Implementering av Hash Table i Python ved hjelp av Separate Chaining
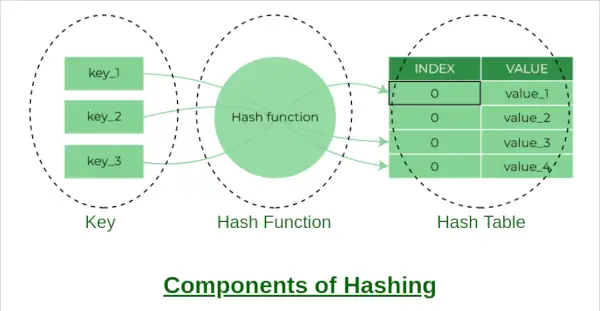
EN hasjtabell er en datastruktur som muliggjør rask innsetting, sletting og gjenfinning av data. Det fungerer ved å bruke en hash-funksjon for å kartlegge en nøkkel til en indeks i en matrise. I denne artikkelen vil vi implementere en hash-tabell i Python ved å bruke separat kjeding for å håndtere kollisjoner.

Komponenter av hashing
Separat kjetting er en teknikk som brukes til å håndtere kollisjoner i en hash-tabell. Når to eller flere nøkler tilordnes den samme indeksen i matrisen, lagrer vi dem i en koblet liste på den indeksen. Dette lar oss lagre flere verdier i samme indeks og fortsatt kunne hente dem ved hjelp av nøkkelen deres.
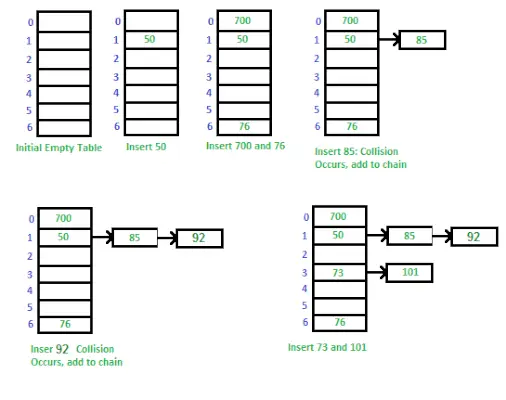
Måte å implementere Hash Table ved hjelp av Separat Chaining
Måte å implementere Hash Table ved hjelp av Separate Chaining:
Lag to klasser: ' Node 'og' HashTable '.
den ' Node ' klasse vil representere en node i en koblet liste. Hver node vil inneholde et nøkkelverdi-par, samt en peker til neste node i listen.
Python3
class> Node:> > def> __init__(> self> , key, value):> > self> .key> => key> > self> .value> => value> > self> .> next> => None> |
‘HashTable’-klassen vil inneholde matrisen som vil inneholde de koblede listene, samt metoder for å sette inn, hente og slette data fra hashtabellen.
Python3
class> HashTable:> > def> __init__(> self> , capacity):> > self> .capacity> => capacity> > self> .size> => 0> > self> .table> => [> None> ]> *> capacity> |
den ' __varmt__ '-metoden initialiserer hashtabellen med en gitt kapasitet. Det setter ' kapasitet 'og' størrelse ' variabler og initialiserer matrisen til 'Ingen'.
Den neste metoden er ' _hash ’ metode. Denne metoden tar en nøkkel og returnerer en indeks i matrisen der nøkkel-verdi-paret skal lagres. Vi vil bruke Pythons innebygde hash-funksjon for å hash nøkkelen og deretter bruke modulo-operatoren for å få en indeks i matrisen.
Python3
def> _hash(> self> , key):> > return> hash> (key)> %> self> .capacity> |
De 'sett inn' metoden vil sette inn et nøkkelverdi-par i hash-tabellen. Den tar indeksen der paret skal lagres ved å bruke ' _hash ’ metode. Hvis det ikke er noen koblet liste ved den indeksen, oppretter den en ny node med nøkkelverdi-paret og setter den som leder for listen. Hvis det er en koblet liste ved den indeksen, gjenta gjennom listen til den siste noden er funnet eller nøkkelen allerede eksisterer, og oppdater verdien hvis nøkkelen allerede eksisterer. Hvis den finner nøkkelen, oppdaterer den verdien. Hvis den ikke finner nøkkelen, oppretter den en ny node og legger den til i toppen av listen.
Python3
def> insert(> self> , key, value):> > index> => self> ._hash(key)> > if> self> .table[index]> is> None> :> > self> .table[index]> => Node(key, value)> > self> .size> +> => 1> > else> :> > current> => self> .table[index]> > while> current:> > if> current.key> => => key:> > current.value> => value> > return> > current> => current.> next> > new_node> => Node(key, value)> > new_node.> next> => self> .table[index]> > self> .table[index]> => new_node> > self> .size> +> => 1> |
De Søk metoden henter verdien knyttet til en gitt nøkkel. Den får først indeksen der nøkkelverdi-paret skal lagres ved å bruke _hash metode. Den søker deretter i den koblede listen i den indeksen etter nøkkelen. Hvis den finner nøkkelen, returnerer den den tilknyttede verdien. Hvis den ikke finner nøkkelen, hever den en KeyError .
Python3
def> search(> self> , key):> > index> => self> ._hash(key)> > current> => self> .table[index]> > while> current:> > if> current.key> => => key:> > return> current.value> > current> => current.> next> > raise> KeyError(key)> |
De 'fjerne' metoden fjerner et nøkkelverdi-par fra hashtabellen. Den får først indeksen der paret skal lagres ved å bruke ` _hash ` metode. Den søker deretter i den koblede listen i den indeksen etter nøkkelen. Hvis den finner nøkkelen, fjerner den noden fra listen. Hvis den ikke finner nøkkelen, hever den en ` KeyError `.
Python3
def> remove(> self> , key):> > index> => self> ._hash(key)> > > previous> => None> > current> => self> .table[index]> > > while> current:> > if> current.key> => => key:> > if> previous:> > previous.> next> => current.> next> > else> :> > self> .table[index]> => current.> next> > self> .size> -> => 1> > return> > previous> => current> > current> => current.> next> > > raise> KeyError(key)> |
'__str__' metode som returnerer en strengrepresentasjon av hashtabellen.
Python3
def> __str__(> self> ):> > elements> => []> > for> i> in> range> (> self> .capacity):> > current> => self> .table[i]> > while> current:> > elements.append((current.key, current.value))> > current> => current.> next> > return> str> (elements)> |
Her er den komplette implementeringen av 'HashTable'-klassen:
Python3
class> Node:> > def> __init__(> self> , key, value):> > self> .key> => key> > self> .value> => value> > self> .> next> => None> > > class> HashTable:> > def> __init__(> self> , capacity):> > self> .capacity> => capacity> > self> .size> => 0> > self> .table> => [> None> ]> *> capacity> > > def> _hash(> self> , key):> > return> hash> (key)> %> self> .capacity> > > def> insert(> self> , key, value):> > index> => self> ._hash(key)> > > if> self> .table[index]> is> None> :> > self> .table[index]> => Node(key, value)> > self> .size> +> => 1> > else> :> > current> => self> .table[index]> > while> current:> > if> current.key> => => key:> > current.value> => value> > return> > current> => current.> next> > new_node> => Node(key, value)> > new_node.> next> => self> .table[index]> > self> .table[index]> => new_node> > self> .size> +> => 1> > > def> search(> self> , key):> > index> => self> ._hash(key)> > > current> => self> .table[index]> > while> current:> > if> current.key> => => key:> > return> current.value> > current> => current.> next> > > raise> KeyError(key)> > > def> remove(> self> , key):> > index> => self> ._hash(key)> > > previous> => None> > current> => self> .table[index]> > > while> current:> > if> current.key> => => key:> > if> previous:> > previous.> next> => current.> next> > else> :> > self> .table[index]> => current.> next> > self> .size> -> => 1> > return> > previous> => current> > current> => current.> next> > > raise> KeyError(key)> > > def> __len__(> self> ):> > return> self> .size> > > def> __contains__(> self> , key):> > try> :> > self> .search(key)> > return> True> > except> KeyError:> > return> False> > > # Driver code> if> __name__> => => '__main__'> :> > > # Create a hash table with> > # a capacity of 5> > ht> => HashTable(> 5> )> > > # Add some key-value pairs> > # to the hash table> > ht.insert(> 'apple'> ,> 3> )> > ht.insert(> 'banana'> ,> 2> )> > ht.insert(> 'cherry'> ,> 5> )> > > # Check if the hash table> > # contains a key> > print> (> 'apple'> in> ht)> # True> > print> (> 'durian'> in> ht)> # False> > > # Get the value for a key> > print> (ht.search(> 'banana'> ))> # 2> > > # Update the value for a key> > ht.insert(> 'banana'> ,> 4> )> > print> (ht.search(> 'banana'> ))> # 4> > > ht.remove(> 'apple'> )> > # Check the size of the hash table> > print> (> len> (ht))> # 3> |
Produksjon
True False 2 4 3
Tidskompleksitet og romkompleksitet:
- De tidskompleksitet av sett inn , Søk og fjerne metoder i en hashtabell som bruker separat kjeding, avhenger av størrelsen på hashtabellen, antall nøkkelverdi-par i hashtabellen og lengden på den koblede listen ved hver indeks.
- Forutsatt en god hash-funksjon og en jevn fordeling av nøkler, er den forventede tidskompleksiteten til disse metodene O(1) for hver operasjon. Men i verste fall kan tidskompleksiteten være På) , hvor n er antall nøkkelverdi-par i hashtabellen.
- Det er imidlertid viktig å velge en god hashfunksjon og en passende størrelse på hashtabellen for å minimere sannsynligheten for kollisjoner og sikre god ytelse.
- De plass kompleksitet av en hashtabell som bruker separat kjeding, avhenger av størrelsen på hashtabellen og antall nøkkelverdipar som er lagret i hashtabellen.
- Selve hashtabellen tar O(m) plass, der m er kapasiteten til hashtabellen. Hver koblet listenode tar O(1) mellomrom, og det kan maksimalt være n noder i de koblede listene, der n er antall nøkkelverdi-par som er lagret i hashtabellen.
- Derfor er den totale plasskompleksiteten O(m + n) .
Konklusjon:
I praksis er det viktig å velge en passende kapasitet for hashtabellen for å balansere plassbruken og sannsynligheten for kollisjoner. Hvis kapasiteten er for liten, øker sannsynligheten for kollisjoner, noe som kan føre til forringelse av ytelsen. På den annen side, hvis kapasiteten er for stor, kan hashtabellen bruke mer minne enn nødvendig.