, df1, on='key') res Ieșire:

Concatinarea a două seturi de date
Conectarea la DataFrame
Pentru a ne alătura cadrul de date, folosim .a te alatura() această funcție este utilizată pentru combinarea coloanelor a două DataFrame potențial indexate diferit într-un singur DataFrame rezultat.
Python Pandas se alătură Dataframe-ului
Python3# importing pandas module import pandas as pd # Define a dictionary containing employee data data1 = {'Name':['Jai', 'Princi', 'Gaurav', 'Anuj'], 'Age':[27, 24, 22, 32]} # Define a dictionary containing employee data data2 = {'Address':['Allahabad', 'Kannuaj', 'Allahabad', 'Kannuaj'], 'Qualification':['MCA', 'Phd', 'Bcom', 'B.hons']} # Convert the dictionary into DataFrame df = pd.DataFrame(data1,index=['K0', 'K1', 'K2', 'K3']) # Convert the dictionary into DataFrame df1 = pd.DataFrame(data2, index=['K0', 'K2', 'K3', 'K4']) display(df, df1) # joining dataframe res = df.join(df1) res Ieșire:

Unirea a două seturi de date
Pentru mai multe informații, consultați pagina noastră Panda fuzionarea, alăturarea și concatenarea tutorial
Pentru un ghid complet despre Pandas, consultați Tutorial panda .
Vizualizare cu Matplotlib
Matplotlib este ușor de utilizat și o bibliotecă de vizualizare uimitoare în Python. Este construit pe matrice NumPy și proiectat să funcționeze cu stiva SciPy mai largă și constă din mai multe diagrame, cum ar fi linie, bară, împrăștiere, histogramă etc.
Pyplot
Pyplot este un modul Matplotlib care oferă o interfață asemănătoare MATLAB. Pyplot oferă funcții care interacționează cu figura, adică creează o figură, decorează parcela cu etichete și creează o zonă de trasare într-o figură.
Python3# Python program to show pyplot module import matplotlib.pyplot as plt plt.plot([1, 2, 3, 4], [1, 4, 9, 16]) plt.axis([0, 6, 0, 20]) plt.show()
Ieșire:

Diagramă cu bare
A bar plot sau diagramă cu bare este un grafic care reprezintă categoria de date cu bare dreptunghiulare cu lungimi și înălțimi proporționale cu valorile pe care le reprezintă. Graficele cu bare pot fi trasate orizontal sau vertical. O diagramă cu bare descrie comparațiile dintre categoriile discrete. Poate fi creat folosind metoda bar().
Diagramă cu bare Python Matplotlib
Aici vom folosi numai setul de date iris
Python3import matplotlib.pyplot as plt import pandas as pd df = pd.read_csv('Iris.csv') # This will plot a simple bar chart plt.bar(df['Species'], df['SepalLengthCm']) # Title to the plot plt.title('Iris Dataset') # Adding the legends plt.legend(['bar']) plt.show() Ieșire:

Diagramă cu bare folosind biblioteca matplotlib
Histograme
A histogramă este folosit practic pentru a reprezenta date sub forma unor grupuri. Este un tip de diagramă cu bare în care axa X reprezintă intervalele bin, în timp ce axa Y oferă informații despre frecvență. Pentru a crea o histogramă, primul pas este să creați un bin al intervalelor, apoi să distribuiți întregul interval de valori într-o serie de intervale și să numărați valorile care se încadrează în fiecare dintre intervale. Binele sunt clar identificate ca intervale de variabile consecutive, care nu se suprapun. The hist() funcția este utilizată pentru a calcula și a crea o histogramă a lui x.
Histograma Python Matplotlib
Python3import matplotlib.pyplot as plt import pandas as pd df = pd.read_csv('Iris.csv') plt.hist(df['SepalLengthCm']) # Title to the plot plt.title('Histogram') # Adding the legends plt.legend(['SepalLengthCm']) plt.show() Ieșire:

Histplot folosind biblioteca matplotlib
Graficul de dispersie
Diagramele de dispersie sunt folosite pentru a observa relația dintre variabile și folosesc puncte pentru a reprezenta relația dintre ele. The împrăștia() metoda din biblioteca matplotlib este folosită pentru a desena un grafic de dispersie.
Graficul de dispersie Python Matplotlib
Python3import matplotlib.pyplot as plt import pandas as pd df = pd.read_csv('Iris.csv') plt.scatter(df['Species'], df['SepalLengthCm']) # Title to the plot plt.title('Scatter Plot') # Adding the legends plt.legend(['SepalLengthCm']) plt.show() Ieșire:

Graficul de dispersie folosind biblioteca matplotlib
Box Plot
A boxplot ,Corelație cunoscută și sub numele de diagramă cutie și mustăți. Este o reprezentare vizuală foarte bună atunci când vine vorba de măsurarea distribuției datelor. Trasează în mod clar valorile mediane, valorile aberante și quartilele. Înțelegerea distribuției datelor este un alt factor important care duce la o mai bună construcție a modelelor. Dacă datele au valori aberante, diagrama cu casete este o modalitate recomandată de a le identifica și de a lua măsurile necesare. Diagrama cu casete și mustăți arată cum sunt răspândite datele. Cinci informații sunt incluse în general în diagramă
- Minimul este afișat în extrema stângă a diagramei, la sfârșitul „muștaților” din stânga
- Prima cuartilă, Q1, este extrema stângă a casetei (mustața din stânga)
- Mediana este afișată ca o linie în centrul casetei
- A treia cuartilă, Q3, afișată în partea dreaptă extremă a casetei (mustată din dreapta)
- Maximul este în extrema dreaptă a casetei
Reprezentarea box plot

Intervalul dintre quartile

Ilustrare box plot
Python Matplotlib Box Plot
Python3import matplotlib.pyplot as plt import pandas as pd df = pd.read_csv('Iris.csv') plt.boxplot(df['SepalWidthCm']) # Title to the plot plt.title('Box Plot') # Adding the legends plt.legend(['SepalWidthCm']) plt.show() Ieșire:

Boxplot folosind biblioteca matplotlib
Hărți de corelație
O hartă termică 2-D este un instrument de vizualizare a datelor care ajută la reprezentarea mărimii fenomenului sub formă de culori. O hartă termică de corelație este o hartă termică care arată o matrice de corelație 2D între două dimensiuni discrete, folosind celule colorate pentru a reprezenta date de la o scară de obicei monocromatică. Valorile primei dimensiuni apar ca rânduri ale tabelului, în timp ce a doua dimensiune este o coloană. Culoarea celulei este proporțională cu numărul de măsurători care se potrivesc cu valoarea dimensională. Acest lucru face că hărțile de corelație sunt ideale pentru analiza datelor, deoarece face modelele ușor de citit și evidențiază diferențele și variațiile din aceleași date. O hartă termică de corelație, ca o hartă termică obișnuită, este asistată de o bară de culori care face datele ușor de citit și de înțeles.
Notă: Datele de aici trebuie transmise cu metoda corr() pentru a genera o hartă termică de corelație. De asemenea, corr() în sine elimină coloanele care nu vor fi de nici un folos în timp ce generează o hartă termică de corelare și le selectează pe cele care pot fi utilizate.
Harta termică de corelație Python Matplotlib
Python3import matplotlib.pyplot as plt import pandas as pd df = pd.read_csv('Iris.csv') plt.imshow(df.corr() , cmap = 'autumn' , interpolation = 'nearest' ) plt.title('Heat Map') plt.show() Ieșire:

Hartă termică folosind biblioteca matplotlib
Pentru mai multe informații despre vizualizarea datelor, consultați tutorialele noastre de mai jos -
- Notă: Vom folosi Iris Dataset.
Obținerea de informații despre setul de date
Vom folosi parametrul de formă pentru a obține forma setului de date.
Forma cadrului de date
Python3df.shapeIeșire:
(150, 6)Putem vedea că cadrul de date conține 6 coloane și 150 de rânduri.
Notă: Vom folosi Iris Dataset.
Obținerea de informații despre setul de date
Acum, să vedem și coloanele și tipurile lor de date. Pentru aceasta, vom folosi info() metodă.
Informații despre Dataset
Python3df.info()Ieșire:

informații despre setul de date
Putem vedea că doar o coloană are date categorice și toate celelalte coloane sunt de tip numeric cu intrări non-Null.
Să obținem un rezumat statistic rapid al setului de date folosind descrie() metodă. Funcția describe() aplică calcule statistice de bază asupra setului de date, cum ar fi valorile extreme, numărul de abateri standard ale punctelor de date etc. Orice valoare lipsă sau valoare NaN este automat omisă. funcția describe() oferă o imagine bună a distribuției datelor.
Descrierea setului de date
Python3df.describe()Ieșire:

Descrierea setului de date
Putem vedea numărul fiecărei coloane împreună cu valoarea medie, abaterea standard, valorile minime și maxime.
Verificarea valorilor lipsă
Vom verifica dacă datele noastre conțin valori lipsă sau nu. Valorile lipsă pot apărea atunci când nu sunt furnizate informații pentru unul sau mai multe articole sau pentru o întreagă unitate. Vom folosi isnull() metodă.
codul python pentru valoarea lipsă
Python3df.isnull().sum()Ieșire:

Valori lipsă din setul de date
Putem vedea că nicio coloană nu are nicio valoare lipsă.
Verificarea duplicatelor
Să vedem dacă setul nostru de date conține duplicate sau nu. panda drop_duplicates() metoda ajută la eliminarea duplicatelor din cadrul de date.
Funcția Pandas pentru valorile lipsă
Python3data = df.drop_duplicates(subset ='Species',) dataIeșire:

Eliminarea valorii duplicate în setul de date
Putem vedea că există doar trei specii unice. Să vedem dacă setul de date este echilibrat sau nu, adică toate speciile conțin cantități egale de rânduri sau nu. Vom folosi Series.value_counts() funcţie. Această funcție returnează o serie care conține contor de valori unice.
Cod Python pentru contorizarea valorii în coloană
Python3df.value_counts('Species')Ieșire:

numărul de valori din setul de date
Putem vedea că toate speciile conțin o cantitate egală de rânduri, așa că nu ar trebui să ștergem nicio intrare.
Relația dintre variabile
Vom vedea relația dintre lungimea sepalului și lățimea sepalului și, de asemenea, între lungimea și lățimea petalei.
Comparând lungimea sepalului și lățimea sepalului
Python3# importing packages import seaborn as sns import matplotlib.pyplot as plt sns.scatterplot(x='SepalLengthCm', y='SepalWidthCm', hue='Species', data=df, ) # Placing Legend outside the Figure plt.legend(bbox_to_anchor=(1, 1), loc=2) plt.show()Ieșire:

Graficul de dispersie folosind biblioteca matplotlib
Din diagrama de mai sus, putem deduce că -
- Specia Setosa are lungimi mai mici de sepal, dar lățimi mai mari de sepale.
- Specia Versicolor se află la mijlocul celorlalte două specii în ceea ce privește lungimea și lățimea sepalului
- Specia Virginica are lungimi mai mari de sepal, dar lățimi mai mici de sepale.
Compararea lungimii petalei și a lățimii petalei
Python3# importing packages import seaborn as sns import matplotlib.pyplot as plt sns.scatterplot(x='PetalLengthCm', y='PetalWidthCm', hue='Species', data=df, ) # Placing Legend outside the Figure plt.legend(bbox_to_anchor=(1, 1), loc=2) plt.show()Ieșire:

sactter plot lungime petale
Din diagrama de mai sus, putem deduce că -
- Specia Setosa are lungimi și lățimi de petale mai mici.
- Specia Versicolor se află la mijlocul celorlalte două specii în ceea ce privește lungimea și lățimea petalelor
- Specia Virginica are cele mai mari lungimi și lățimi de petale.
Să trasăm toate relațiile coloanei folosind un diagramă de perechi. Poate fi folosit pentru analiza multivariată.
Cod Python pentru pairplot
Python3# importing packages import seaborn as sns import matplotlib.pyplot as plt sns.pairplot(df.drop(['Id'], axis = 1), hue='Species', height=2)Ieșire:
Pairplot pentru setul de date
Putem vedea multe tipuri de relații din acest complot, cum ar fi specia Seotsa are cea mai mică dintre lățimi și lungimi de petale. Are, de asemenea, cea mai mică lungime a sepalului, dar lățimi mai mari ale sepalului. Astfel de informații pot fi adunate despre orice altă specie.
Corelația de manipulare
panda dataframe.corr() este utilizat pentru a găsi corelația pe perechi a tuturor coloanelor din cadrul de date. Orice valori NA sunt automat excluse. Orice coloane de tip de date non-numerice din cadrul de date sunt ignorate.
Exemplu:
Python3data.corr(method='pearson')Ieșire:

corelația dintre coloanele din setul de date
Hărți de căldură
Harta termică este o tehnică de vizualizare a datelor care este utilizată pentru a analiza setul de date ca culori în două dimensiuni. Practic, arată o corelație între toate variabilele numerice din setul de date. În termeni mai simpli, putem reprezenta grafic corelația de mai sus folosind hărțile termice.
cod python pentru heatmap
Python3# importing packages import seaborn as sns import matplotlib.pyplot as plt sns.heatmap(df.corr(method='pearson').drop( ['Id'], axis=1).drop(['Id'], axis=0), annot = True); plt.show()Ieșire:

Hartă termică pentru corelare în setul de date
Din graficul de mai sus, putem vedea că -
- Lățimea și lungimea petalei au corelații mari.
- Lungimea petalei și lățimea sepalului au corelații bune.
- Lățimea petalelor și lungimea sepalului au corelații bune.
Manipularea Outliers
Un Outlier este un element/obiect de date care se abate semnificativ de la restul obiectelor (așa-numitele normale). Acestea pot fi cauzate de erori de măsurare sau de execuție. Analiza pentru detectarea valorii aberante este denumită extragere a valorii aberante. Există multe modalități de a detecta valori aberante, iar procesul de eliminare este cadrul de date la fel ca și eliminarea unui element de date din cadrul de date al panda.
Să luăm în considerare setul de date iris și să trasăm graficul cu box pentru coloana SepalWidthCm.
cod python pentru Boxplot
Python3# importing packages import seaborn as sns import matplotlib.pyplot as plt # Load the dataset df = pd.read_csv('Iris.csv') sns.boxplot(x='SepalWidthCm', data=df)Ieșire:

Boxplot pentru coloana sepalwidth
În graficul de mai sus, valorile de peste 4 și sub 2 acționează ca valori aberante.
Eliminarea valorii aberante
Pentru a elimina valorile aberante, trebuie să urmați același proces de eliminare a unei intrări din setul de date folosind poziția sa exactă în setul de date, deoarece în toate metodele de mai sus de detectare a valorii aberante, rezultatul final este lista tuturor acelor elemente de date care satisfac definiția valorii aberante. conform metodei folosite.
Vom detecta valorile aberante folosind IQR și apoi le vom elimina. De asemenea, vom desena boxplot-ul pentru a vedea dacă valorile aberante sunt eliminate sau nu.
Python3# Importing import sklearn from sklearn.datasets import load_boston import pandas as pd import seaborn as sns # Load the dataset df = pd.read_csv('Iris.csv') # IQR Q1 = np.percentile(df['SepalWidthCm'], 25, interpolation = 'midpoint') Q3 = np.percentile(df['SepalWidthCm'], 75, interpolation = 'midpoint') IQR = Q3 - Q1 print('Old Shape: ', df.shape) # Upper bound upper = np.where(df['SepalWidthCm']>= (Q3+1.5*IQR)) # Limită inferioară inferioară = np.where(df['SepalWidthCm'] <= (Q1-1.5*IQR)) # Removing the Outliers df.drop(upper[0], inplace = True) df.drop(lower[0], inplace = True) print('New Shape: ', df.shape) sns.boxplot(x='SepalWidthCm', data=df)Ieșire:

boxplot folosind biblioteca Seaborn
Pentru mai multe informații despre EDA, consultați tutorialele noastre de mai jos -