Datu analīze ar Python
Šajā rakstā mēs apspriedīsim, kā veikt datu analīzi, izmantojot Python. Mēs apspriedīsim visu veidu datu analīzi, t.i., skaitlisko datu analīzi ar NumPy, tabulu datu analīzi ar Pandas, datu vizualizāciju Matplotlib un izpētes datu analīzi.
Datu analīze ar Python
Datu analīze ir datu vākšanas, pārveidošanas un kārtošanas paņēmiens, lai veiktu nākotnes prognozes un uz datiem balstītus lēmumus. Tas arī palīdz atrast iespējamos biznesa problēmas risinājumus. Datu analīzei ir seši soļi. Viņi ir:
- Jautājiet vai norādiet datu prasības
- Sagatavojiet vai vāciet datus
- Tīrīšana un apstrāde
- Analizēt
- Dalīties
- Rīkojieties vai ziņojiet
Datu analīze ar Python
Piezīme: Lai uzzinātu vairāk par šīm darbībām, skatiet mūsu NumPy ir masīvu apstrādes pakotne programmā Python un nodrošina augstas veiktspējas daudzdimensiju masīva objektu un rīkus darbam ar šiem masīviem. Tā ir pamatpakete zinātniskai skaitļošanai ar Python.
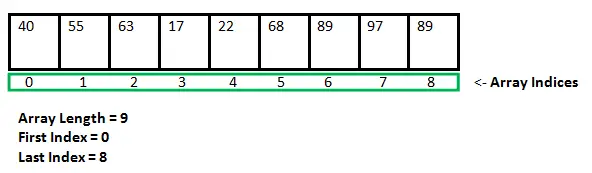
Masīvi valodā NumPy
NumPy masīvs ir viena un tā paša veida elementu (parasti skaitļu) tabula, kas indeksēta ar pozitīvu veselu skaitļu virkni. Programmā Numpy masīva izmēru skaitu sauc par masīva rangu. Veselu skaitļu kopa, kas norāda masīva lielumu katrā dimensijā, ir pazīstama kā masīva forma.
NumPy masīva izveide
NumPy masīvus var izveidot vairākos veidos ar dažādām rindām. To var arī izveidot, izmantojot dažādus datu tipus, piemēram, sarakstus, korešus utt. Rezultātā iegūtā masīva veids tiek secināts no sekvenču elementu veida. NumPy piedāvā vairākas funkcijas, lai izveidotu masīvus ar sākotnējo viettura saturu. Tie samazina masīvu audzēšanas nepieciešamību, kas ir dārga darbība.
Izveidojiet masīvu, izmantojot numpy.empty(forma, dtype=float, order='C')
Python3import numpy as np b = np.empty(2, dtype = int) print('Matrix b :
', b) a = np.empty([2, 2], dtype = int) print('
Matrix a :
', a) c = np.empty([3, 3]) print('
Matrix c :
', c) Izvade:

Iztukšojiet matricu, izmantojot pandas
Izveidojiet masīvu, izmantojot numpy.zeros(forma, dtype = nav, secība = 'C')
Python3import numpy as np b = np.zeros(2, dtype = int) print('Matrix b :
', b) a = np.zeros([2, 2], dtype = int) print('
Matrix a :
', a) c = np.zeros([3, 3]) print('
Matrix c :
', c) Izvade:
Matrix b : [0 0] Matrix a : [[0 0] [0 0]] Matrix c : [[0. 0. 0.] [0. 0. 0.] [0. 0. 0.]]
Operācijas ar Numpy Arrays
Aritmētiskās operācijas
- Papildinājums:
import numpy as np # Defining both the matrices a = np.array([5, 72, 13, 100]) b = np.array([2, 5, 10, 30]) # Performing addition using arithmetic operator add_ans = a+b print(add_ans) # Performing addition using numpy function add_ans = np.add(a, b) print(add_ans) # The same functions and operations can be used for # multiple matrices c = np.array([1, 2, 3, 4]) add_ans = a+b+c print(add_ans) add_ans = np.add(a, b, c) print(add_ans)
Izvade:
[ 7 77 23 130] [ 7 77 23 130] [ 8 79 26 134] [ 7 77 23 130]
- Atņemšana:
import numpy as np # Defining both the matrices a = np.array([5, 72, 13, 100]) b = np.array([2, 5, 10, 30]) # Performing subtraction using arithmetic operator sub_ans = a-b print(sub_ans) # Performing subtraction using numpy function sub_ans = np.subtract(a, b) print(sub_ans)
Izvade:
[ 3 67 3 70] [ 3 67 3 70]
- Reizināšana:
import numpy as np # Defining both the matrices a = np.array([5, 72, 13, 100]) b = np.array([2, 5, 10, 30]) # Performing multiplication using arithmetic # operator mul_ans = a*b print(mul_ans) # Performing multiplication using numpy function mul_ans = np.multiply(a, b) print(mul_ans)
Izvade:
[ 10 360 130 3000] [ 10 360 130 3000]
- Nodaļa:
import numpy as np # Defining both the matrices a = np.array([5, 72, 13, 100]) b = np.array([2, 5, 10, 30]) # Performing division using arithmetic operators div_ans = a/b print(div_ans) # Performing division using numpy functions div_ans = np.divide(a, b) print(div_ans)
Izvade:
[ 2.5 14.4 1.3 3.33333333] [ 2.5 14.4 1.3 3.33333333]
Lai iegūtu papildinformāciju, skatiet mūsu NumPy — aritmētisko darbību apmācība
NumPy masīva indeksēšana
Indeksēšana var izdarīt NumPy, izmantojot masīvu kā indeksu. Šķēles gadījumā tiek atgriezts skats vai sekla masīva kopija, bet indeksu masīvā tiek atgriezta sākotnējā masīva kopija. Numpy masīvus var indeksēt ar citiem masīviem vai jebkuru citu secību, izņemot korešus. Pēdējais elements tiek indeksēts ar -1 sekundi, pēdējais ar -2 un tā tālāk.
Python NumPy masīva indeksācija
Python3# Python program to demonstrate # the use of index arrays. import numpy as np # Create a sequence of integers from # 10 to 1 with a step of -2 a = np.arange(10, 1, -2) print('
A sequential array with a negative step:
',a) # Indexes are specified inside the np.array method. newarr = a[np.array([3, 1, 2 ])] print('
Elements at these indices are:
',newarr) Izvade:
A sequential array with a negative step: [10 8 6 4 2] Elements at these indices are: [4 8 6]
NumPy masīva sagriešana
Apsveriet sintaksi x[obj], kur x ir masīvs un obj ir indekss. Šķēles objekts ir indekss gadījumā pamata sagriešana . Pamata sagriešana notiek, ja obj ir:
- šķēles objekts, kura forma ir sākums: apstāšanās: solis
- vesels skaitlis
- vai slāņu objektu un veselu skaitļu kopa
Visi masīvi, kas ģenerēti, izmantojot pamata sadalīšanu, vienmēr ir sākotnējā masīva skats.
Python3# Python program for basic slicing. import numpy as np # Arrange elements from 0 to 19 a = np.arange(20) print('
Array is:
',a) # a[start:stop:step] print('
a[-8:17:1] = ',a[-8:17:1]) # The : operator means all elements till the end. print('
a[10:] = ',a[10:]) Izvade:
Array is: [ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19] a[-8:17:1] = [12 13 14 15 16] a[10:] = [10 11 12 13 14 15 16 17 18 19]
Elipses var izmantot arī kopā ar pamata sagriešanu. Elipse (…) ir : objektu skaits, kas nepieciešams, lai izveidotu atlases kopu, kuras garums ir vienāds ar masīva izmēriem.
Python3# Python program for indexing using basic slicing with ellipsis import numpy as np # A 3 dimensional array. b = np.array([[[1, 2, 3],[4, 5, 6]], [[7, 8, 9],[10, 11, 12]]]) print(b[...,1]) #Equivalent to b[: ,: ,1 ]
Izvade:
[[ 2 5] [ 8 11]]
NumPy masīva apraide
Termiņš apraide attiecas uz to, kā numpy apstrādā masīvus ar dažādiem izmēriem aritmētisko darbību laikā, kas rada noteiktus ierobežojumus, mazākais masīvs tiek pārraidīts pa lielāko masīvu, lai tiem būtu saderīgas formas.
Pieņemsim, ka mums ir liela datu kopa, katrs atskaites punkts ir parametru saraksts. Programmā Numpy mums ir 2-D masīvs, kur katra rinda ir atskaites punkts, un rindu skaits ir datu kopas lielums. Pieņemsim, ka mēs vēlamies visiem šiem datiem piemērot sava veida mērogošanu, katrs parametrs iegūst savu mērogošanas koeficientu vai sakiet, ka Katrs parametrs tiek reizināts ar kādu faktoru.
Lai iegūtu skaidru izpratni, saskaitīsim kalorijas pārtikas produktos, izmantojot makroelementu sadalījumu. Aptuveni sakot, pārtikas kaloriju daļas sastāv no taukiem (9 kalorijas uz gramu), olbaltumvielām (4 CPG) un ogļhidrātiem (4 CPG). Tātad, ja mēs uzskaitām dažus pārtikas produktus (mūsu dati) un katram pārtikas produktam uzskaitām tā makroelementu sadalījumu (parametrus), mēs varam reizināt katru uzturvielu ar tās kaloriju vērtību (piemērot mērogošanu), lai aprēķinātu katras pārtikas preces kaloriju sadalījumu.

Izmantojot šo transformāciju, mēs tagad varam aprēķināt visu veidu noderīgu informāciju. Piemēram, kāds ir kopējais kaloriju skaits dažos pārtikas produktos vai, ņemot vērā manu vakariņu sadalījumu, zināt, cik daudz kaloriju es saņēmu no olbaltumvielām un tā tālāk.
Apskatīsim naivu veidu, kā izveidot šo aprēķinu, izmantojot Numpy:
Python3import numpy as np macros = np.array([ [0.8, 2.9, 3.9], [52.4, 23.6, 36.5], [55.2, 31.7, 23.9], [14.4, 11, 4.9] ]) # Create a new array filled with zeros, # of the same shape as macros. result = np.zeros_like(macros) cal_per_macro = np.array([3, 3, 8]) # Now multiply each row of macros by # cal_per_macro. In Numpy, `*` is # element-wise multiplication between two arrays. for i in range(macros.shape[0]): result[i, :] = macros[i, :] * cal_per_macro result
Izvade:
array([[ 2.4, 8.7, 31.2], [157.2, 70.8, 292. ], [165.6, 95.1, 191.2], [ 43.2, 33. , 39.2]])
Apraides noteikumi: Divu masīvu apraide kopā ievēro šādus noteikumus:
- Ja masīviem nav vienāda ranga, pievienojiet zemākā ranga masīva formu ar 1, līdz abām formām ir vienāds garums.
- Abi masīvi ir saderīgi pēc dimensijas, ja to izmēri ir vienādi vai ja vienam no masīviem šajā dimensijā ir 1. izmērs.
- Masīvus var pārraidīt kopā, ja tie ir saderīgi ar visiem izmēriem.
- Pēc apraides katrs masīvs darbojas tā, it kā tam būtu forma, kas vienāda ar divu ievades masīvu formu maksimumu.
- Jebkurā dimensijā, kur viena masīva izmērs ir 1, bet otra masīva izmērs ir lielāks par 1, pirmais masīvs darbojas tā, it kā tas tiktu kopēts pa šo dimensiju.
import numpy as np v = np.array([12, 24, 36]) w = np.array([45, 55]) # To compute an outer product we first # reshape v to a column vector of shape 3x1 # then broadcast it against w to yield an output # of shape 3x2 which is the outer product of v and w print(np.reshape(v, (3, 1)) * w) X = np.array([[12, 22, 33], [45, 55, 66]]) # x has shape 2x3 and v has shape (3, ) # so they broadcast to 2x3, print(X + v) # Add a vector to each column of a matrix X has # shape 2x3 and w has shape (2, ) If we transpose X # then it has shape 3x2 and can be broadcast against w # to yield a result of shape 3x2. # Transposing this yields the final result # of shape 2x3 which is the matrix. print((X.T + w).T) # Another solution is to reshape w to be a column # vector of shape 2X1 we can then broadcast it # directly against X to produce the same output. print(X + np.reshape(w, (2, 1))) # Multiply a matrix by a constant, X has shape 2x3. # Numpy treats scalars as arrays of shape(); # these can be broadcast together to shape 2x3. print(X * 2)
Izvade:
[[ 540 660] [1080 1320] [1620 1980]] [[ 24 46 69] [ 57 79 102]] [[ 57 67 78] [100 110 121]] [[ 57 67 78] [100 110 121]] [[ 24 44 66] [ 90 110 132]]
Piezīme: Lai iegūtu papildinformāciju, skatiet mūsu Python NumPy apmācība .
Datu analīze, izmantojot Pandas
Python Pandas tiek izmantots relāciju vai marķētiem datiem un nodrošina dažādas datu struktūras, lai manipulētu ar šādiem datiem un laikrindām. Šī bibliotēka ir izveidota uz NumPy bibliotēkas. Šis modulis parasti tiek importēts kā:
import pandas as pd
Šeit pd tiek saukts par Pandas aizstājvārdu. Tomēr nav nepieciešams importēt bibliotēku, izmantojot aizstājvārdu, tas tikai palīdz rakstīt mazāku summas kodu katru reizi, kad tiek izsaukta metode vai rekvizīts. Pandas parasti nodrošina divas datu struktūras, lai manipulētu ar datiem. Tās ir:
- sērija
- Datu rāmis
Sērija:
Pandas sērija ir viendimensionāls marķēts masīvs, kas spēj glabāt jebkura veida datus (veselus skaitļus, virkni, pludiņu, python objektus utt.). Asu etiķetes kopā sauc par indeksiem. Pandas sērija ir nekas cits kā kolonna Excel lapā. Etiķetēm nav jābūt unikālām, bet tām ir jābūt jaukta tipa. Objekts atbalsta gan veselu skaitļu, gan etiķešu indeksēšanu un nodrošina virkni metožu darbību veikšanai, kas saistītas ar indeksu.
Pandas sērija
To var izveidot, izmantojot funkciju Series(), ielādējot datu kopu no esošās krātuves, piemēram, SQL, datu bāzes, CSV faili, Excel faili utt., vai no datu struktūrām, piemēram, sarakstiem, vārdnīcām utt.
Python Pandas izveides sērija
Python3import pandas as pd import numpy as np # Creating empty series ser = pd.Series() print(ser) # simple array data = np.array(['g', 'e', 'e', 'k', 's']) ser = pd.Series(data) print(ser)
Izvade:

pnadas sērija
Datu rāmis:
Pandas DataFrame ir divdimensiju izmēra mainīga, potenciāli neviendabīga tabulu datu struktūra ar iezīmētām asīm (rindām un kolonnām). Datu rāmis ir divdimensiju datu struktūra, t.i., dati tiek izlīdzināti tabulas veidā rindās un kolonnās. Pandas DataFrame sastāv no trim galvenajām sastāvdaļām — datiem, rindām un kolonnām.
Pandas datu rāmis
To var izveidot, izmantojot Dataframe() metodi, un tāpat kā sēriju, tā var būt arī no dažādiem failu tipiem un datu struktūrām.
Python Pandas datu rāmja izveide
Python3import pandas as pd # Calling DataFrame constructor df = pd.DataFrame() print(df) # list of strings lst = ['Geeks', 'For', 'Geeks', 'is', 'portal', 'for', 'Geeks'] # Calling DataFrame constructor on list df = pd.DataFrame(lst) df
Izvade:

Dataframe izveide no python saraksta
Datu rāmja izveide no CSV
Mēs varam izveidot datu rāmi no CSV failus, izmantojot lasīt_csv() funkciju.
Python Pandas lasa CSV
Python3import pandas as pd # Reading the CSV file df = pd.read_csv('Iris.csv') # Printing top 5 rows df.head() Izvade:

datu rāmja galva
DataFrame filtrēšana
Pandas dataframe.filter() funkcija tiek izmantota datu rāmja rindu vai kolonnu apakškopai atbilstoši norādītā indeksa etiķetēm. Ņemiet vērā, ka šī rutīna nefiltrē datu rāmi pēc tā satura. Filtrs tiek lietots indeksa etiķetēm.
Python Pandas filtra datu rāmis
Python3import pandas as pd # Reading the CSV file df = pd.read_csv('Iris.csv') # applying filter function df.filter(['Species', 'SepalLengthCm', 'SepalLengthCm']).head() Izvade:

Datu kopai tiek lietots filtrs
DataFrame kārtošana
Lai kārtotu datu rāmi pandās, funkcija sort_values() tiek izmantots. Pandas sort_values() var kārtot datu rāmi augošā vai dilstošā secībā.
Python Pandas datu rāmja kārtošana augošā secībā
Izvade:

Sakārtota datu kopa, pamatojoties uz kolonnas vērtību
Pandas GroupBy
Groupby ir diezgan vienkāršs jēdziens. Mēs varam izveidot kategoriju grupu un lietot kategorijām funkciju. Reālos datu zinātnes projektos jums būs jārisina liels datu apjoms un jāmēģina lietas atkal un atkal, tāpēc efektivitātes labad mēs izmantojam Groupby koncepciju. Groupby galvenokārt attiecas uz procesu, kas ietver vienu vai vairākas no šīm darbībām:
- Sadalīšana: Tas ir process, kurā mēs sadalām datus grupās, piemērojot dažus nosacījumus datu kopām.
- Pieteikšanās: Tas ir process, kurā mēs katrai grupai piemērojam funkciju neatkarīgi.
- Apvienojot: Tas ir process, kurā mēs apvienojam dažādas datu kopas pēc groupby un rezultātu lietošanas datu struktūrā.
Šis attēls palīdzēs izprast procesu, kas saistīts ar Groupby koncepciju.
1. Grupējiet unikālās vērtības no kolonnas Komanda
Pandas Groupby metode
2. Tagad katrai grupai ir savs spainis
3. Ievietojiet pārējos datus spainīšos

4. Katra spaiņa svara kolonnā lietojiet funkciju.
Funkcijas lietošana katras kolonnas svara kolonnā
Python Pandas GroupBy
Python3# importing pandas module import pandas as pd # Define a dictionary containing employee data data1 = {'Name': ['Jai', 'Anuj', 'Jai', 'Princi', 'Gaurav', 'Anuj', 'Princi', 'Abhi'], 'Age': [27, 24, 22, 32, 33, 36, 27, 32], 'Address': ['Nagpur', 'Kanpur', 'Allahabad', 'Kannuaj', 'Jaunpur', 'Kanpur', 'Allahabad', 'Aligarh'], 'Qualification': ['Msc', 'MA', 'MCA', 'Phd', 'B.Tech', 'B.com', 'Msc', 'MA']} # Convert the dictionary into DataFrame df = pd.DataFrame(data1) print('Original Dataframe') display(df) # applying groupby() function to # group the data on Name value. gk = df.groupby('Name') # Let's print the first entries # in all the groups formed. print('After Creating Groups') gk.first() Izvade:

pandas groupby
Funkcijas lietošana grupai:
Pēc datu sadalīšanas grupā katrai grupai piemērojam funkciju, lai veiktu dažas darbības, tās ir:
- Apkopošana: Tas ir process, kurā mēs aprēķinām kopsavilkuma statistiku (vai statistiku) par katru grupu. Piemēram, Aprēķiniet grupu summas vai vidējos rādītājus
- Transformācija: Tas ir process, kurā mēs veicam dažus grupai raksturīgus aprēķinus un atgriežam līdzīgu indeksu. Piemēram, NA aizpildīšana grupās ar vērtību, kas iegūta no katras grupas
- Filtrēšana: Tas ir process, kurā mēs atmetam dažas grupas saskaņā ar grupu aprēķinu, kas novērtē patieso vai nepatieso. Piemēram, datu filtrēšana, pamatojoties uz grupas summu vai vidējo
Pandas agregācija
Apkopošana ir process, kurā mēs aprēķinām kopsavilkuma statistiku par katru grupu. Apkopotā funkcija katrai grupai atgriež vienu apkopotu vērtību. Pēc datu sadalīšanas grupās, izmantojot funkciju groupby, grupētajiem datiem var veikt vairākas apkopošanas darbības.
Python Pandas agregācija
Python3# importing pandas module import pandas as pd # importing numpy as np import numpy as np # Define a dictionary containing employee data data1 = {'Name': ['Jai', 'Anuj', 'Jai', 'Princi', 'Gaurav', 'Anuj', 'Princi', 'Abhi'], 'Age': [27, 24, 22, 32, 33, 36, 27, 32], 'Address': ['Nagpur', 'Kanpur', 'Allahabad', 'Kannuaj', 'Jaunpur', 'Kanpur', 'Allahabad', 'Aligarh'], 'Qualification': ['Msc', 'MA', 'MCA', 'Phd', 'B.Tech', 'B.com', 'Msc', 'MA']} # Convert the dictionary into DataFrame df = pd.DataFrame(data1) # performing aggregation using # aggregate method grp1 = df.groupby('Name') grp1.aggregate(np.sum) Izvade:

Summēšanas funkcijas izmantošana datu kopā
DataFrame savienošana
Lai savienotu datu rāmi, mēs izmantojam concat () funkcija, kas palīdz savienot datu rāmi. Šī funkcija veic visus smagus uzdevumus, kas saistīti ar savienošanas darbību veikšanu kopā ar Pandas objektu asi, vienlaikus veicot izvēles kopas loģiku (savienojumu vai krustojumu) indeksiem (ja tādi ir) uz citām asīm.
Python Pandas savieno datu rāmi
Python3# importing pandas module import pandas as pd # Define a dictionary containing employee data data1 = {'key': ['K0', 'K1', 'K2', 'K3'], 'Name':['Jai', 'Princi', 'Gaurav', 'Anuj'], 'Age':[27, 24, 22, 32],} # Define a dictionary containing employee data data2 = {'key': ['K0', 'K1', 'K2', 'K3'], 'Address':['Nagpur', 'Kanpur', 'Allahabad', 'Kannuaj'], 'Qualification':['Btech', 'B.A', 'Bcom', 'B.hons']} # Convert the dictionary into DataFrame df = pd.DataFrame(data1) # Convert the dictionary into DataFrame df1 = pd.DataFrame(data2) display(df, df1) # combining series and dataframe res = pd.concat([df, df1], axis=1) res Izvade:

DataFrame sapludināšana
Ja mums ir jāapvieno ļoti lieli datu rāmji, savienojumi kalpo kā spēcīgs veids, kā ātri veikt šīs darbības. Savienojumus var veikt tikai divos DataFrame vienlaikus, kas apzīmēti kā kreisās un labās puses tabulas. Galvenais ir kopējā kolonna, kurā tiks savienoti divi DataFrame. Lai izvairītos no nejaušas rindu vērtību dublēšanās, ieteicams visā kolonnā izmantot atslēgas, kurām ir unikālas vērtības. Pandas nodrošina vienu funkciju, sapludināt () , kā ievades punkts visām standarta datu bāzes savienošanas darbībām starp DataFrame objektiem.
Ir četri pamata veidi, kā apstrādāt savienojumu (iekšējā, kreisā, labā un ārējā), atkarībā no tā, kurās rindās ir jāsaglabā dati.

Python Pandas sapludināt datu rāmi
Python3# importing pandas module import pandas as pd # Define a dictionary containing employee data data1 = {'key': ['K0', 'K1', 'K2', 'K3'], 'Name':['Jai', 'Princi', 'Gaurav', 'Anuj'], 'Age':[27, 24, 22, 32],} # Define a dictionary containing employee data data2 = {'key': ['K0', 'K1', 'K2', 'K3'], 'Address':['Nagpur', 'Kanpur', 'Allahabad', 'Kannuaj'], 'Qualification':['Btech', 'B.A', 'Bcom', 'B.hons']} # Convert the dictionary into DataFrame df = pd.DataFrame(data1) # Convert the dictionary into DataFrame df1 = pd.DataFrame(data2) display(df, df1) # using .merge() function res = pd.merge(df, df1, on='key') res Izvade:

Savieno divas datu kopas
Pievienošanās DataFrame
Lai pievienotos datu rāmim, mēs izmantojam .join() šī funkcija tiek izmantota, lai apvienotu divu potenciāli atšķirīgi indeksētu DataFrame kolonnu vienā rezultāta DataFrame.
Python Pandas pievienojas Dataframe
Python3# importing pandas module import pandas as pd # Define a dictionary containing employee data data1 = {'Name':['Jai', 'Princi', 'Gaurav', 'Anuj'], 'Age':[27, 24, 22, 32]} # Define a dictionary containing employee data data2 = {'Address':['Allahabad', 'Kannuaj', 'Allahabad', 'Kannuaj'], 'Qualification':['MCA', 'Phd', 'Bcom', 'B.hons']} # Convert the dictionary into DataFrame df = pd.DataFrame(data1,index=['K0', 'K1', 'K2', 'K3']) # Convert the dictionary into DataFrame df1 = pd.DataFrame(data2, index=['K0', 'K2', 'K3', 'K4']) display(df, df1) # joining dataframe res = df.join(df1) res Izvade:

Divu datu kopu savienošana
Lai iegūtu papildinformāciju, skatiet mūsu Pandu sapludināšana, pievienošana un savienošana pamācība
Pilnu ceļvedi par pandām skatiet mūsu Pandas apmācība .
Vizualizācija ar Matplotlib
Matplotlib ir viegli lietojams un pārsteidzoša vizualizējoša bibliotēka Python. Tas ir veidots uz NumPy masīviem un paredzēts darbam ar plašāku SciPy steksu, un tas sastāv no vairākiem grafikiem, piemēram, līnijas, joslas, izkliedes, histogrammas utt.
Pyplot
Pyplot ir Matplotlib modulis, kas nodrošina MATLAB līdzīgu saskarni. Pyplot nodrošina funkcijas, kas mijiedarbojas ar figūru, t.i., izveido figūru, izrotā sižetu ar etiķetēm un izveido attēlā zīmēšanas laukumu.
Python3# Python program to show pyplot module import matplotlib.pyplot as plt plt.plot([1, 2, 3, 4], [1, 4, 9, 16]) plt.axis([0, 6, 0, 20]) plt.show()
Izvade:

Joslu diagramma
A bāra gabals vai joslu diagramma ir diagramma, kas attēlo datu kategoriju ar taisnstūrveida joslām, kuru garums un augstums ir proporcionāls to attēlotajām vērtībām. Stieņu diagrammas var tikt attēlotas horizontāli vai vertikāli. Joslu diagramma apraksta diskrēto kategoriju salīdzinājumus. To var izveidot, izmantojot bar() metodi.
Python Matplotlib joslu diagramma
Šeit mēs izmantosim tikai varavīksnenes datu kopu
Python3import matplotlib.pyplot as plt import pandas as pd df = pd.read_csv('Iris.csv') # This will plot a simple bar chart plt.bar(df['Species'], df['SepalLengthCm']) # Title to the plot plt.title('Iris Dataset') # Adding the legends plt.legend(['bar']) plt.show() Izvade:

Joslu diagramma, izmantojot Matplotlib bibliotēku
Histogrammas
A histogramma pamatā izmanto, lai attēlotu datus dažu grupu veidā. Tas ir joslu diagrammas veids, kurā X ass apzīmē bin diapazonus, bet Y ass sniedz informāciju par frekvenci. Lai izveidotu histogrammu, pirmais solis ir izveidot diapazonu kopu, pēc tam sadalīt visu vērtību diapazonu intervālu sērijā un saskaitīt vērtības, kas ietilpst katrā no intervāliem. Tvertnes ir skaidri identificētas kā secīgi mainīgo lielumu intervāli, kas nepārklājas. The hist () funkcija tiek izmantota, lai aprēķinātu un izveidotu x histogrammu.
Python Matplotlib histogramma
Python3import matplotlib.pyplot as plt import pandas as pd df = pd.read_csv('Iris.csv') plt.hist(df['SepalLengthCm']) # Title to the plot plt.title('Histogram') # Adding the legends plt.legend(['SepalLengthCm']) plt.show() Izvade:

Histplot, izmantojot Matplotlib bibliotēku
Izkliedes diagramma
Izkliedes diagrammas tiek izmantotas, lai novērotu attiecības starp mainīgajiem, un izmanto punktus, lai attēlotu attiecības starp tiem. The izkliedēt () Metode matplotlib bibliotēkā tiek izmantota, lai uzzīmētu izkliedes diagrammu.
Python Matplotlib izkliedes diagramma
Python3import matplotlib.pyplot as plt import pandas as pd df = pd.read_csv('Iris.csv') plt.scatter(df['Species'], df['SepalLengthCm']) # Title to the plot plt.title('Scatter Plot') # Adding the legends plt.legend(['SepalLengthCm']) plt.show() Izvade:

Izkliedes diagramma, izmantojot Matplotlib bibliotēku
Kastes gabals
A boxplot ,Korelācija pazīstama arī kā kastes un ūsu gabals. Tas ir ļoti labs vizuāls attēlojums, kad runa ir par datu sadalījuma mērīšanu. Skaidri attēlo vidējās vērtības, novirzes un kvartiles. Datu izplatīšanas izpratne ir vēl viens svarīgs faktors, kas nodrošina labāku modeļa izveidi. Ja datiem ir novirzes, lodziņa diagramma ir ieteicamais veids, kā tos identificēt un veikt nepieciešamās darbības. Lodziņu un ūsu diagramma parāda, kā dati tiek sadalīti. Diagrammā parasti ir iekļautas piecas informācijas daļas
- Minimums ir parādīts diagrammas kreisajā malā, kreisās “ūsas” beigās
- Pirmā kvartile, Q1, ir lodziņa galējā kreisā puse (kreisā ūsa)
- Mediāna ir parādīta kā līnija lodziņa centrā
- Trešā kvartile, Q3, parādīta lodziņa labajā malā (labā ūsa)
- Maksimums ir kastes labajā malā
Kastes sižeta attēlojums

Starpkvartiļu diapazons

Ilustrējošs kastes sižets
Python Matplotlib Box Plot
Python3import matplotlib.pyplot as plt import pandas as pd df = pd.read_csv('Iris.csv') plt.boxplot(df['SepalWidthCm']) # Title to the plot plt.title('Box Plot') # Adding the legends plt.legend(['SepalWidthCm']) plt.show() Izvade:

Boxplot, izmantojot Matplotlib bibliotēku
Korelācijas siltuma kartes
2-D siltuma karte ir datu vizualizācijas rīks, kas palīdz attēlot parādības lielumu krāsu veidā. Korelācijas siltuma karte ir siltuma karte, kas parāda 2D korelācijas matricu starp divām atsevišķām dimensijām, izmantojot krāsainas šūnas, lai attēlotu datus no parasti monohromatiskas skalas. Pirmās kategorijas vērtības tiek rādītas kā tabulas rindas, bet otrās kategorijas vērtības ir kolonna. Šūnas krāsa ir proporcionāla mērījumu skaitam, kas atbilst izmēru vērtībai. Tas padara korelācijas siltuma kartes ideāli piemērotas datu analīzei, jo tas padara modeļus viegli lasāmus un izceļ atšķirības un atšķirības tajos pašos datos. Korelācijas siltuma karti, tāpat kā parasto siltuma karti, palīdz krāsu josla, kas padara datus viegli lasāmus un saprotamus.
Piezīme: Šeit sniegtie dati ir jānodod ar corr() metodi, lai izveidotu korelācijas siltuma karti. Arī pati corr () novērš kolonnas, kas nebūs noderīgas, ģenerējot korelācijas siltuma karti, un atlasa tās, kuras var izmantot.
Python Matplotlib korelācijas siltuma karte
Python3import matplotlib.pyplot as plt import pandas as pd df = pd.read_csv('Iris.csv') plt.imshow(df.corr() , cmap = 'autumn' , interpolation = 'nearest' ) plt.title('Heat Map') plt.show() Izvade:

Siltuma karte, izmantojot Matplotlib bibliotēku
Lai iegūtu papildinformāciju par datu vizualizāciju, skatiet mūsu tālāk norādītās apmācības -
- Piezīme: Mēs izmantosim Iris datu kopu.
Informācijas iegūšana par datu kopu
Mēs izmantosim formas parametru, lai iegūtu datu kopas formu.
Datu rāmja forma
Python3df.shapeIzvade:
(150, 6)Mēs redzam, ka datu rāmis satur 6 kolonnas un 150 rindas.
Piezīme: Mēs izmantosim Iris datu kopu.
Informācijas iegūšana par datu kopu
Tagad apskatīsim arī kolonnas un to datu tipus. Šim nolūkam mēs izmantosim info() metodi.
Informācija par datu kopu
Python3df.info()Izvade:

informācija par datu kopu
Mēs redzam, ka tikai vienā kolonnā ir kategoriski dati, un visas pārējās kolonnas ir ciparu tipa ar ierakstiem, kas nav Null.
Iegūsim ātru datu kopas statistikas kopsavilkumu, izmantojot aprakstīt () metodi. Funkcija description() izmanto pamata statistikas aprēķinus datu kopā, piemēram, galējās vērtības, datu punktu standarta novirzes skaitu utt. Jebkura trūkstošā vērtība vai NaN vērtība tiek automātiski izlaista. Funkcija description() sniedz labu priekšstatu par datu sadalījumu.
Datu kopas apraksts
Python3df.describe()Izvade:

Apraksts par datu kopu
Mēs varam redzēt katras kolonnas skaitu, kā arī to vidējo vērtību, standarta novirzi, minimālās un maksimālās vērtības.
Trūkstošo vērtību pārbaude
Mēs pārbaudīsim, vai mūsu datos ir trūkstošās vērtības. Trūkst vērtības var rasties, ja netiek sniegta informācija par vienu vai vairākiem vienumiem vai par visu vienību. Mēs izmantosim isnull() metodi.
python kods trūkstošai vērtībai
Python3df.isnull().sum()Izvade:

Datu kopā trūkst vērtību
Mēs redzam, ka nevienai kolonnai nav trūkstošas vērtības.
Dublikātu pārbaude
Apskatīsim, vai mūsu datu kopā ir dublikāti. Pandas drop_dublikāti() metode palīdz noņemt dublikātus no datu rāmja.
Pandas funkcija trūkstošām vērtībām
Python3data = df.drop_duplicates(subset ='Species',) dataIzvade:

Notiek dublikāta vērtības nomešana datu kopā
Mēs redzam, ka ir tikai trīs unikālas sugas. Redzēsim, vai datu kopa ir līdzsvarota vai nav, t.i., visās sugās ir vienāds rindu daudzums vai nav. Mēs izmantosim Series.value_counts() funkciju. Šī funkcija atgriež sēriju, kurā ir unikālo vērtību skaits.
Python kods vērtību skaitam kolonnā
Python3df.value_counts('Species')Izvade:

vērtību skaits datu kopā
Mēs redzam, ka visās sugās ir vienāds skaits rindu, tāpēc nevajadzētu dzēst nevienu ierakstu.
Attiecības starp mainīgajiem
Mēs redzēsim saistību starp sepal garumu un platumu, kā arī starp ziedlapas garumu un ziedlapas platumu.
Sepal garuma un sepal platuma salīdzināšana
Python3# importing packages import seaborn as sns import matplotlib.pyplot as plt sns.scatterplot(x='SepalLengthCm', y='SepalWidthCm', hue='Species', data=df, ) # Placing Legend outside the Figure plt.legend(bbox_to_anchor=(1, 1), loc=2) plt.show()Izvade:

Izkliedes diagramma, izmantojot Matplotlib bibliotēku
No iepriekš minētā sižeta mēs varam secināt, ka -
- Setosa sugai ir mazāks kauslapu garums, bet lielāks kauslapu platums.
- Versicolor Sugas atrodas starp pārējām divām sugām kauslapu garuma un platuma ziņā
- Virdžīnikas sugai ir lielāks kauslapu garums, bet mazāks kauslapu platums.
Ziedlapu garuma un platuma salīdzināšana
Python3# importing packages import seaborn as sns import matplotlib.pyplot as plt sns.scatterplot(x='PetalLengthCm', y='PetalWidthCm', hue='Species', data=df, ) # Placing Legend outside the Figure plt.legend(bbox_to_anchor=(1, 1), loc=2) plt.show()Izvade:

sactter zemes gabala ziedlapu garums
No iepriekš minētā sižeta mēs varam secināt, ka -
- Setosa sugai ir mazāks ziedlapu garums un platums.
- Versicolor Sugas atrodas starp pārējām divām sugām ziedlapu garuma un platuma ziņā
- Virdžīnikas sugai ir vislielākais ziedlapu garums un platums.
Uzzīmēsim visas kolonnas attiecības, izmantojot pāru diagrammu. To var izmantot daudzfaktoru analīzei.
Python kods pairplot
Python3# importing packages import seaborn as sns import matplotlib.pyplot as plt sns.pairplot(df.drop(['Id'], axis = 1), hue='Species', height=2)Izvade:
Pāru diagramma datu kopai
No šī sižeta mēs varam redzēt daudzu veidu attiecības, piemēram, sugai Seotsa ir vismazākais ziedlapu platums un garums. Tam ir arī mazākais kauslapu garums, bet lielāks kauslapu platums. Šādu informāciju var iegūt par jebkuru citu sugu.
Apstrādes korelācija
Pandas dataframe.corr() tiek izmantots, lai atrastu visu datu rāmja kolonnu pāru korelāciju. Visas NA vērtības tiek automātiski izslēgtas. Jebkādas datu tipa kolonnas, kas nav skaitliski, datu ietvarā tiek ignorētas.
Piemērs:
Python3data.corr(method='pearson')Izvade:

korelācija starp kolonnām datu kopā
Siltuma kartes
Siltuma karte ir datu vizualizācijas paņēmiens, ko izmanto, lai analizētu datu kopu kā krāsas divās dimensijās. Būtībā tas parāda korelāciju starp visiem datu kopas skaitliskiem mainīgajiem. Vienkāršāk sakot, mēs varam attēlot iepriekš atrasto korelāciju, izmantojot siltuma kartes.
python kods siltuma kartei
Python3# importing packages import seaborn as sns import matplotlib.pyplot as plt sns.heatmap(df.corr(method='pearson').drop( ['Id'], axis=1).drop(['Id'], axis=0), annot = True); plt.show()Izvade:

Siltuma karte korelācijai datu kopā
No iepriekš redzamā grafika mēs varam redzēt, ka -
- Ziedlapu platumam un garumam ir augsta korelācija.
- Ziedlapu garumam un sepal platumam ir laba korelācija.
- Ziedlapu platumam un sepal garumam ir laba korelācija.
Ārējo rādītāju apstrāde
Ārējais rādītājs ir datu vienums/objekts, kas būtiski atšķiras no pārējiem (tā sauktajiem parastajiem) objektiem. Tos var izraisīt mērījumu vai izpildes kļūdas. Ārējo rādītāju noteikšanas analīzi sauc par izņēmuma ieguvi. Ir daudz veidu, kā noteikt novirzes, un noņemšanas process ir tāds pats datu ietvars kā datu vienuma noņemšana no pandas datu rāmja.
Apskatīsim varavīksnenes datu kopu un uzzīmēsim SepalWidthCm kolonnas lodziņu.
python kods Boxplot
Python3# importing packages import seaborn as sns import matplotlib.pyplot as plt # Load the dataset df = pd.read_csv('Iris.csv') sns.boxplot(x='SepalWidthCm', data=df)Izvade:

Boxplot sepalwidth kolonnai
Iepriekš redzamajā diagrammā vērtības virs 4 un zem 2 darbojas kā novirzes.
Noviržu noņemšana
Lai noņemtu nobīdi, ir jāveic tas pats ieraksta noņemšanas process no datu kopas, izmantojot precīzu tā atrašanās vietu datu kopā, jo visās iepriekš minētajās izņēmuma noteikšanas metodēs galarezultāts ir visu to datu vienību saraksts, kas atbilst nobīdes definīcijai. atbilstoši izmantotajai metodei.
Mēs noteiksim novirzes, izmantojot IQR un tad mēs tos noņemsim. Mēs arī uzzīmēsim boxplot, lai redzētu, vai novirzes ir noņemtas vai nav.
Python3# Importing import sklearn from sklearn.datasets import load_boston import pandas as pd import seaborn as sns # Load the dataset df = pd.read_csv('Iris.csv') # IQR Q1 = np.percentile(df['SepalWidthCm'], 25, interpolation = 'midpoint') Q3 = np.percentile(df['SepalWidthCm'], 75, interpolation = 'midpoint') IQR = Q3 - Q1 print('Old Shape: ', df.shape) # Upper bound upper = np.where(df['SepalWidthCm']>= (Q3+1,5*IQR)) # Apakšējā robeža apakšējā = np.where(df['SepalWidthCm'] <= (Q1-1.5*IQR)) # Removing the Outliers df.drop(upper[0], inplace = True) df.drop(lower[0], inplace = True) print('New Shape: ', df.shape) sns.boxplot(x='SepalWidthCm', data=df)Izvade:

boxplot, izmantojot seaborn bibliotēku
Lai iegūtu papildinformāciju par EDA, skatiet mūsu tālāk norādītās apmācības -