Gerenciador de download multithread simples em Python
UM Gerenciador de downloads é basicamente um programa de computador dedicado à tarefa de baixar arquivos independentes da Internet. Aqui vamos criar um gerenciador de download simples com a ajuda de threads em Python. Usando multi-threading, um arquivo pode ser baixado na forma de pedaços simultaneamente de diferentes threads. Para implementar isso, criaremos uma ferramenta simples de linha de comando que aceita o URL do arquivo e depois faz o download dele.
Pré-requisitos: Máquina Windows com Python instalado.
Configurar
Baixe os pacotes mencionados abaixo no prompt de comando.
1. Pacote Click: Click é um pacote Python para criar lindas interfaces de linha de comando com o mínimo de código necessário. É o kit de criação de interface de linha de comando.
pip instalar clique
2. Pacote de solicitações: Nesta ferramenta vamos baixar um arquivo baseado na URL (endereços HTTP). Requests é uma biblioteca HTTP escrita em Python que permite enviar solicitações HTTP. Você pode adicionar cabeçalhos de dados de arquivos e parâmetros de várias partes com dicionários Python simples e acessar os dados de resposta da mesma maneira.
solicitações de instalação pip
3. Pacote de threading: Para trabalhar com threads precisamos do pacote de threading.
pip instalar rosqueamento
Implementação
Observação:
O programa foi dividido em partes para facilitar a compreensão. Certifique-se de não perder nenhuma parte do código ao executar o programa.
Etapa 1: importar pacotes necessários
Esses pacotes fornecem as ferramentas necessárias para fazer com que as solicitações da web lidem com entradas de linha de comando e criem threads.
Python import click import requests import threading
Etapa 2: Crie a função manipuladora
Cada thread executará esta função para baixar seu pedaço específico do arquivo. Esta função é responsável por solicitar apenas um intervalo específico de bytes e gravá-los na posição correta do arquivo.
Python def Handler ( start end url filename ): headers = { 'Range' : f 'bytes= { start } - { end } ' } r = requests . get ( url headers = headers stream = True ) with open ( filename 'r+b' ) as fp : fp . seek ( start ) fp . write ( r . content )
Etapa 3: Defina a função principal com clique
Transforma a função em um utilitário de linha de comando. Isso define como os usuários interagem com o script na linha de comando.
Python #Note: This code will not work on online IDE @click . command ( help = 'Downloads the specified file with given name using multi-threading' ) @click . option ( '--number_of_threads' default = 4 help = 'Number of threads to use' ) @click . option ( '--name' type = click . Path () help = 'Name to save the file as (with extension)' ) @click . argument ( 'url_of_file' type = str ) def download_file ( url_of_file name number_of_threads ):
Etapa 4: definir o nome do arquivo e determinar o tamanho do arquivo
Precisamos do tamanho do arquivo para dividir o download entre threads e garantir que o servidor suporte downloads variados.
Python r = requests . head ( url_of_file ) file_name = name if name else url_of_file . split ( '/' )[ - 1 ] try : file_size = int ( r . headers [ 'Content-Length' ]) except : print ( 'Invalid URL or missing Content-Length header.' ) return
Etapa 5: pré-alocar espaço de arquivo
A pré-alocação garante que o arquivo tenha o tamanho correto antes de gravarmos pedaços em intervalos de bytes específicos.
Python part = file_size // number_of_threads with open ( file_name 'wb' ) as fp : fp . write ( b ' � ' * file_size )
Etapa 6: criar tópicos
Threads recebem intervalos de bytes específicos para download em paralelo.
Python threads = [] for i in range ( number_of_threads ): start = part * i end = file_size - 1 if i == number_of_threads - 1 else ( start + part - 1 ) t = threading . Thread ( target = Handler kwargs = { 'start' : start 'end' : end 'url' : url_of_file 'filename' : file_name }) threads . append ( t ) t . start ()
Etapa 7: juntar tópicos
Garante que todos os threads sejam concluídos antes do término do programa.
Python for t in threads : t . join () print ( f ' { file_name } downloaded successfully!' ) if __name__ == '__main__' : download_file ()
Código:
Python import click import requests import threading def Handler ( start end url filename ): headers = { 'Range' : f 'bytes= { start } - { end } ' } r = requests . get ( url headers = headers stream = True ) with open ( filename 'r+b' ) as fp : fp . seek ( start ) fp . write ( r . content ) @click . command ( help = 'Downloads the specified file with given name using multi-threading' ) @click . option ( '--number_of_threads' default = 4 help = 'Number of threads to use' ) @click . option ( '--name' type = click . Path () help = 'Name to save the file as (with extension)' ) @click . argument ( 'url_of_file' type = str ) def download_file ( url_of_file name number_of_threads ): r = requests . head ( url_of_file ) if name : file_name = name else : file_name = url_of_file . split ( '/' )[ - 1 ] try : file_size = int ( r . headers [ 'Content-Length' ]) except : print ( 'Invalid URL or missing Content-Length header.' ) return part = file_size // number_of_threads with open ( file_name 'wb' ) as fp : fp . write ( b ' � ' * file_size ) threads = [] for i in range ( number_of_threads ): start = part * i # Make sure the last part downloads till the end of file end = file_size - 1 if i == number_of_threads - 1 else ( start + part - 1 ) t = threading . Thread ( target = Handler kwargs = { 'start' : start 'end' : end 'url' : url_of_file 'filename' : file_name }) threads . append ( t ) t . start () for t in threads : t . join () print ( f ' { file_name } downloaded successfully!' ) if __name__ == '__main__' : download_file ()
Concluímos a parte de codificação e agora seguimos os comandos mostrados abaixo para executar o arquivo .py.
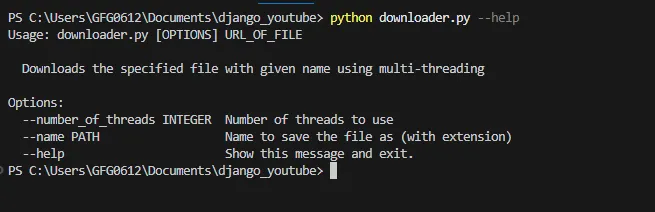
python filename.py –-helpSaída:
nome do arquivo python.py –-help
Este comando mostra o uso da ferramenta de comando de clique e as opções que a ferramenta pode aceitar. Abaixo está o exemplo de comando onde tentamos baixar um arquivo de imagem jpg de uma URL e também fornecemos um nome e número_de_threads.
comando de exemplo para baixar um jpg
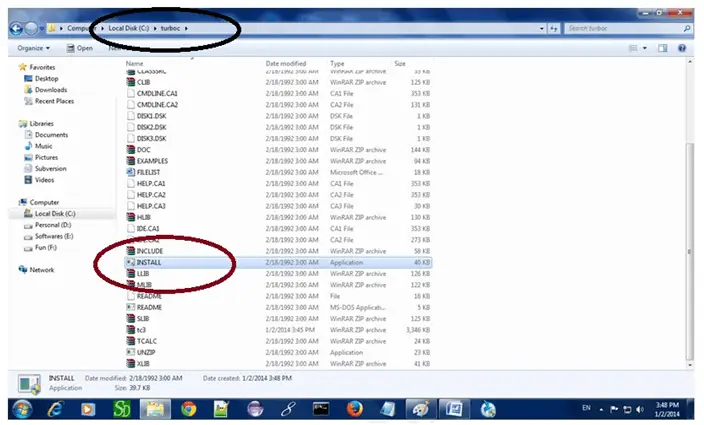
Depois de executar tudo com sucesso, você poderá ver seu arquivo (flower.webp neste caso) no diretório de sua pasta, conforme mostrado abaixo:
diretório
Finalmente concluímos isso com sucesso e esta é uma das maneiras de construir um gerenciador de download multithread simples em Python.
 nome do arquivo python.py –-help
nome do arquivo python.py –-help  comando de exemplo para baixar um jpg
comando de exemplo para baixar um jpg  diretório
diretório