넘파이 엔다레이
Ndarray는 유사한 유형의 요소 컬렉션을 저장하는 numpy에 정의된 n차원 배열 개체입니다. 즉, ndarray를 데이터 유형(dtype) 객체의 컬렉션으로 정의할 수 있습니다.
ndarray 객체는 0 기반 인덱싱을 사용하여 액세스할 수 있습니다. Array 객체의 각 요소는 메모리에 동일한 크기를 포함합니다.
ndarray 객체 생성
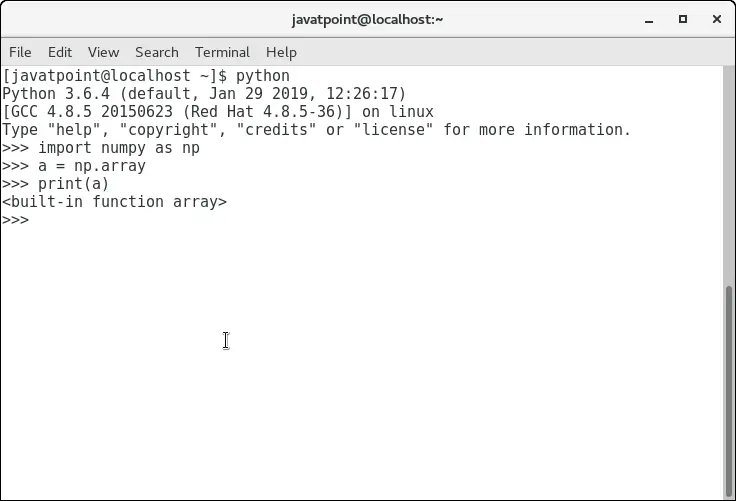
ndarray 객체는 numpy 모듈의 배열 루틴을 사용하여 생성할 수 있습니다. 이를 위해서는 numpy를 가져와야 합니다.
>>> a = numpy.array
아래 이미지를 고려하십시오.

또한 컬렉션 개체를 배열 루틴에 전달하여 동등한 n차원 배열을 만들 수도 있습니다. 구문은 아래와 같습니다.
>>> numpy.array(object, dtype = None, copy = True, order = None, subok = False, ndmin = 0)
매개변수는 다음 표에 설명되어 있습니다.
| SN | 매개변수 | 설명 |
|---|---|---|
| 1 | 물체 | 컬렉션 개체를 나타냅니다. 리스트, 튜플, 딕셔너리, 세트 등이 될 수 있습니다. |
| 2 | dtype | 이 옵션을 지정된 유형으로 변경하여 배열 요소의 데이터 유형을 변경할 수 있습니다. 기본값은 없음입니다. |
| 삼 | 복사 | 선택 사항입니다. 기본적으로 이는 객체가 복사되었음을 의미하는 true입니다. |
| 4 | 주문하다 | 이 옵션에는 3가지 값을 할당할 수 있습니다. C(열 순서), R(행 순서) 또는 A(임의)일 수 있습니다. |
| 5 | 테스트를 거쳤습니다. | 반환된 배열은 기본적으로 기본 클래스 배열이 됩니다. 이 옵션을 true로 설정하여 하위 클래스가 통과하도록 변경할 수 있습니다. |
| 6 | ndmin | 결과 배열의 최소 크기를 나타냅니다. |
목록을 사용하여 배열을 만들려면 다음 구문을 사용하십시오.
>>> a = numpy.array([1, 2, 3])

다차원 배열 객체를 생성하려면 다음 구문을 사용하십시오.
>>> a = numpy.array([[1, 2, 3], [4, 5, 6]])

배열 요소의 데이터 유형을 변경하려면 컬렉션과 함께 데이터 유형의 이름을 언급하십시오.
>>> a = numpy.array([1, 3, 5, 7], complex)

배열의 크기 찾기
그만큼 나야 함수를 사용하여 배열의 차원을 찾을 수 있습니다.
>>> import numpy as np >>> arr = np.array([[1, 2, 3, 4], [4, 5, 6, 7], [9, 10, 11, 23]]) >>> print(arr.ndim)

각 배열 요소의 크기 찾기
itemsize 함수는 각 배열 항목의 크기를 가져오는 데 사용됩니다. 각 배열 요소가 차지하는 바이트 수를 반환합니다.
다음 예를 고려하십시오.
예
#finding the size of each item in the array import numpy as np a = np.array([[1,2,3]]) print('Each item contains',a.itemsize,'bytes')
산출:
Each item contains 8 bytes.
각 배열 항목의 데이터 유형 찾기
각 배열 항목의 데이터 유형을 확인하려면 dtype 함수를 사용합니다. 배열 항목의 데이터 유형을 확인하려면 다음 예를 고려하십시오.
예
#finding the data type of each array item import numpy as np a = np.array([[1,2,3]]) print('Each item is of the type',a.dtype)
산출:
Each item is of the type int64
배열의 모양과 크기 찾기
배열의 모양과 크기를 얻으려면 numpy 배열과 관련된 크기 및 모양 함수가 사용됩니다.
다음 예를 고려하십시오.
예
import numpy as np a = np.array([[1,2,3,4,5,6,7]]) print('Array Size:',a.size) print('Shape:',a.shape)
산출:
Array Size: 7 Shape: (1, 7)
배열 객체 재구성
배열의 모양은 다차원 배열의 행과 열 수를 의미합니다. 그러나 numpy 모듈은 다차원 배열의 행과 열 수를 변경하여 배열의 모양을 바꾸는 방법을 제공합니다.
ndarray 객체와 관련된 reshape() 함수는 배열의 모양을 변경하는 데 사용됩니다. 새로운 배열 모양의 행과 열을 나타내는 두 개의 매개변수를 허용합니다.
다음 이미지에 주어진 배열의 모양을 바꿔 보겠습니다.

예
import numpy as np a = np.array([[1,2],[3,4],[5,6]]) print('printing the original array..') print(a) a=a.reshape(2,3) print('printing the reshaped array..') print(a)
산출:
printing the original array.. [[1 2] [3 4] [5 6]] printing the reshaped array.. [[1 2 3] [4 5 6]]
배열에서 슬라이싱
NumPy 배열의 슬라이싱은 배열에서 다양한 요소를 추출하는 방법입니다. 배열의 슬라이싱은 Python 목록에서 수행되는 것과 동일한 방식으로 수행됩니다.
배열의 특정 요소를 인쇄하려면 다음 예를 고려하십시오.
예
import numpy as np a = np.array([[1,2],[3,4],[5,6]]) print(a[0,1]) print(a[2,0])
산출:
2 5
위 프로그램은 2를 인쇄합니다. nd 0의 요소 일 인덱스와 0 일 2의 요소 nd 배열의 인덱스입니다.
린스페이스
linspace() 함수는 주어진 간격에 걸쳐 균일한 간격의 값을 반환합니다. 다음 예에서는 지정된 간격 5-15 동안 균등하게 구분된 10개의 값을 반환합니다.
예
import numpy as np a=np.linspace(5,15,10) #prints 10 values which are evenly spaced over the given interval 5-15 print(a)
산출:
[ 5. 6.11111111 7.22222222 8.33333333 9.44444444 10.55555556 11.66666667 12.77777778 13.88888889 15. ]
배열 요소의 최대값, 최소값, 합계 찾기
NumPy는 배열 요소의 최대값, 최소값 및 합계를 찾는 데 사용되는 max(), min() 및 sum() 함수를 제공합니다.
다음 예를 고려하십시오.
예
import numpy as np a = np.array([1,2,3,10,15,4]) print('The array:',a) print('The maximum element:',a.max()) print('The minimum element:',a.min()) print('The sum of the elements:',a.sum())
산출:
The array: [ 1 2 3 10 15 4] The maximum element: 15 The minimum element: 1 The sum of the elements: 35
NumPy 배열 축
NumPy 다차원 배열은 축 0이 열을 나타내고 축 1이 행을 나타내는 축으로 표시됩니다. 행 또는 열 요소 추가와 같은 행 수준 또는 열 수준 계산을 수행하기 위해 축을 언급할 수 있습니다.

각 열 간의 최대 요소, 각 행 간의 최소 요소 및 모든 행 요소의 합을 계산하려면 다음 예를 고려하세요.
예
import numpy as np a = np.array([[1,2,30],[10,15,4]]) print('The array:',a) print('The maximum elements of columns:',a.max(axis = 0)) print('The minimum element of rows',a.min(axis = 1)) print('The sum of all rows',a.sum(axis = 1))
산출:
The array: [[1 2 30] [10 15 4]] The maximum elements of columns: [10 15 30] The minimum element of rows [1 4] The sum of all rows [33 29]
제곱근과 표준편차 구하기
numpy 배열과 관련된 sqrt() 및 std() 함수는 각각 배열 요소의 제곱근과 표준 편차를 찾는 데 사용됩니다.
표준 편차는 배열의 각 요소가 numpy 배열의 평균값과 얼마나 다른지 의미합니다.
다음 예를 고려하십시오.
예
import numpy as np a = np.array([[1,2,30],[10,15,4]]) print(np.sqrt(a)) print(np.std(a))
산출:
[[1. 1.41421356 5.47722558] [3.16227766 3.87298335 2. ]] 10.044346115546242
어레이에 대한 산술 연산
numpy 모듈을 사용하면 다차원 배열에 대한 산술 연산을 직접 수행할 수 있습니다.
다음 예에서는 두 개의 다차원 배열 a와 b에 대해 산술 연산이 수행됩니다.
예
import numpy as np a = np.array([[1,2,30],[10,15,4]]) b = np.array([[1,2,3],[12, 19, 29]]) print('Sum of array a and b ',a+b) print('Product of array a and b ',a*b) print('Division of array a and b ',a/b)
배열 연결
numpy는 두 개의 다차원 배열을 수직 또는 수평으로 연결할 수 있는 수직 스택 및 수평 스택을 제공합니다.
다음 예를 고려하십시오.
예
import numpy as np a = np.array([[1,2,30],[10,15,4]]) b = np.array([[1,2,3],[12, 19, 29]]) print('Arrays vertically concatenated ',np.vstack((a,b))); print('Arrays horizontally concatenated ',np.hstack((a,b)))
산출:
Arrays vertically concatenated [[ 1 2 30] [10 15 4] [ 1 2 3] [12 19 29]] Arrays horizontally concatenated [[ 1 2 30 1 2 3] [10 15 4 12 19 29]]