Parsowanie XML w Pythonie

W tym artykule skupiono się na tym, jak można przeanalizować dany plik XML i wyodrębnić z niego przydatne dane w uporządkowany sposób. XML: XML oznacza eXtensible Markup Language. Został zaprojektowany do przechowywania i przesyłania danych. Został zaprojektowany tak, aby był czytelny zarówno dla ludzi, jak i maszyn. Dlatego też cele projektowe XML kładą nacisk na prostotę, ogólność i użyteczność w Internecie. Plik XML, który będzie analizowany w tym samouczku, jest w rzeczywistości kanałem RSS. RSS: RSS (Rich Site Summary, często nazywane naprawdę prostą syndykacją) wykorzystuje rodzinę standardowych formatów kanałów internetowych do publikowania często aktualizowanych informacji, takich jak wpisy na blogach, nagłówki wiadomości, audio wideo. RSS to zwykły tekst w formacie XML.
- Sam format RSS jest stosunkowo łatwy do odczytania zarówno przez zautomatyzowane procesy, jak i przez ludzi.
- Kanał RSS przetwarzany w tym samouczku to kanał RSS zawierający najważniejsze wiadomości z popularnej witryny z wiadomościami. Możesz to sprawdzić Tutaj . Naszym celem jest przetworzenie tego kanału RSS (lub pliku XML) i zapisanie go w innym formacie do wykorzystania w przyszłości.
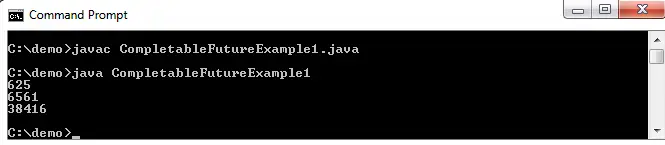
#Python code to illustrate parsing of XML files # importing the required modules import csv import requests import xml.etree.ElementTree as ET def loadRSS (): # url of rss feed url = 'http://www.hindustantimes.com/rss/topnews/rssfeed.xml' # creating HTTP response object from given url resp = requests . get ( url ) # saving the xml file with open ( 'topnewsfeed.xml' 'wb' ) as f : f . write ( resp . content ) def parseXML ( xmlfile ): # create element tree object tree = ET . parse ( xmlfile ) # get root element root = tree . getroot () # create empty list for news items newsitems = [] # iterate news items for item in root . findall ( './channel/item' ): # empty news dictionary news = {} # iterate child elements of item for child in item : # special checking for namespace object content:media if child . tag == '{https://video.search.yahoo.com/mrss' : news [ 'media' ] = child . attrib [ 'url' ] else : news [ child . tag ] = child . text . encode ( 'utf8' ) # append news dictionary to news items list newsitems . append ( news ) # return news items list return newsitems def savetoCSV ( newsitems filename ): # specifying the fields for csv file fields = [ 'guid' 'title' 'pubDate' 'description' 'link' 'media' ] # writing to csv file with open ( filename 'w' ) as csvfile : # creating a csv dict writer object writer = csv . DictWriter ( csvfile fieldnames = fields ) # writing headers (field names) writer . writeheader () # writing data rows writer . writerows ( newsitems ) def main (): # load rss from web to update existing xml file loadRSS () # parse xml file newsitems = parseXML ( 'topnewsfeed.xml' ) # store news items in a csv file savetoCSV ( newsitems 'topnews.csv' ) if __name__ == '__main__' : # calling main function main ()
Above code will: - Załaduj kanał RSS z określonego adresu URL i zapisz go jako plik XML.
- Przeanalizuj plik XML, aby zapisać wiadomości jako listę słowników, gdzie każdy słownik to pojedynczy element wiadomości.
- Zapisz wiadomości w pliku CSV.
- Możesz zobaczyć więcej kanałów rss serwisu informacyjnego użytych w powyższym przykładzie. Możesz spróbować utworzyć rozszerzoną wersję powyższego przykładu, analizując także inne kanały rss.
- Czy jesteś fanem krykieta? Następnie Ten Kanał rss musi Cię zainteresować! Możesz przeanalizować ten plik XML, aby zebrać informacje o meczach krykieta na żywo i użyć go do utworzenia powiadomienia na pulpicie!
def loadRSS(): # url of rss feed url = 'http://www.hindustantimes.com/rss/topnews/rssfeed.xml' # creating HTTP response object from given url resp = requests.get(url) # saving the xml file with open('topnewsfeed.xml' 'wb') as f: f.write(resp.content) Here we first created a HTTP response object by sending an HTTP request to the URL of the RSS feed. The content of response now contains the XML file data which we save as topnewsfeed.xml w naszym lokalnym katalogu. Aby uzyskać więcej informacji na temat działania modułu żądań, przeczytaj ten artykuł: Żądania GET i POST przy użyciu języka Python  Tutaj używamy xml.etree.ElementTree (nazwij to w skrócie ET). W tym celu Element Tree ma dwie klasy - Drzewo Elementów reprezentuje cały dokument XML jako drzewo i Element reprezentuje pojedynczy węzeł w tym drzewie. Interakcje z całym dokumentem (odczyt i zapis do/z plików) zwykle odbywają się na platformie Drzewo Elementów poziom. Interakcje z pojedynczym elementem XML i jego elementami podrzędnymi odbywają się na platformie Element poziom. OK, więc przejdźmy przez parseXML() function now:
Tutaj używamy xml.etree.ElementTree (nazwij to w skrócie ET). W tym celu Element Tree ma dwie klasy - Drzewo Elementów reprezentuje cały dokument XML jako drzewo i Element reprezentuje pojedynczy węzeł w tym drzewie. Interakcje z całym dokumentem (odczyt i zapis do/z plików) zwykle odbywają się na platformie Drzewo Elementów poziom. Interakcje z pojedynczym elementem XML i jego elementami podrzędnymi odbywają się na platformie Element poziom. OK, więc przejdźmy przez parseXML() function now: tree = ET.parse(xmlfile)Here we create an Drzewo Elementów obiekt poprzez analizę przekazanego obiektu plik xml.
root = tree.getroot()zrootowany() funkcja zwraca korzeń drzewo jako Element object.
for item in root.findall('./channel/item'): Now once you have taken a look at the structure of your XML file you will notice that we are interested only in przedmiot element. ./kanał/element jest właściwie XPath składnia (XPath to język adresowania części dokumentu XML). Tutaj chcemy znaleźć wszystko przedmiot wnuki z kanał dzieci z źródło (oznaczony jako „.”) elementu. Możesz przeczytać więcej o obsługiwanej składni XPath Tutaj . for item in root.findall('./channel/item'): # empty news dictionary news = {} # iterate child elements of item for child in item: # special checking for namespace object content:media if child.tag == '{https://video.search.yahoo.com/mrss': news['media'] = child.attrib['url'] else: news[child.tag] = child.text.encode('utf8') # append news dictionary to news items list newsitems.append(news) Now we know that we are iterating through przedmiot elementy, gdzie każdy przedmiot element zawiera jedną wiadomość. Tworzymy więc puste miejsce aktualności dictionary in which we will store all data available about news item. To iterate though each child element of an element we simply iterate through it like this: for child in item:Now notice a sample item element here:
 We will have to handle namespace tags separately as they get expanded to their original value when parsed. So we do something like this:
We will have to handle namespace tags separately as they get expanded to their original value when parsed. So we do something like this: if child.tag == '{https://video.search.yahoo.com/mrss': news['media'] = child.attrib['url'] atrybut.dziecko jest słownikiem wszystkich atrybutów związanych z elementem. Tutaj jesteśmy zainteresowani adres URL atrybut multimedia:treść namespace tag. Now for all other children we simply do: news[child.tag] = child.text.encode('utf8') dziecko.tag zawiera nazwę elementu podrzędnego. tekst.dziecka stores all the text inside that child element. So finally a sample item element is converted to a dictionary and looks like this: {'description': 'Ignis has a tough competition already from Hyun.... 'guid': 'http://www.hindustantimes.com/autos/maruti-ignis-launch.... 'link': 'http://www.hindustantimes.com/autos/maruti-ignis-launch.... 'media': 'http://www.hindustantimes.com/rf/image_size_630x354/HT/... 'pubDate': 'Thu 12 Jan 2017 12:33:04 GMT ' 'title': 'Maruti Ignis launches on Jan 13: Five cars that threa..... } Then we simply append this dict element to the list nowestrony . Na koniec ta lista jest zwracana.  Jak widać, dane w hierarchicznym pliku XML zostały przekonwertowane do prostego pliku CSV, dzięki czemu wszystkie wiadomości są przechowywane w formie tabeli. Ułatwia to także rozbudowę bazy danych. Można także używać danych typu JSON bezpośrednio w swoich aplikacjach! Jest to najlepsza alternatywa do wydobywania danych ze stron internetowych, które nie udostępniają publicznego interfejsu API, ale udostępniają niektóre kanały RSS. Można znaleźć cały kod i pliki użyte w powyższym artykule Tutaj . Co dalej?
Jak widać, dane w hierarchicznym pliku XML zostały przekonwertowane do prostego pliku CSV, dzięki czemu wszystkie wiadomości są przechowywane w formie tabeli. Ułatwia to także rozbudowę bazy danych. Można także używać danych typu JSON bezpośrednio w swoich aplikacjach! Jest to najlepsza alternatywa do wydobywania danych ze stron internetowych, które nie udostępniają publicznego interfejsu API, ale udostępniają niektóre kanały RSS. Można znaleźć cały kod i pliki użyte w powyższym artykule Tutaj . Co dalej? Może Ci Się Spodobać

Najpopularniejsze Artykuły