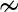Pythona | Pandy.melt()

Aby ułatwić analizę danych w tabeli, możemy przekształcić dane w formę bardziej przyjazną komputerowi, używając Pand w Pythonie. Pandas.melt() jest jedną z funkcji umożliwiających wykonanie tego zadania. Pandas.melt() cofa ramkę DataFrame z formatu szerokiego do formatu długiego.
Pandy topnieją() Funkcja jest przydatna do wmasowania ramki DataFrame do formatu, w którym co najmniej jedna kolumna jest zmiennym identyfikatorem, podczas gdy wszystkie inne kolumny, uważane za zmienne mierzone, nie są obracane względem osi wiersza, pozostawiając tylko dwie kolumny nieidentyfikatorowe, zmienną i wartość.
Składnia funkcji Pandas.melt() w Pythonie
Składnia: pandas.melt(frame, id_vars=Brak, value_vars=Brak,
var_name=Brak, value_name=’wartość’, col_level=Brak)
Parametry:
- rama : Ramka danych
- id_vars[krotka, lista lub ndarray, opcjonalnie] : Kolumny do użycia jako zmienne identyfikatora.
- value_vars[krotka, lista lub ndarray, opcjonalnie]: Kolumny do cofnięcia obrotu. Jeśli nie określono, używa wszystkich kolumn, które nie są ustawione jako id_vars.
- nazwa_zmiennej[skalar]: Nazwa, która będzie używana w kolumnie „zmienna”. Jeśli Brak, używa nazwy ramki.kolumn.lub „zmiennej”.
- nazwa_wartości[skalar, domyślna „wartość”]: Nazwa, która będzie używana w kolumnie „wartość”.
- col_level[int lub string, opcjonalnie]: Jeśli kolumny są MultiIndexem, użyj tego poziomu do stopienia.
Tworzenie przykładowej ramki danych
Tutaj stworzyliśmy przykładową ramkę DataFrame, której użyjemy w tym artykule.
Python3
# importing pandas as pd> import> pandas as pd> # creating a dataframe> df> => pd.DataFrame({> 'Name'> : {> 0> :> 'John'> ,> 1> :> 'Bob'> ,> 2> :> 'Shiela'> },> > 'Course'> : {> 0> :> 'Masters'> ,> 1> :> 'Graduate'> ,> 2> :> 'Graduate'> },> > 'Age'> : {> 0> :> 27> ,> 1> :> 23> ,> 2> :> 21> }})> df> |

Melt () wykonaj w przykładzie Pandy
Poniżej znajduje się przykład wykorzystania funkcji Melt() Pandy na różne sposoby Pandy :
Przykład 1: Pandy Melt() Przykład
W tym przykładzie pd.melt> Funkcja służy do cofnięcia obrotu kolumny „Kurs”, zachowując „Nazwę” jako zmienną identyfikacyjną. Powstała DataFrame ma trzy kolumny: „Nazwa”, „zmienna” (zawierająca nazwę kolumny „Kurs”) i „wartość” (zawierająca odpowiednie wartości z kolumny „Kurs”).
Python3
# Name is id_vars and Course is value_vars> pd.melt(df, id_vars> => [> 'Name'> ], value_vars> => [> 'Course'> ])> |
Wyjście:
Name variable value 0 John Course Masters 1 Bob Course Graduate 2 Shiela Course Graduate
Przykład 2: Użycie id_vars i value_vars do metody Melt() ramki danych Pandas
W tym przykładzie pd.melt> Funkcja służy do cofania obrotu kolumn „Kurs” i „Wiek”, używając „Nazwy” jako zmiennej identyfikacyjnej.
Python3
# multiple unpivot columns> pd.melt(df, id_vars> => [> 'Name'> ], value_vars> => [> 'Course'> ,> 'Age'> ])> |
Wyjście:
Name variable value 0 John Course Masters 1 Bob Course Graduate 2 Shiela Course Graduate 3 John Age 27 4 Bob Age 23 5 Shiela Age 21
Przykład 3: Używanie nazw_zmiennych i nazw_wartości do metody Melt() ramki danych Pandas
W tym przykładzie pd.melt> funkcja jest używana w przypadku niestandardowych nazw kolumn. Kolumna „Kurs” nie jest przestawiana, ale zachowuje „Nazwę” jako identyfikator. Powstała ramka DataFrame zawiera kolumny „Name”, „ChangedVarname” (w przypadku połączonej nazwy kolumny ustawionej na „Course”) i „ChangedValname” (zawierające odpowiednie wartości z kolumny „Course”).
Python3
# Names of ‘variable’ and ‘value’ columns can be customized> pd.melt(df, id_vars> => [> 'Name'> ], value_vars> => [> 'Course'> ],> > var_name> => 'ChangedVarname'> , value_name> => 'ChangedValname'> )> |
Wyjście:
Name ChangedVarname ChangedValname 0 John Course Masters 1 Bob Course Graduate 2 Shiela Course Graduate
Przykład 4: Używanie ignorowania indeksu z funkcją Pandas.melt().
W tym przykładzie pd.melt> Funkcja jest stosowana do cofania obrotu kolumn „Kurs” i „Wiek”, używając „Nazwy” jako zmiennej identyfikacyjnej. Oryginalny indeks jest ignorowany ze względu na ignore_index=True> parametr.
Python3
# multiple unpivot columns with ignore_index> result> => pd.melt(df, id_vars> => [> 'Name'> ], value_vars> => [> 'Course'> ,> 'Age'> ], ignore_index> => True> )> print> (result)> |
Wyjście:
Name variable value 0 John Course Masters 1 Bob Course Graduate 2 Shiela Course Graduate 3 John Age 27 4 Bob Age 23 5 Shiela Age 21