Sposoby filtrowania ramki danych Pandas według wartości kolumn

Filtrowanie ramki danych Pandas na podstawie wartości kolumn jest typową operacją podczas pracy z informacjami w języku Python. Aby to osiągnąć, możesz użyć różnych metod i technik. Oto wiele sposobów odfiltrowania ramki danych Pandas poprzez wartości kolumn.
W tym poście zobaczymy różne sposoby filtrowania ramki danych Pandy według wartości kolumn. Najpierw utwórzmy ramkę danych:
Python3
# importing pandas> import> pandas as pd> > # declare a dictionary> record> => {> > 'Name'> : [> 'Ankit'> ,> 'Swapnil'> ,> 'Aishwarya'> ,> > 'Priyanka'> ,> 'Shivangi'> ,> 'Shaurya'> ],> > > 'Age'> : [> 22> ,> 20> ,> 21> ,> 19> ,> 18> ,> 22> ],> > > 'Stream'> : [> 'Math'> ,> 'Commerce'> ,> 'Science'> ,> > 'Math'> ,> 'Math'> ,> 'Science'> ],> > > 'Percentage'> : [> 90> ,> 90> ,> 96> ,> 75> ,> 70> ,> 80> ] }> > # create a dataframe> dataframe> => pd.DataFrame(record,> > columns> => [> 'Name'> ,> 'Age'> ,> > 'Stream'> ,> 'Percentage'> ])> # show the Dataframe> print> (> 'Given Dataframe :
'> , dataframe)> |
Wyjście:

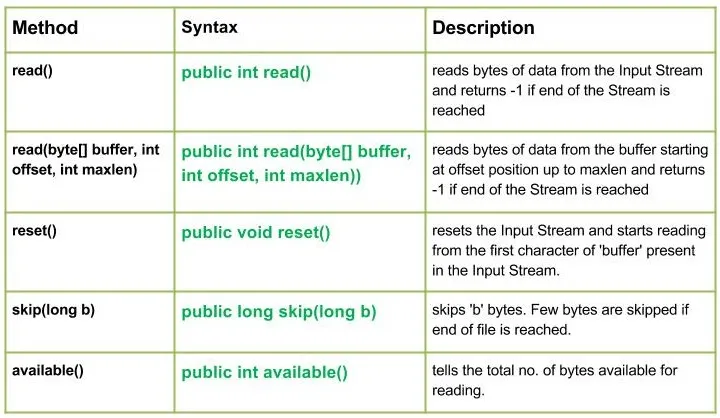
Wybieranie wierszy ramki danych Pandas na podstawie konkretnej wartości kolumny za pomocą operatora „>”, „=”, „=”, „ <=”, „!=”.
Przykład 1: Wybranie wszystkich wierszy z danej ramki danych, w których „Procent” jest większy niż 75 przy użyciu [ ] .
Python3
# selecting rows based on condition> rslt_df> => dataframe[dataframe[> 'Percentage'> ]>> 70> ]> > print> (> '
Result dataframe :
'> , rslt_df)> |
Wyjście:

Przykład 2: Wybranie wszystkich wierszy z danej ramki danych, w których „Procent” jest większy niż 70 przy użyciu miejsce [ ] .
Python3
# selecting rows based on condition> rslt_df> => dataframe.loc[dataframe[> 'Percentage'> ]>> 70> ]> > print> (> '
Result dataframe :
'> ,> > rslt_df)> |
Wyjście:
Wybieranie tych wierszy ramki danych Pandas, których wartość kolumny jest obecna na liście za pomocą Ty() metoda ramki danych.
Przykład 1: Wybranie wszystkich wierszy z danej ramki danych, w której na liście opcji znajduje się „Stream” za pomocą [ ] .
Python3
options> => [> 'Science'> ,> 'Commerce'> ]> > # selecting rows based on condition> rslt_df> => dataframe[dataframe[> 'Stream'> ].isin(options)]> > print> (> '
Result dataframe :
'> ,> > rslt_df)> |
Wyjście:

Przykład 2: Wybranie wszystkich wierszy z danej ramki danych, w której na liście opcji znajduje się „Stream” za pomocą miejsce [ ] .
Pyton
options> => [> 'Science'> ,> 'Commerce'> ]> > # selecting rows based on condition> rslt_df> => dataframe.loc[dataframe[> 'Stream'> ].isin(options)]> > print> (> '
Result dataframe :
'> ,> > rslt_df)> |
Wyjście:
Wybieranie wierszy ramki danych Pandas na podstawie warunków wielu kolumn za pomocą operatora „&”.
Przykład 1: Wybranie wszystkich wierszy z danej ramki danych, w których „Wiek” wynosi 22, a na liście opcji znajduje się „Strumień” za pomocą [ ] .
Python3
options> => [> 'Commerce'> ,> 'Science'> ]> > # selecting rows based on condition> rslt_df> => dataframe[(dataframe[> 'Age'> ]> => => 22> ) &> > dataframe[> 'Stream'> ].isin(options)]> > print> (> '
Result dataframe :
'> ,> > rslt_df)> |
Wyjście:

Przykład 2: Wybranie wszystkich wierszy z danej ramki danych, w których „Wiek” wynosi 22, a na liście opcji znajduje się „Strumień” za pomocą miejsce [ ] .
Python3
options> => [> 'Commerce'> ,> 'Science'> ]> > # selecting rows based on condition> rslt_df> => dataframe.loc[(dataframe[> 'Age'> ]> => => 22> ) &> > dataframe[> 'Stream'> ].isin(options)]> > print> (> '
Result dataframe :
'> ,> > rslt_df)> |
Wyjście: