Darbs ar PDF failiem programmā Python
Jums visiem ir jāzina, kas ir PDF faili. Patiesībā tie ir viens no svarīgākajiem un visplašāk izmantotajiem digitālajiem medijiem. PDF apzīmē Portatīvā dokumenta formāts . Tā izmanto .pdf pagarinājumu. To izmanto, lai droši iesniegtu un apmainītos ar dokumentiem neatkarīgi no programmatūras, aparatūras vai operētājsistēmas.
Izgudroja Adobe , PDF tagad ir atvērts standarts, ko uztur Starptautiskā standartizācijas organizācija (ISO). PDF failos var būt saites un pogas, veidlapu lauki, audio, video un biznesa loģika.
Šajā rakstā mēs uzzināsim, kā mēs varam veikt dažādas darbības, piemēram:
- Teksta izvilkšana no PDF
- Rotējošas PDF lapas
- PDF failu sapludināšana
- PDF sadalīšana
- Ūdenszīmes pievienošana PDF lapām
Uzstādīšana: Izmantojot vienkāršus python skriptus!
Mēs izmantosim trešās puses moduli pypdf.
pypdf ir python bibliotēka, kas izveidota kā PDF rīkkopa. Tas spēj:
- Dokumenta informācijas izvilkšana (nosaukums, autors, …)
- Dokumentu sadalīšana pa lappusēm
- Dokumentu sapludināšana pa lappusei
- Lapu apgriešana
- Vairāku lapu sapludināšana vienā lapā
- PDF failu šifrēšana un atšifrēšana
- un vēl!
Lai instalētu pypdf, komandrindā palaidiet šādu komandu:
pip install pypdf
Šis moduļa nosaukums ir reģistrjutīgs, tāpēc pārliecinieties, vai un ir mazie un viss pārējais ir lielie. Ir pieejami visi šajā apmācībā/rakstā izmantotie kodi un PDF faili šeit .
1. Teksta izvilkšana no PDF faila
Python
# importing required classes> from> pypdf> import> PdfReader> > # creating a pdf reader object> reader> => PdfReader(> 'example.pdf'> )> > # printing number of pages in pdf file> print> (> len> (reader.pages))> > # creating a page object> page> => reader.pages[> 0> ]> > # extracting text from page> print> (page.extract_text())> |
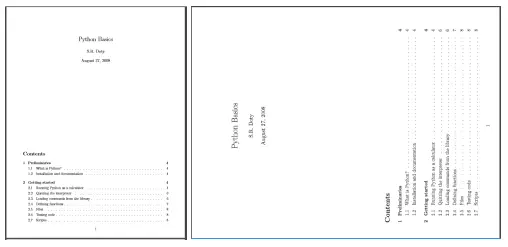
Iepriekš minētās programmas izvade izskatās šādi:
20 PythonBasics S.R.Doty August27,2008 Contents 1Preliminaries 4 1.1WhatisPython?................................... ..4 1.2Installationanddocumentation.................... .........4 [and some more lines...]
Mēģināsim saprast iepriekš minēto kodu pa daļām:
reader = PdfReader('example.pdf') - Šeit mēs izveidojam objektu PdfReader pypdf moduļa klases un nododiet ceļu uz PDF failu un iegūstiet PDF lasītāja objektu.
print(len(reader.pages))
- lapas rekvizīts norāda PDF faila lappušu skaitu. Piemēram, mūsu gadījumā tas ir 20 (skatiet pirmo izvades rindiņu).
pageObj = reader.pages[0]
- Tagad mēs izveidojam objektu Lapas objekts pypdf moduļa klase. PDF lasītāja objektam ir funkcija lapas[] kas izmanto lapas numuru (sākot no indeksa 0) kā argumentu un atgriež lapas objektu.
print(pageObj.extract_text())
- Lapas objektam ir funkcija ekstrakts_teksts() lai izvilktu tekstu no PDF lapas.
Piezīme: Lai gan PDF faili ir lieliski piemēroti teksta izkārtojumam tā, lai cilvēki tos varētu viegli izdrukāt un lasīt, programmatūrai tos nav vienkārši parsēt vienkāršā tekstā. Tādējādi pypdf var kļūdīties, izvelkot tekstu no PDF faila, un pat nevarēs atvērt dažus PDF failus. Diemžēl šajā jomā jūs nevarat daudz darīt. pypdf, iespējams, vienkārši nevar strādāt ar dažiem jūsu konkrētajiem PDF failiem.
2. Rotējošas PDF lapas
Python
# importing the required classes> from> pypdf> import> PdfReader, PdfWriter> > def> PDFrotate(origFileName, newFileName, rotation):> > > # creating a pdf Reader object> > reader> => PdfReader(origFileName)> > > # creating a pdf writer object for new pdf> > writer> => PdfWriter()> > > # rotating each page> > for> page> in> range> (> len> (reader.pages)):> > > # creating rotated page object> > pageObj> => reader.pages[page]> > pageObj.rotate(rotation)> > > # adding rotated page object to pdf writer> > pdfWriter.add_page(pageObj)> > > # new pdf file object> > newFile> => open> (newFileName,> 'wb'> )> > > # writing rotated pages to new file> > pdfWriter.write(newFile)> > > # closing the new pdf file object> > newFile.close()> > > def> main():> > > # original pdf file name> > origFileName> => 'example.pdf'> > > # new pdf file name> > newFileName> => 'rotated_example.pdf'> > > # rotation angle> > rotation> => 270> > > # calling the PDFrotate function> > PDFrotate(origFileName, newFileName, rotation)> > if> __name__> => => '__main__'> :> > # calling the main function> > main()> |
Šeit jūs varat redzēt, kā pirmajā lapā rotated_example.pdf izskatās (attēls labajā pusē) pēc pagriešanas:

Daži svarīgi punkti saistībā ar iepriekš minēto kodu:
- Lai veiktu rotāciju, mēs vispirms izveidojam sākotnējā PDF PDF lasītāja objektu.
writer = PdfWriter()
- Pagrieztās lapas tiks ierakstītas jaunā PDF failā. Lai rakstītu PDF failos, mēs izmantojam objektu PdfWriter pypdf moduļa klase.
for page in range(len(pdfReader.pages)): pageObj = pdfReader.pages[page] pageObj.rotate(rotation) pdfWriter.add_page(pageObj)
- Tagad mēs atkārtojam katru sākotnējā PDF lapu. Mēs iegūstam lapas objektu ar .pages[] PDF lasītāja klases metode. Tagad mēs pagriežam lapu par pagriezt () lapas objektu klases metode. Pēc tam mēs pievienojam lapu PDF rakstīšanas objektam, izmantojot papildinājums () PDF rakstīšanas klases metode, nododot pagriezto lapas objektu.
newFile = open(newFileName, 'wb') pdfWriter.write(newFile) newFile.close()
- Tagad mums ir jāraksta PDF lapas jaunā PDF failā. Pirmkārt, mēs atveram jauno faila objektu un ierakstām tajā PDF lapas, izmantojot rakstīt () PDF rakstīšanas objekta metode. Visbeidzot, mēs aizveram sākotnējo PDF faila objektu un jauno faila objektu.
3. PDF failu sapludināšana
Python
# importing required modules> from> pypdf> import> PdfMerger> > > def> PDFmerge(pdfs, output):> > # creating pdf file merger object> > pdfMerger> => PdfMerger()> > > # appending pdfs one by one> > for> pdf> in> pdfs:> > pdfMerger.append(pdf)> > > # writing combined pdf to output pdf file> > with> open> (output,> 'wb'> ) as f:> > pdfMerger.write(f)> > > def> main():> > # pdf files to merge> > pdfs> => [> 'example.pdf'> ,> 'rotated_example.pdf'> ]> > > # output pdf file name> > output> => 'combined_example.pdf'> > > # calling pdf merge function> > PDFmerge(pdfs> => pdfs, output> => output)> > > if> __name__> => => '__main__'> :> > # calling the main function> > main()> |
Iepriekš minētās programmas izvade ir apvienots PDF fails, kombinētais_piemērs.pdf , iegūti apvienojot example.pdf un rotated_example.pdf .
- Apskatīsim šīs programmas svarīgos aspektus:
pdfMerger = PdfMerger()
- Apvienošanai mēs izmantojam iepriekš izveidotu klasi, PdfMerger pypdf modulis.
Šeit mēs izveidojam objektu pdfApvienošanās PDF apvienošanas klases
for pdf in pdfs: pdfmerger.append(open(focus, 'rb'))
- Tagad mēs pievienojam katra PDF faila objektu PDF apvienošanas objektam, izmantojot pievienot () metodi.
with open(output, 'wb') as f: pdfMerger.write(f)
- Visbeidzot, mēs ierakstām PDF lapas izvades PDF failā, izmantojot rakstīt PDF apvienošanas objekta metode.
4. PDF faila sadalīšana
Python
# importing the required modules> from> pypdf> import> PdfReader, PdfWriter> > def> PDFsplit(pdf, splits):> > # creating pdf reader object> > reader> => PdfReader(pdf)> > > # starting index of first slice> > start> => 0> > > # starting index of last slice> > end> => splits[> 0> ]> > > > for> i> in> range> (> len> (splits)> +> 1> ):> > # creating pdf writer object for (i+1)th split> > writer> => PdfWriter()> > > # output pdf file name> > outputpdf> => pdf.split(> '.pdf'> )[> 0> ]> +> str> (i)> +> '.pdf'> > > # adding pages to pdf writer object> > for> page> in> range> (start,end):> > writer.add_page(reader.pages[page])> > > # writing split pdf pages to pdf file> > with> open> (outputpdf,> 'wb'> ) as f:> > writer.write(f)> > > # interchanging page split start position for next split> > start> => end> > try> :> > # setting split end position for next split> > end> => splits[i> +> 1> ]> > except> IndexError:> > # setting split end position for last split> > end> => len> (reader.pages)> > > def> main():> > # pdf file to split> > pdf> => 'example.pdf'> > > # split page positions> > splits> => [> 2> ,> 4> ]> > > # calling PDFsplit function to split pdf> > PDFsplit(pdf, splits)> > if> __name__> => => '__main__'> :> > # calling the main function> > main()> |
Izvade būs trīs jauni PDF faili ar 1. sadaļa (0,1. lapa), 2. sadaļa (2.,3. lapa), 3. sadaļa (4. lapa) .
Iepriekš minētajā python programmā nav izmantota neviena jauna funkcija vai klase. Izmantojot vienkāršu loģiku un iterācijas, mēs izveidojām nodoto PDF sadalījumus atbilstoši nokārtoto sarakstu sadalās .
5. Ūdenszīmes pievienošana PDF lapām
Python
# importing the required modules> from> pypdf> import> PdfReader> > def> add_watermark(wmFile, pageObj):> > # creating pdf reader object of watermark pdf file> > reader> => PdfReader(wmFileObj)> > > # merging watermark pdf's first page with passed page object.> > pageObj.merge_page(reader.pages[> 0> ])> > > # returning watermarked page object> > return> pageObj> > def> main():> > # watermark pdf file name> > mywatermark> => 'watermark.pdf'> > > # original pdf file name> > origFileName> => 'example.pdf'> > > # new pdf file name> > newFileName> => 'watermarked_example.pdf'> > > # creating pdf File object of original pdf> > pdfFileObj> => open> (origFileName,> 'rb'> )> > > # creating a pdf Reader object> > reader> => PdfReader(pdfFileObj)> > > # creating a pdf writer object for new pdf> > writer> => PdfWriter()> > > # adding watermark to each page> > for> page> in> range> (> len> (reader.pages)):> > # creating watermarked page object> > wmpageObj> => add_watermark(mywatermark, reader.pages[page])> > > # adding watermarked page object to pdf writer> > writer.add_page(wmpageObj)> > > # new pdf file object> > newFile> => open> (newFileName,> 'wb'> )> > > # writing watermarked pages to new file> > writer.write(newFile)> > > # closing the new pdf file object> > newFile.close()> > if> __name__> => => '__main__'> :> > # calling the main function> > main()> |
Lūk, kā izskatās sākotnējā (pa kreisi) un ūdenszīmes (labajā) PDF faila pirmā lapa:

- Viss process ir tāds pats kā lapas rotācijas piemērā. Vienīgā atšķirība ir:
wmpageObj = add_watermark(mywatermark, pdfReader.pages[page])
- Lapas objekts tiek pārveidots par ūdenszīmi lapas objektu, izmantojot add_watermark() funkciju.
- Mēģināsim saprast add_watermark() funkcija:
reader = PdfReader(wmFile) pageObj.merge_page(reader.pages[0]) wmFileObj.close() return pageObj
- Pirmkārt, mēs izveidojam PDF lasītāja objektu ūdenszīme.pdf . Lai nodotu lapas objektu, mēs izmantojam sapludināt_lapu() funkciju un nododiet ūdenszīmes PDF lasītāja objekta pirmās lapas lapas objektu. Tādējādi ūdenszīme tiks pārklāta pār nodoto lapas objektu.
Un šeit mēs sasniedzam šīs garās apmācības par darbu ar PDF failiem programmā python beigas.
Tagad jūs varat viegli izveidot savu PDF pārvaldnieku!
Atsauces:
- https://automatetheboringstuff.com/chapter13/
- https://pypi.org/project/pypdf/
Ja jums patīk techcodeview.com un vēlaties sniegt savu ieguldījumu, varat arī uzrakstīt rakstu, izmantojot write.techcodeview.com, vai nosūtīt savu rakstu uz e-pastu [email protected]
Lūdzu, rakstiet komentārus, ja atrodat kaut ko nepareizu vai vēlaties dalīties ar plašāku informāciju par iepriekš apspriesto tēmu.