Implementacja tabeli mieszającej w Pythonie przy użyciu oddzielnego łączenia łańcuchowego
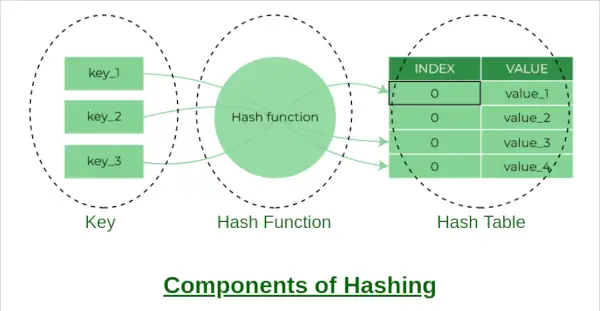
A tablica mieszająca to struktura danych, która pozwala na szybkie wstawianie, usuwanie i odzyskiwanie danych. Działa poprzez użycie funkcji skrótu do mapowania klucza na indeks w tablicy. W tym artykule zaimplementujemy tabelę mieszającą w Pythonie, używając oddzielnego łańcucha do obsługi kolizji.

Składniki hashowania
Oddzielne łączenie łańcuchowe to technika stosowana do obsługi kolizji w tabeli mieszającej. Kiedy dwa lub więcej kluczy jest przypisanych do tego samego indeksu w tablicy, przechowujemy je na połączonej liście pod tym indeksem. Dzięki temu możemy przechowywać wiele wartości w tym samym indeksie i nadal móc je odzyskać za pomocą ich klucza.
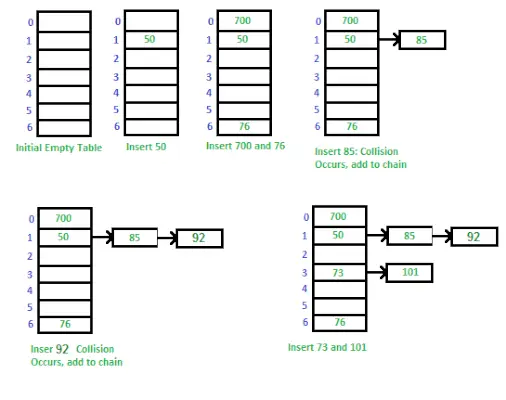
Sposób implementacji tabeli mieszającej przy użyciu oddzielnego łączenia łańcuchowego
Sposób implementacji tabeli mieszającej przy użyciu oddzielnego łączenia łańcuchowego:
Utwórz dwie klasy: „ Węzeł ' I ' Tabela Hash '.
„ Węzeł Klasa „będzie reprezentować węzeł na połączonej liście. Każdy węzeł będzie zawierał parę klucz-wartość, a także wskaźnik do następnego węzła na liście.
Python3
class> Node:> > def> __init__(> self> , key, value):> > self> .key> => key> > self> .value> => value> > self> .> next> => None> |
Klasa „HashTable” będzie zawierać tablicę, w której będą przechowywane połączone listy, a także metody wstawiania, pobierania i usuwania danych z tabeli mieszającej.
Python3
class> HashTable:> > def> __init__(> self> , capacity):> > self> .capacity> => capacity> > self> .size> => 0> > self> .table> => [> None> ]> *> capacity> |
„ __gorący__ Metoda inicjuje tablicę mieszającą o podanej pojemności. Ustawia „ pojemność ' I ' rozmiar ' i inicjuje tablicę na 'Brak'.
Następną metodą jest „ _haszysz ' metoda. Ta metoda pobiera klucz i zwraca indeks w tablicy, w której powinna być przechowywana para klucz-wartość. Użyjemy wbudowanej funkcji skrótu Pythona do zaszyfrowania klucza, a następnie użyjemy operatora modulo, aby uzyskać indeks w tablicy.
Python3
def> _hash(> self> , key):> > return> hash> (key)> %> self> .capacity> |
The 'wstawić' metoda wstawi parę klucz-wartość do tabeli mieszającej. Pobiera indeks, w którym para powinna być przechowywana, za pomocą „ _haszysz ' metoda. Jeśli w tym indeksie nie ma połączonej listy, tworzy nowy węzeł z parą klucz-wartość i ustawia go jako nagłówek listy. Jeśli w tym indeksie znajduje się lista połączona, iteruj po liście, aż znajdziesz ostatni węzeł lub klucz już istnieje, a następnie zaktualizuj wartość, jeśli klucz już istnieje. Jeśli znajdzie klucz, aktualizuje wartość. Jeżeli nie znajdzie klucza, tworzy nowy węzeł i dodaje go na początek listy.
Python3
def> insert(> self> , key, value):> > index> => self> ._hash(key)> > if> self> .table[index]> is> None> :> > self> .table[index]> => Node(key, value)> > self> .size> +> => 1> > else> :> > current> => self> .table[index]> > while> current:> > if> current.key> => => key:> > current.value> => value> > return> > current> => current.> next> > new_node> => Node(key, value)> > new_node.> next> => self> .table[index]> > self> .table[index]> => new_node> > self> .size> +> => 1> |
The szukaj metoda pobiera wartość związaną z danym kluczem. Najpierw pobiera indeks, w którym powinna być przechowywana para klucz-wartość, za pomocą metody _haszysz metoda. Następnie przeszukuje połączoną listę pod tym indeksem w poszukiwaniu klucza. Jeśli znajdzie klucz, zwraca powiązaną wartość. Jeśli nie znajdzie klucza, zgłasza a Błąd klucza .
Python3
def> search(> self> , key):> > index> => self> ._hash(key)> > current> => self> .table[index]> > while> current:> > if> current.key> => => key:> > return> current.value> > current> => current.> next> > raise> KeyError(key)> |
The 'usunąć' Metoda usuwa parę klucz-wartość z tablicy mieszającej. Najpierw pobiera indeks, w którym para powinna być przechowywana, za pomocą ` _haszysz ` metoda. Następnie przeszukuje połączoną listę pod tym indeksem w poszukiwaniu klucza. Jeśli znajdzie klucz, usuwa węzeł z listy. Jeśli nie znajdzie klucza, wywołuje ` Błąd klucza `.
Python3
def> remove(> self> , key):> > index> => self> ._hash(key)> > > previous> => None> > current> => self> .table[index]> > > while> current:> > if> current.key> => => key:> > if> previous:> > previous.> next> => current.> next> > else> :> > self> .table[index]> => current.> next> > self> .size> -> => 1> > return> > previous> => current> > current> => current.> next> > > raise> KeyError(key)> |
„__str__” metoda zwracająca ciąg znaków reprezentujący tabelę skrótów.
Python3
def> __str__(> self> ):> > elements> => []> > for> i> in> range> (> self> .capacity):> > current> => self> .table[i]> > while> current:> > elements.append((current.key, current.value))> > current> => current.> next> > return> str> (elements)> |
Oto pełna implementacja klasy „HashTable”:
Python3
class> Node:> > def> __init__(> self> , key, value):> > self> .key> => key> > self> .value> => value> > self> .> next> => None> > > class> HashTable:> > def> __init__(> self> , capacity):> > self> .capacity> => capacity> > self> .size> => 0> > self> .table> => [> None> ]> *> capacity> > > def> _hash(> self> , key):> > return> hash> (key)> %> self> .capacity> > > def> insert(> self> , key, value):> > index> => self> ._hash(key)> > > if> self> .table[index]> is> None> :> > self> .table[index]> => Node(key, value)> > self> .size> +> => 1> > else> :> > current> => self> .table[index]> > while> current:> > if> current.key> => => key:> > current.value> => value> > return> > current> => current.> next> > new_node> => Node(key, value)> > new_node.> next> => self> .table[index]> > self> .table[index]> => new_node> > self> .size> +> => 1> > > def> search(> self> , key):> > index> => self> ._hash(key)> > > current> => self> .table[index]> > while> current:> > if> current.key> => => key:> > return> current.value> > current> => current.> next> > > raise> KeyError(key)> > > def> remove(> self> , key):> > index> => self> ._hash(key)> > > previous> => None> > current> => self> .table[index]> > > while> current:> > if> current.key> => => key:> > if> previous:> > previous.> next> => current.> next> > else> :> > self> .table[index]> => current.> next> > self> .size> -> => 1> > return> > previous> => current> > current> => current.> next> > > raise> KeyError(key)> > > def> __len__(> self> ):> > return> self> .size> > > def> __contains__(> self> , key):> > try> :> > self> .search(key)> > return> True> > except> KeyError:> > return> False> > > # Driver code> if> __name__> => => '__main__'> :> > > # Create a hash table with> > # a capacity of 5> > ht> => HashTable(> 5> )> > > # Add some key-value pairs> > # to the hash table> > ht.insert(> 'apple'> ,> 3> )> > ht.insert(> 'banana'> ,> 2> )> > ht.insert(> 'cherry'> ,> 5> )> > > # Check if the hash table> > # contains a key> > print> (> 'apple'> in> ht)> # True> > print> (> 'durian'> in> ht)> # False> > > # Get the value for a key> > print> (ht.search(> 'banana'> ))> # 2> > > # Update the value for a key> > ht.insert(> 'banana'> ,> 4> )> > print> (ht.search(> 'banana'> ))> # 4> > > ht.remove(> 'apple'> )> > # Check the size of the hash table> > print> (> len> (ht))> # 3> |
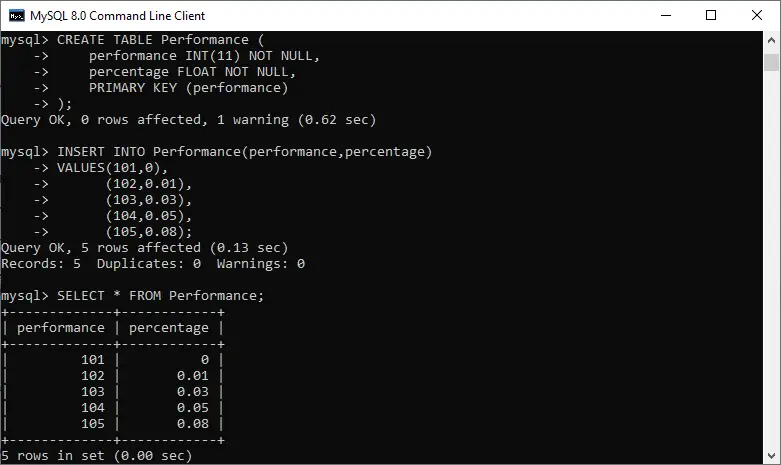
Wyjście
True False 2 4 3
Złożoność czasu i złożoność przestrzeni:
- The złożoność czasu z wstawić , szukaj I usunąć Metody w tabeli mieszającej wykorzystujące oddzielne łańcuchy zależą od rozmiaru tablicy mieszającej, liczby par klucz-wartość w tabeli mieszającej oraz długości połączonej listy w każdym indeksie.
- Zakładając dobrą funkcję skrótu i równomierny rozkład kluczy, oczekiwana złożoność czasowa tych metod wynosi O(1) dla każdej operacji. Jednak w najgorszym przypadku może wystąpić złożoność czasowa NA) , gdzie n to liczba par klucz-wartość w tabeli skrótów.
- Jednakże ważne jest, aby wybrać dobrą funkcję skrótu i odpowiedni rozmiar tablicy mieszającej, aby zminimalizować prawdopodobieństwo kolizji i zapewnić dobrą wydajność.
- The złożoność przestrzeni tabeli mieszającej przy użyciu oddzielnego łączenia łańcuchowego zależy od rozmiaru tablicy mieszającej i liczby par klucz-wartość przechowywanych w tabeli mieszającej.
- Sama tabela mieszająca zajmuje O(m) spacja, gdzie m jest pojemnością tablicy mieszającej. Każdy połączony węzeł listy pobiera O(1) spacja, a na połączonych listach może znajdować się co najwyżej n węzłów, gdzie n to liczba par klucz-wartość przechowywanych w tabeli mieszającej.
- Zatem całkowita złożoność przestrzeni wynosi O(m + n) .
Wniosek:
W praktyce ważne jest, aby wybrać odpowiednią pojemność tablicy mieszającej, aby zrównoważyć wykorzystanie przestrzeni i prawdopodobieństwo kolizji. Jeśli pojemność jest zbyt mała, wzrasta prawdopodobieństwo kolizji, co może spowodować pogorszenie wydajności. Z drugiej strony, jeśli pojemność jest zbyt duża, tabela mieszająca może zużywać więcej pamięci niż to konieczne.