2025
데이터베이스의 인덱싱 – 세트 1
괴짜를 위한 컴퓨터 공학 포털입니다. 여기에는 잘 쓰여지고, 잘 생각되고, 잘 설명된 컴퓨터 과학 및 프로그래밍 기사, 퀴즈 및 연습/경쟁 프로그래밍/회사 인터뷰 질문이 포함되어 있습니다.
괴짜를 위한 컴퓨터 공학 포털입니다. 여기에는 잘 쓰여지고, 잘 생각되고, 잘 설명된 컴퓨터 과학 및 프로그래밍 기사, 퀴즈 및 연습/경쟁 프로그래밍/회사 인터뷰 질문이 포함되어 있습니다.
괴짜를 위한 컴퓨터 공학 포털입니다. 여기에는 잘 쓰여지고, 잘 생각되고, 잘 설명된 컴퓨터 과학 및 프로그래밍 기사, 퀴즈 및 연습/경쟁 프로그래밍/회사 인터뷰 질문이 포함되어 있습니다.
괴짜를 위한 컴퓨터 공학 포털입니다. 여기에는 잘 쓰여지고, 잘 생각되고, 잘 설명된 컴퓨터 과학 및 프로그래밍 기사, 퀴즈 및 연습/경쟁 프로그래밍/회사 인터뷰 질문이 포함되어 있습니다.
관계형 모델은 E.F. Codd가 데이터를 관계나 테이블 형태로 모델링하기 위해 제안한 것입니다. 관계형 데이터베이스에 데이터가 저장되는 방식을 보여줍니다.

트랜잭션은 데이터를 수정하고 검색할 수 있는 기본 작업입니다. 그러나 데이터베이스의 무결성을 보장하려면 이러한 트랜잭션이 실패/오류가 발생한 경우에도 일관성, 정확성 및 신뢰성을 유지하는 방식으로 실행되는 것이 중요합니다. 여기가 ACID 속성이 작용하는 곳입니다.
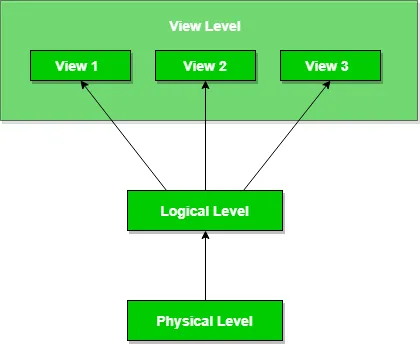
데이터베이스 시스템은 복잡한 데이터 구조로 구성됩니다. 데이터 검색 측면에서 시스템을 효율적으로 만들고 사용자의 유용성 측면에서 복잡성을 줄이기 위해 개발자는 추상화를 사용합니다. 즉, 사용자에게 관련 없는 세부 정보를 숨깁니다. 이 접근 방식은 데이터베이스 설계를 단순화합니다.
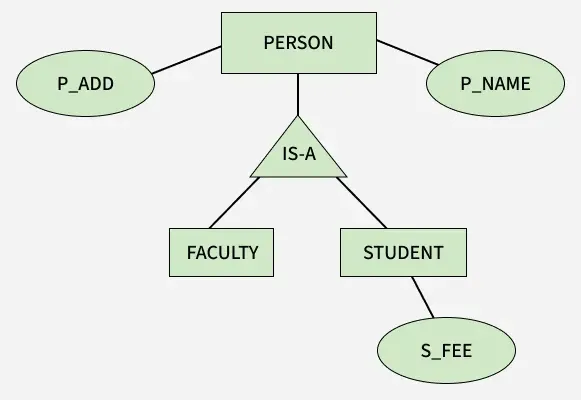
더 큰 데이터를 위해 ER 모델을 사용하면 데이터베이스 모델을 설계할 때 많은 복잡성이 발생하므로 복잡성을 최소화하기 위해 ER 모델에는 일반화, 전문화 및 집계가 도입되었습니다. 이는 데이터 추상화에 사용되었습니다. 추상화 메커니즘을 사용하여 개체 집합의 세부 정보를 숨깁니다.