Pandas Series.std()
Pandaene std() er definert som en funksjon for å beregne standardavviket til det gitte settet med tall, DataFrame, kolonne og rader. Når det gjelder å beregne standardavviket, må vi importere pakken som heter ' statistikk ' for beregning av median.
Standardavviket er normalisert av N-1 som standard og kan endres ved hjelp av jeg kommer argument.
Syntaks:
Series.std(axis=None, skipna=None, level=None, ddof=1, numeric_only=None, **kwargs)
Parametere:
Den inkluderer bare flytende, int, boolske kolonner. Hvis det er Ingen, vil det forsøke å bruke alt, så bruk kun numeriske data.
Det er ikke implementert for en serie.
Returnerer:
Den returnerer Series eller DataFrame hvis nivået er spesifisert.
Eksempel 1:
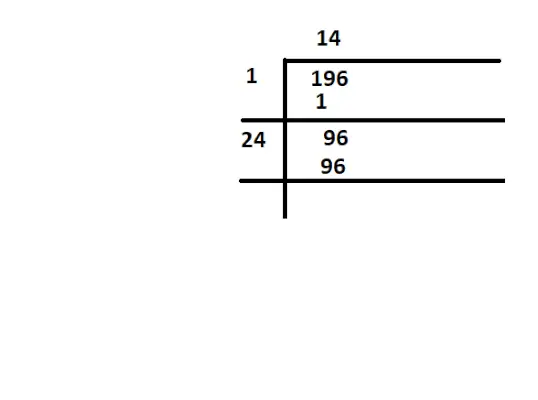
import pandas as pd # calculate standard deviation import numpy as np print(np.std([4,7,2,1,6,3])) print(np.std([6,9,15,2,-17,15,4]))
Produksjon
2.1147629234082532 10.077252622027656
Eksempel 2:
import pandas as pd import numpy as np #Create a DataFrame info = { 'Name':['Parker','Smith','John','William'], 'sub1_Marks':[52,38,42,37], 'sub2_Marks':[41,35,29,36]} data = pd.DataFrame(info) data # standard deviation of the dataframe data.std() Produksjon
sub1_Marks 6.849574 sub2_Marks 4.924429 dtype: float64