スタックとヒープのメモリ割り当て
C/C++/Java プログラムのメモリは、スタックまたはヒープに割り当てることができます。
前提条件: Cプログラムのメモリレイアウト 。
スタック割り当て: 割り当てはメモリの連続したブロックで行われます。割り当ては関数呼び出しスタックで行われるため、これをスタック メモリ割り当てと呼びます。割り当てられるメモリのサイズはコンパイラに認識されており、関数が呼び出されるたびに、その変数にはスタック上にメモリが割り当てられます。そして、関数呼び出しが終了するたびに、変数のメモリの割り当てが解除されます。これはすべて、コンパイラの事前定義ルーチンを使用して行われます。プログラマは、メモリの割り当てやスタック変数の割り当て解除について心配する必要はありません。この種類のメモリ割り当ては、メソッドの実行が終了するとすぐに、そのメソッドに属するすべてのデータがスタックから自動的にフラッシュされるため、一時メモリ割り当てとも呼ばれます。これは、メソッドが実行を完了しておらず、現在実行状態にある限り、スタック メモリ スキームに格納されている値にアクセスできることを意味します。
キーポイント:
- これは一時的なメモリ割り当てスキームであり、データ メンバーを含むメソッド( ) が現在実行されている場合にのみデータ メンバーにアクセスできます。
- 対応するメソッドの実行が完了するとすぐに、メモリが自動的に割り当てまたは割り当て解除されます。
- 対応するエラー Java が表示されます。ラング。 スタックオーバーフローエラー による JVM , スタックメモリが完全に埋まってしまった場合。
- スタック メモリの割り当ては、格納されたデータには所有者スレッドのみがアクセスできるため、ヒープ メモリの割り当てと比較して安全であると考えられています。
- メモリの割り当てと割り当て解除は、ヒープ メモリの割り当てと比較して高速です。
- スタック メモリは、ヒープ メモリに比べて記憶領域が少なくなります。
int main() { // All these variables get memory // allocated on stack int a; int b[10]; int n = 20; int c[n]; }
ヒープ割り当て: メモリは、プログラマが作成した命令の実行中に割り当てられます。名前ヒープは、 メモリーリーク プログラム内で起こる可能性があります。
ヒープ メモリの割り当ては、さらに 3 つのカテゴリに分類されます。 これら 3 つのカテゴリは、ヒープ メモリまたはメモリに保存されるデータ (オブジェクト) の優先順位付けに役立ちます。 ガベージコレクション 。
- 若い世代 - これは、スペースを割り当てるためにすべての新しいデータ (オブジェクト) が作成されるメモリの部分であり、このメモリが完全にいっぱいになると、残りのデータがガベージ コレクションに保存されます。
- 古い世代または在職期間のある世代 – これは、頻繁に使用されない、またはまったく使用されていない古いデータ オブジェクトが配置されるヒープ メモリの一部です。
- 永続的な世代 – これは、ランタイム クラスとアプリケーション メソッドの JVM メタデータを含むヒープ メモリの部分です。
キーポイント:
- ヒープ領域が完全にいっぱいの場合は、対応するエラー メッセージが表示されます。 ジャワ。 lang.OutOfMemoryError JVMによる。
- このメモリ割り当てスキームはスタック領域の割り当てとは異なり、ここでは自動割り当て解除機能は提供されません。メモリを効率的に使用するには、ガベージ コレクターを使用して古い未使用のオブジェクトを削除する必要があります。
- このメモリの処理時間(アクセス時間)はスタックメモリに比べてかなり遅くなります。
- また、ヒープ メモリに格納されたデータはすべてのスレッドから見えるため、ヒープ メモリはスタック メモリほどスレッドセーフではありません。
- ヒープ メモリのサイズは、スタック メモリに比べてかなり大きくなります。
- ヒープ メモリは、アプリケーション (または Java プログラム) 全体が実行されている限りアクセス可能であるか、存在します。
int main() { // This memory for 10 integers // is allocated on heap. int *ptr = new int[10]; } Java での両方の種類のメモリ割り当てヒープとスタックの混合例:
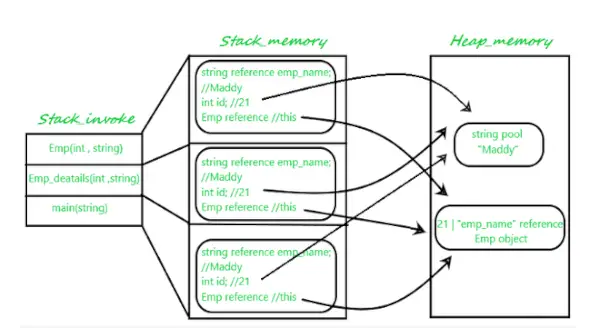
C++ #include using namespace std; int main() { int a = 10; // stored in stack int* p = new int(); // allocate memory in heap *p = 10; delete (p); p = new int[4]; // array in heap allocation delete[] p; p = NULL; // free heap return 0; } ジャワ class Emp { int id; String emp_name; public Emp(int id, String emp_name) { this.id = id; this.emp_name = emp_name; } } public class Emp_detail { private static Emp Emp_detail(int id, String emp_name) { return new Emp(id, emp_name); } public static void main(String[] args) { int id = 21; String name = 'Maddy'; Emp person_ = null; person_ = Emp_detail(id, name); } } パイソン def main(): a = 10 # stored in stack p = None # declaring p variable p = 10 # allocating memory in heap del p # deleting memory allocation in heap p = [None] * 4 # array in heap allocation p = None # free heap return 0 if __name__ == '__main__': main()
JavaScript // Define the Emp class with id and emp_name properties class Emp { constructor(id, emp_name) { this.id = id; // Initialize id this.emp_name = emp_name; // Initialize emp_name } } // Create an instance of the Emp class const person = new Emp(21, 'Maddy'); // Initialize person with id 21 and emp_name 'Maddy' console.log(person); // Output the person object to the console 上記の例を分析した後に得られる結論は次のとおりです。
- have プログラムの実行を開始すると、すべてのランタイム クラスがヒープ メモリ空間に格納されます。
- 次に、次の行で main() メソッドを見つけます。これはすべてのプリミティブ (またはローカル) とともにスタックに保存されており、Emp_detail 型の参照変数 Emp もスタックに保存され、対応するオブジェクトを指します。ヒープメモリに保存されます。
- 次に、次の行では main() からパラメーター化されたコンストラクター Emp(int, String) を呼び出し、同じスタック メモリ ブロックの先頭に割り当てます。これにより以下が保存されます:
- スタック メモリの呼び出されたオブジェクトのオブジェクト参照。
- プリミティブ値( String emp_name 引数の参照変数は、文字列プールからヒープ メモリにある実際の文字列を指します。
- 次に、メイン メソッドは再び Emp_detail() 静的メソッドを呼び出します。このメソッドの割り当ては、前のメモリ ブロックの上にあるスタック メモリ ブロックに行われます。
- String emp_name 引数の参照変数は、文字列プールからヒープ メモリにある実際の文字列を指します。
String emp_name 引数の参照変数は、文字列プールからヒープ メモリにある実際の文字列を指します。

図1
スタック割り当てとヒープ割り当ての主な違い
- スタックでは、割り当てと割り当て解除はコンパイラによって自動的に行われますが、ヒープではプログラマが手動で行う必要があります。
- ヒープ フレームの処理は、スタック フレームの処理よりもコストがかかります。
- メモリ不足の問題はスタックで発生する可能性が高く、ヒープ メモリの主な問題は断片化です。
- スタック フレームのアクセスは、スタックのメモリ領域が小さくキャッシュに適しているため、ヒープ フレームよりも簡単ですが、ヒープ フレームの場合はメモリ全体に分散されるため、より多くのキャッシュ ミスが発生します。
- スタックは柔軟性がなく、割り当てられたメモリ サイズは変更できませんが、ヒープは柔軟性があり、割り当てられたメモリ サイズは変更できます。
- ヒープへのアクセスにはスタック以上の時間がかかります。
比較表
| パラメータ | スタック | ヒープ |
|---|---|---|
| 基本 | メモリは連続したブロックに割り当てられます。 | メモリはランダムな順序で割り当てられます。 |
| 割り当てと割り当て解除 | コンパイラ命令により自動化されます。 | プログラマーによるマニュアル。 |
| 料金 | 少ない | もっと |
| 実装 | 簡単 | 難しい |
| アクセス時間 | もっと早く | もっとゆっくり |
| 主な問題点 | メモリ不足 | メモリの断片化 |
| 参照の場所 | 素晴らしい | 十分な |
| 安全性 | スレッドセーフ、保存されたデータには所有者のみがアクセス可能 | スレッドセーフではありません。保存されたデータはすべてのスレッドに表示されます |
| 柔軟性 | 固定サイズ | サイズ変更可能です |
| データ型構造 | 線形 | 階層的 |
| 好ましい | 配列では静的なメモリ割り当てが推奨されます。 | リンク リストではヒープ メモリの割り当てが優先されます。 |
| サイズ | ヒープメモリより小さい。 | スタックメモリよりも大きい。 |