Metoda Corr() DataFrame Pand

Pandy ramka danych.corr() służy do znalezienia korelacji parami wszystkich kolumn w ramce danych Pandas w Pythonie. Każdy NaN wartości są automatycznie wykluczane. Aby zignorować wartości inne niż numeryczne, użyj parametru numeric_only = True. W tym artykule dowiemy się o metodzie DataFrame.corr() w Pyton .
Składnia metody Pandas DataFrame corr().
Składnia: DataFrame.corr(self, method=’pearson’, min_periods=1, numeric_only = False)
Parametry:
- metoda :
- pearsona: standardowy współczynnik korelacji
- kendall: współczynnik korelacji Kendalla Tau
- włócznik: korelacja rangi włócznika
- min_okresy: Minimalna liczba obserwacji wymagana na parę kolumn, aby wynik był ważny. Obecnie dostępne tylko dla korelacji Pearsona i Spearmana
- numeric_only : Określa, czy mają być obsługiwane wyłącznie wartości numeryczne, czy nie. Domyślnie jest ustawiona na Fałsz.
Zwroty: liczba :y: ramka danych
Korelacje danych Pand Metoda corr().
Dobra korelacja zależy od zastosowania, ale można śmiało powiedzieć, że masz co najmniej 0,6 (lub -0,6), aby nazwać ją dobrą korelacją. Prosty przykład pokazujący, jak działa korelacja Pyton .
Python3
import> pandas as pd> df> => {> > 'Array_1'> : [> 30> ,> 70> ,> 100> ],> > 'Array_2'> : [> 65.1> ,> 49.50> ,> 30.7> ]> }> data> => pd.DataFrame(df)> print> (data.corr())> |
Wyjście
Array_1 Array_2 Array_1 1.000000 -0.990773 Array_2 -0.990773 1.000000
Tworzenie przykładowej ramki danych
Drukowanie pierwszych 10 wierszy ramki danych.
Notatka: Korelacja zmiennej ze sobą wynosi 1. Aby uzyskać łącze do pliku CSV Używane w kodzie, kliknij Tutaj
Python3
# importing pandas as pd> import> pandas as pd> # Making data frame from the csv file> df> => pd.read_csv(> 'nba.csv'> )> # Printing the first 10 rows of the data frame for visualization> df[:> 10> ]> |
Wyjście

Przykłady metod DataFrame Corr() w Pythonie Pandy
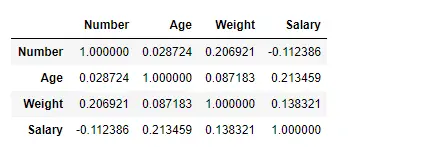
Znajdź korelację między kolumnami, korzystając z metody Pearsona
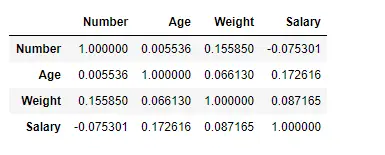
Tutaj używamy funkcji corr(), aby znaleźć korelację między kolumnami w ramce danych przy użyciu metody „Pearsona”. W ramce danych mamy tylko cztery kolumny numeryczne. Wyjściową ramkę danych można zinterpretować tak, jak w przypadku dowolnej komórki, korelacją zmiennej wierszowej ze zmienną kolumnową jest wartość komórki. Jak wspomniano wcześniej, korelacja zmiennej ze sobą wynosi 1. Z tego powodu wszystkie wartości przekątnej wynoszą 1,00.
Python3
# To find the correlation among> # the columns using pearson method> df.corr(method> => 'pearson'> )> |
Wyjście
Znajdź korelację między kolumnami, korzystając z metody Kendalla
Użyj funkcji Pandas df.corr(), aby znaleźć korelację między kolumnami w ramce danych przy użyciu metody „kendall”. Wyjściową ramkę danych można zinterpretować tak, jak w przypadku dowolnej komórki, korelacją zmiennej wierszowej ze zmienną kolumnową jest wartość komórki. Jak wspomniano wcześniej, korelacja zmiennej ze sobą wynosi 1. Z tego powodu wszystkie wartości przekątnej wynoszą 1,00.
Python3
# importing pandas as pd> import> pandas as pd> # Making data frame from the csv file> df> => pd.read_csv(> 'nba.csv'> )> # To find the correlation among> # the columns using kendall method> df.corr(method> => 'kendall'> )> |
Wyjście