Praca z plikami PDF w Pythonie
Wszyscy powinniście wiedzieć, czym są pliki PDF. W rzeczywistości są jednymi z najważniejszych i najpowszechniej używanych mediów cyfrowych. PDF oznacza format dokumentu przenośnego . To używa .pdf rozszerzenie. Służy do niezawodnego prezentowania i wymiany dokumentów, niezależnie od oprogramowania, sprzętu czy systemu operacyjnego.
Wynalezione przez Cegła suszona na słońcu , PDF jest obecnie otwartym standardem utrzymywanym przez Międzynarodową Organizację Normalizacyjną (ISO). Pliki PDF mogą zawierać łącza i przyciski, pola formularzy, pliki audio i wideo oraz logikę biznesową.
W tym artykule dowiemy się, jak możemy wykonywać różne operacje, takie jak:
- Wyodrębnianie tekstu z pliku PDF
- Obracanie stron PDF
- Łączenie plików PDF
- Dzielenie pliku PDF
- Dodawanie znaku wodnego do stron PDF
Instalacja: Używanie prostych skryptów Pythona!
Będziemy używać modułu strony trzeciej, pypdf.
pypdf to biblioteka Pythona zbudowana jako zestaw narzędzi PDF. Potrafi:
- Wyodrębnianie informacji o dokumencie (tytuł, autor,…)
- Dzielenie dokumentów strona po stronie
- Łączenie dokumentów strona po stronie
- Przycinanie stron
- Łączenie wielu stron w jedną
- Szyfrowanie i deszyfrowanie plików PDF
- i więcej!
Aby zainstalować pypdf, uruchom następujące polecenie z wiersza poleceń:
pip install pypdf
W nazwie modułu rozróżniana jest wielkość liter, więc upewnij się, że I jest pisany małymi literami, a wszystko inne jest pisane wielkimi literami. Dostępny jest cały kod i pliki PDF użyte w tym samouczku/artykule Tutaj .
1. Wyodrębnianie tekstu z pliku PDF
Pyton
# importing required classes> from> pypdf> import> PdfReader> > # creating a pdf reader object> reader> => PdfReader(> 'example.pdf'> )> > # printing number of pages in pdf file> print> (> len> (reader.pages))> > # creating a page object> page> => reader.pages[> 0> ]> > # extracting text from page> print> (page.extract_text())> |
Dane wyjściowe powyższego programu wyglądają następująco:
20 PythonBasics S.R.Doty August27,2008 Contents 1Preliminaries 4 1.1WhatisPython?................................... ..4 1.2Installationanddocumentation.................... .........4 [and some more lines...]
Spróbujmy zrozumieć powyższy kod fragmentami:
reader = PdfReader('example.pdf') - Tutaj tworzymy obiekt Czytnik PDF class modułu pypdf i podaj ścieżkę do pliku PDF i pobierz obiekt czytnika PDF.
print(len(reader.pages))
- strony Właściwość podaje liczbę stron w pliku PDF. Na przykład w naszym przypadku jest to 20 (patrz pierwszy wiersz wyniku).
pageObj = reader.pages[0]
- Teraz tworzymy obiekt Obiekt strony klasa modułu pypdf. Obiekt czytnika PDF ma funkcję strony[] który przyjmuje numer strony (zaczynając od indeksu 0) jako argument i zwraca obiekt strony.
print(pageObj.extract_text())
- Obiekt strony ma funkcję wyodrębnij_tekst() aby wyodrębnić tekst ze strony PDF.
Notatka: Chociaż pliki PDF doskonale nadają się do układania tekstu w sposób łatwy do wydrukowania i przeczytania, oprogramowanie nie jest w stanie łatwo przekształcić ich w zwykły tekst. W związku z tym pypdf może popełniać błędy podczas wyodrębniania tekstu z pliku PDF, a nawet może w ogóle nie być w stanie otworzyć niektórych plików PDF. Niestety niewiele możesz z tym zrobić. pypdf może po prostu nie działać z niektórymi konkretnymi plikami PDF.
2. Obracanie stron PDF
Pyton
# importing the required classes> from> pypdf> import> PdfReader, PdfWriter> > def> PDFrotate(origFileName, newFileName, rotation):> > > # creating a pdf Reader object> > reader> => PdfReader(origFileName)> > > # creating a pdf writer object for new pdf> > writer> => PdfWriter()> > > # rotating each page> > for> page> in> range> (> len> (reader.pages)):> > > # creating rotated page object> > pageObj> => reader.pages[page]> > pageObj.rotate(rotation)> > > # adding rotated page object to pdf writer> > pdfWriter.add_page(pageObj)> > > # new pdf file object> > newFile> => open> (newFileName,> 'wb'> )> > > # writing rotated pages to new file> > pdfWriter.write(newFile)> > > # closing the new pdf file object> > newFile.close()> > > def> main():> > > # original pdf file name> > origFileName> => 'example.pdf'> > > # new pdf file name> > newFileName> => 'rotated_example.pdf'> > > # rotation angle> > rotation> => 270> > > # calling the PDFrotate function> > PDFrotate(origFileName, newFileName, rotation)> > if> __name__> => => '__main__'> :> > # calling the main function> > main()> |
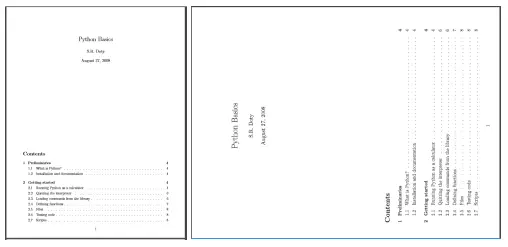
Tutaj możesz zobaczyć, jak wygląda pierwsza strona obrócony_przykład.pdf wygląda (prawy obraz) po obróceniu:

Kilka ważnych punktów związanych z powyższym kodem:
- W celu rotacji najpierw tworzymy obiekt czytnika PDF z oryginalnego pliku PDF.
writer = PdfWriter()
- Obrócone strony zostaną zapisane w nowym pliku PDF. Do zapisu w plikach PDF używamy obiektu PDFWriter klasa modułu pypdf.
for page in range(len(pdfReader.pages)): pageObj = pdfReader.pages[page] pageObj.rotate(rotation) pdfWriter.add_page(pageObj)
- Teraz iterujemy każdą stronę oryginalnego pliku PDF. Otrzymujemy obiekt strony według .strony[] metoda klasy czytnika PDF. Teraz obracamy stronę o obracać się() metoda klasy obiektu strony. Następnie dodajemy stronę do obiektu zapisującego PDF za pomocą dodatek() metoda klasy modułu zapisywania plików PDF poprzez przekazanie obróconego obiektu strony.
newFile = open(newFileName, 'wb') pdfWriter.write(newFile) newFile.close()
- Teraz musimy zapisać strony PDF w nowym pliku PDF. Najpierw otwieramy nowy obiekt plikowy i zapisujemy do niego strony PDF za pomocą pisać() metoda obiektu zapisującego PDF. Na koniec zamykamy oryginalny obiekt pliku PDF i nowy obiekt pliku.
3. Łączenie plików PDF
Pyton
# importing required modules> from> pypdf> import> PdfMerger> > > def> PDFmerge(pdfs, output):> > # creating pdf file merger object> > pdfMerger> => PdfMerger()> > > # appending pdfs one by one> > for> pdf> in> pdfs:> > pdfMerger.append(pdf)> > > # writing combined pdf to output pdf file> > with> open> (output,> 'wb'> ) as f:> > pdfMerger.write(f)> > > def> main():> > # pdf files to merge> > pdfs> => [> 'example.pdf'> ,> 'rotated_example.pdf'> ]> > > # output pdf file name> > output> => 'combined_example.pdf'> > > # calling pdf merge function> > PDFmerge(pdfs> => pdfs, output> => output)> > > if> __name__> => => '__main__'> :> > # calling the main function> > main()> |
Wynikiem powyższego programu jest połączony plik PDF, połączony_przykład.pdf , uzyskane przez połączenie przykład.pdf I obrócony_przykład.pdf .
- Przyjrzyjmy się ważnym aspektom tego programu:
pdfMerger = PdfMerger()
- Do łączenia używamy gotowej klasy, PDFPołączenie modułu pypdf.
Tutaj tworzymy obiekt pdfPołączenie klasy łączenia plików PDF
for pdf in pdfs: pdfmerger.append(open(focus, 'rb'))
- Teraz dołączamy obiekt pliku każdego pliku PDF do obiektu połączenia PDF za pomocą dodać() metoda.
with open(output, 'wb') as f: pdfMerger.write(f)
- Na koniec zapisujemy strony PDF do wyjściowego pliku PDF za pomocą pisać metoda obiektu scalania plików PDF.
4. Dzielenie pliku PDF
Pyton
# importing the required modules> from> pypdf> import> PdfReader, PdfWriter> > def> PDFsplit(pdf, splits):> > # creating pdf reader object> > reader> => PdfReader(pdf)> > > # starting index of first slice> > start> => 0> > > # starting index of last slice> > end> => splits[> 0> ]> > > > for> i> in> range> (> len> (splits)> +> 1> ):> > # creating pdf writer object for (i+1)th split> > writer> => PdfWriter()> > > # output pdf file name> > outputpdf> => pdf.split(> '.pdf'> )[> 0> ]> +> str> (i)> +> '.pdf'> > > # adding pages to pdf writer object> > for> page> in> range> (start,end):> > writer.add_page(reader.pages[page])> > > # writing split pdf pages to pdf file> > with> open> (outputpdf,> 'wb'> ) as f:> > writer.write(f)> > > # interchanging page split start position for next split> > start> => end> > try> :> > # setting split end position for next split> > end> => splits[i> +> 1> ]> > except> IndexError:> > # setting split end position for last split> > end> => len> (reader.pages)> > > def> main():> > # pdf file to split> > pdf> => 'example.pdf'> > > # split page positions> > splits> => [> 2> ,> 4> ]> > > # calling PDFsplit function to split pdf> > PDFsplit(pdf, splits)> > if> __name__> => => '__main__'> :> > # calling the main function> > main()> |
Wynikiem będą trzy nowe pliki PDF z rozszerzeniem podział 1 (strona 0,1), podział 2 (strona 2,3), podział 3 (strona 4-koniec) .
W powyższym programie Pythona nie użyto żadnej nowej funkcji ani klasy. Stosując prostą logikę i iteracje, utworzyliśmy podziały przekazanego pliku PDF zgodnie z przekazaną listą dzieli .
5. Dodawanie znaku wodnego do stron PDF
Pyton
# importing the required modules> from> pypdf> import> PdfReader> > def> add_watermark(wmFile, pageObj):> > # creating pdf reader object of watermark pdf file> > reader> => PdfReader(wmFileObj)> > > # merging watermark pdf's first page with passed page object.> > pageObj.merge_page(reader.pages[> 0> ])> > > # returning watermarked page object> > return> pageObj> > def> main():> > # watermark pdf file name> > mywatermark> => 'watermark.pdf'> > > # original pdf file name> > origFileName> => 'example.pdf'> > > # new pdf file name> > newFileName> => 'watermarked_example.pdf'> > > # creating pdf File object of original pdf> > pdfFileObj> => open> (origFileName,> 'rb'> )> > > # creating a pdf Reader object> > reader> => PdfReader(pdfFileObj)> > > # creating a pdf writer object for new pdf> > writer> => PdfWriter()> > > # adding watermark to each page> > for> page> in> range> (> len> (reader.pages)):> > # creating watermarked page object> > wmpageObj> => add_watermark(mywatermark, reader.pages[page])> > > # adding watermarked page object to pdf writer> > writer.add_page(wmpageObj)> > > # new pdf file object> > newFile> => open> (newFileName,> 'wb'> )> > > # writing watermarked pages to new file> > writer.write(newFile)> > > # closing the new pdf file object> > newFile.close()> > if> __name__> => => '__main__'> :> > # calling the main function> > main()> |
Oto jak wygląda pierwsza strona oryginalnego (po lewej) i znaku wodnego (po prawej) pliku PDF:

- Cały proces jest taki sam, jak w przykładzie rotacji strony. Jedyna różnica to:
wmpageObj = add_watermark(mywatermark, pdfReader.pages[page])
- Obiekt strony jest konwertowany na obiekt strony ze znakiem wodnym za pomocą Dodaj znak wodny() funkcjonować.
- Spróbujmy zrozumieć Dodaj znak wodny() funkcjonować:
reader = PdfReader(wmFile) pageObj.merge_page(reader.pages[0]) wmFileObj.close() return pageObj
- Przede wszystkim tworzymy obiekt czytnika PDF znak wodny.pdf . Do przekazanego obiektu strony używamy merge_page() funkcję i przekazać obiekt strony pierwszej strony obiektu czytnika PDF ze znakiem wodnym. Spowoduje to nałożenie znaku wodnego na przekazany obiekt strony.
I tu dochodzimy do końca tego długiego samouczka na temat pracy z plikami PDF w Pythonie.
Teraz możesz łatwo stworzyć własnego menedżera plików PDF!
Bibliografia:
- https://automatetheboringstuff.com/chapter13/
- https://pypi.org/project/pypdf/
Jeśli podoba Ci się techcodeview.com i chciałbyś wnieść swój wkład, możesz również napisać artykuł za pomocą write.techcodeview.com lub wysłać swój artykuł na adres [email protected]
Napisz komentarz, jeśli znajdziesz coś nieprawidłowego lub jeśli chcesz podzielić się więcej informacjami na temat omówiony powyżej.