LRU キャッシュの実装に関する完全なチュートリアル
LRUキャッシュとは何ですか?
キャッシュ置換アルゴリズムは、スペースがいっぱいになったときにキャッシュを置換するように効率的に設計されています。の 最も最近使用されていない (LRU) はそれらのアルゴリズムの 1 つです。その名のとおり、キャッシュメモリがいっぱいになると、 LRU 最も最近使用されていないデータを選択し、新しいデータ用のスペースを確保するためにそれを削除します。キャッシュ内のデータの優先度は、そのデータの必要性に応じて変化します。つまり、一部のデータが最近フェッチまたは更新された場合、そのデータの優先度は変更されて最高の優先度に割り当てられ、データの優先度が低下した場合、データの優先度は下がります。操作後も未使用の操作が残ります。
目次
- LRUキャッシュとは何ですか?
- LRU キャッシュの操作:
- LRU キャッシュの働き:
- LRU キャッシュを実装する方法:
- キューとハッシュを使用した LRU キャッシュの実装:
- 二重リンクリストとハッシュを使用した LRU キャッシュの実装:
- Deque と Hashmap を使用した LRU キャッシュの実装:
- スタックとハッシュマップを使用した LRU キャッシュの実装:
- カウンタ実装を使用した LRU キャッシュ:
- Lazy Updates を使用した LRU キャッシュの実装:
- LRU キャッシュの複雑さの分析:
- LRU キャッシュの利点:
- LRU キャッシュの欠点:
- LRU キャッシュの実世界への応用:
LRU アルゴリズムは標準的な問題であり、オペレーティング システムなどの必要に応じて変更される場合があります。 LRU ページフォールトを最小限に抑えるためのページ置換アルゴリズムとして使用できるため、重要な役割を果たします。
LRU キャッシュの操作:
- LRUCache (容量 c): 正のサイズの容量で LRU キャッシュを初期化する c.
- (キー) を取得します : キーの値を返します ' k’ キャッシュに存在する場合は、それ以外の場合は -1 を返します。また、LRU キャッシュ内のデータの優先順位も更新します。
- put (キー、値): キーが存在する場合はキーの値を更新し、存在しない場合はキーと値のペアをキャッシュに追加します。キーの数が LRU キャッシュの容量を超えた場合は、最も最近使用されていないキーを破棄します。
LRU キャッシュの働き:
容量 3 の LRU キャッシュがあり、次の操作を実行するとします。
- (キー=1、値=A)をキャッシュに入れる
- (key=2, value=B)をキャッシュに入れる
- (キー=3、値=C)をキャッシュに入れる
- キャッシュから (key=2) を取得します
- キャッシュから (key=4) を取得します
- (キー=4、値=D)をキャッシュに入れる
- (key=3, value=E)をキャッシュに入れる
- キャッシュから (key=4) を取得します
- (キー=1、値=A)をキャッシュに入れる
以下の図に示すように、上記の操作が次々に実行されます。

各操作の詳細な説明:
- Put (キー 1、値 A) : LRU キャッシュには空き容量 = 3 があるため、置き換える必要はなく、{1 : A} を先頭に置きます。つまり、{1 : A} が最も高い優先度になります。
- Put (キー 2、値 B) : LRU キャッシュの空き容量 = 2 があるため、やはり置換の必要はありませんが、{2 : B} の優先順位が最も高く、{1 : A} の優先順位が下がります。
- Put (キー 3、値 C) : キャッシュにはまだ 1 つの空きスペースがあるため、置換せずに {3 : C} を配置します。キャッシュがいっぱいになり、現在の優先順位が最高から最低まで {3:C}、{2:B であることに注意してください。 }、{1:A}。
- 取得(キー2) : この操作中に key=2 の値が返されます。これも key=2 が使用されているため、新しい優先順位は {2:B}、{3:C}、{1:A} になります。
- 取得 (キー 4): キー 4 がキャッシュに存在しないことを確認します。この操作では「-1」を返します。
- Put (キー 4、値 D) : キャッシュがいっぱいであることを確認し、LRU アルゴリズムを使用して、最も最近使用されていないキーを特定します。 {1:A} の優先度が最も低いため、キャッシュから {1:A} を削除し、{4:D} をキャッシュに置きます。新しい優先順位は {4:D}、{2:B}、{3:C} であることに注意してください。
- Put (キー 3、値 E) : key=3 は value=C を持つキャッシュにすでに存在しているため、この操作ではキーは削除されず、key=3 の値が ' に更新されます。 そして' 。これで、新しい優先順位は {3:E}、{4:D}、{2:B} になります。
- 取得(キー4) : key=4の値を返します。これで、新しい優先度は {4:D}、{3:E}、{2:B} になります。
- Put (キー 1、値 A) : キャッシュがいっぱいであるため、LRU アルゴリズムを使用して、最も最近使用されたキーを特定します。また、{2:B} の優先度が最も低いため、キャッシュから {2:B} を削除し、{1:A} をキャッシュ。現在、新しい優先順位は {1:A}、{4:D}、{3:E} です。
LRU キャッシュを実装する方法:
LRU キャッシュはさまざまな方法で実装でき、プログラマごとに異なるアプローチを選択する場合があります。ただし、一般的に使用されるアプローチは次のとおりです。
- キューとハッシュを使用した LRU
- LRUを使用する 二重リンクリスト + ハッシュ
- Deque を使用した LRU
- スタックを使用した LRU
- LRUを使用する カウンターの実装
- 遅延更新を使用した LRU
キューとハッシュを使用した LRU キャッシュの実装:
LRU キャッシュを実装するために 2 つのデータ構造を使用します。
- 列 二重リンクリストを使用して実装されます。キューの最大サイズは、使用可能なフレームの総数 (キャッシュ サイズ) と等しくなります。最近使用されたページはフロントエンド近くにあり、最も最近使用されていないページはリアエンド近くになります。
- ハッシュ ページ番号をキーとして、対応するキュー ノードのアドレスを値として使用します。
ページが参照される場合、必要なページがメモリ内に存在する可能性があります。メモリ内にある場合は、リストのノードを切り離してキューの先頭に置く必要があります。
必要なページがメモリ内にない場合は、それをメモリ内に取り込みます。簡単に言うと、新しいノードをキューの先頭に追加し、ハッシュ内の対応するノード アドレスを更新します。キューがいっぱいの場合、つまりすべてのフレームがいっぱいの場合は、キューの後ろからノードを削除し、新しいノードをキューの先頭に追加します。
図:
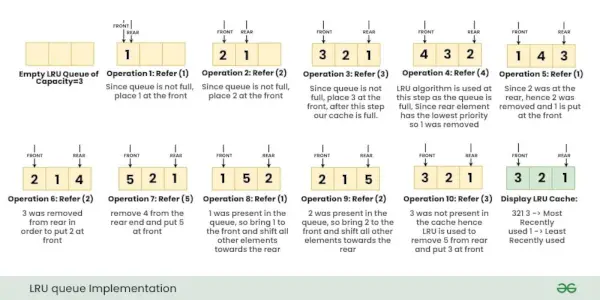
操作を考えてみましょう。 参照 鍵 バツ LRU キャッシュ内の値: { 1, 2, 3, 4, 1, 2, 5, 1, 2, 3 }
注記: 最初はメモリ内にページがありません。以下の画像は、LRU キャッシュに対する上記の操作の実行を段階的に示しています。

アルゴリズム:
- int型のリスト、つまり型の順序付けされていないマップを宣言してクラスLRUCacheを作成します。
- LRUCacheのrefer関数内
- この値がキューに存在しない場合は、この値をキューの前にプッシュし、キューがいっぱいの場合は最後の値を削除します。
- 値がすでに存在する場合は、それをキューから削除し、キューの先頭にプッシュします。
- 表示関数 print では、キューを先頭から使用する LRUCache
上記のアプローチの実装を以下に示します。
C++
// We can use stl container list as a double> // ended queue to store the cache keys, with> // the descending time of reference from front> // to back and a set container to check presence> // of a key. But to fetch the address of the key> // in the list using find(), it takes O(N) time.> // This can be optimized by storing a reference> // (iterator) to each key in a hash map.> #include> using> namespace> std;> > class> LRUCache {> > // store keys of cache> > list <> int> >dq;>> > > // store references of key in cache> > unordered_map <> int> , list <> int> >::イテレータ> ま;>> > int> csize;> // maximum capacity of cache> > public> :> > LRUCache(> int> );> > void> refer(> int> );> > void> display();> };> > // Declare the size> LRUCache::LRUCache(> int> n) { csize = n; }> > // Refers key x with in the LRU cache> void> LRUCache::refer(> int> x)> {> > // not present in cache> > if> (ma.find(x) == ma.end()) {> > // cache is full> > if> (dq.size() == csize) {> > // delete least recently used element> > int> last = dq.back();> > > // Pops the last element> > dq.pop_back();> > > // Erase the last> > ma.erase(last);> > }> > }> > > // present in cache> > else> > dq.erase(ma[x]);> > > // update reference> > dq.push_front(x);> > ma[x] = dq.begin();> }> > // Function to display contents of cache> void> LRUCache::display()> {> > > // Iterate in the deque and print> > // all the elements in it> > for> (> auto> it = dq.begin(); it != dq.end(); it++)> > cout < < (*it) < <> ' '> ;> > > cout < < endl;> }> > // Driver Code> int> main()> {> > LRUCache ca(4);> > > ca.refer(1);> > ca.refer(2);> > ca.refer(3);> > ca.refer(1);> > ca.refer(4);> > ca.refer(5);> > ca.display();> > > return> 0;> }> // This code is contributed by Satish Srinivas> |
C
// A C program to show implementation of LRU cache> #include> #include> > // A Queue Node (Queue is implemented using Doubly Linked> // List)> typedef> struct> QNode {> > struct> QNode *prev, *next;> > unsigned> > pageNumber;> // the page number stored in this QNode> } QNode;> > // A Queue (A FIFO collection of Queue Nodes)> typedef> struct> Queue {> > unsigned count;> // Number of filled frames> > unsigned numberOfFrames;> // total number of frames> > QNode *front, *rear;> } Queue;> > // A hash (Collection of pointers to Queue Nodes)> typedef> struct> Hash {> > int> capacity;> // how many pages can be there> > QNode** array;> // an array of queue nodes> } Hash;> > // A utility function to create a new Queue Node. The queue> // Node will store the given 'pageNumber'> QNode* newQNode(unsigned pageNumber)> {> > // Allocate memory and assign 'pageNumber'> > QNode* temp = (QNode*)> malloc> (> sizeof> (QNode));> > temp->ページ番号 = ページ番号;>> > > // Initialize prev and next as NULL> > temp->前 = 一時->次 = NULL;>> > > return> temp;> }> > // A utility function to create an empty Queue.> // The queue can have at most 'numberOfFrames' nodes> Queue* createQueue(> int> numberOfFrames)> {> > Queue* queue = (Queue*)> malloc> (> sizeof> (Queue));> > > // The queue is empty> > queue->カウント = 0;>> > queue->フロント = キュー -> リア = NULL;>> > > // Number of frames that can be stored in memory> > queue->フレーム数 = フレーム数;>> > > return> queue;> }> > // A utility function to create an empty Hash of given> // capacity> Hash* createHash(> int> capacity)> {> > // Allocate memory for hash> > Hash* hash = (Hash*)> malloc> (> sizeof> (Hash));> > hash->容量 = 容量;>> > > // Create an array of pointers for referring queue nodes> > hash->配列>>' queue->後->次 = NULL;>> > > free> (temp);> > > // decrement the number of full frames by 1> > queue->カウント - ;>> }> > // A function to add a page with given 'pageNumber' to both> // queue and hash> void> Enqueue(Queue* queue, Hash* hash, unsigned pageNumber)> {> > // If all frames are full, remove the page at the rear> > if> (AreAllFramesFull(queue)) {> > // remove page from hash> > hash->配列[キュー->リア->ページ番号] = NULL;>> > deQueue(queue);> > }> > > // Create a new node with given page number,> > // And add the new node to the front of queue> > QNode* temp = newQNode(pageNumber);> > temp->次 = キュー -> フロント;>> > > // If queue is empty, change both front and rear> > // pointers> > if> (isQueueEmpty(queue))> > queue->リア = キュー -> フロント = 温度;>> > else> // Else change the front> > {> > queue->前->前 = 温度;>> > queue->フロント = 温度;>> > }> > > // Add page entry to hash also> > hash->配列[ページ番号] = 一時;>> > > // increment number of full frames> > queue->カウント++;>> }> > // This function is called when a page with given> // 'pageNumber' is referenced from cache (or memory). There> // are two cases:> // 1. Frame is not there in memory, we bring it in memory> // and add to the front of queue> // 2. Frame is there in memory, we move the frame to front> // of queue> void> ReferencePage(Queue* queue, Hash* hash,> > unsigned pageNumber)> {> > QNode* reqPage = hash->配列[ページ番号];>> > > // the page is not in cache, bring it> > if> (reqPage == NULL)> > Enqueue(queue, hash, pageNumber);> > > // page is there and not at front, change pointer> > else> if> (reqPage != queue->前){>> reqPage->次->前 = reqページ->前;>> > > // If the requested page is rear, then change rear> > // as this node will be moved to front> > if> (reqPage == queue->後部){>> , q->フロント->ページ番号);>> > printf> (> '%d '> , q->前->次->ページ番号);>> > printf> (> '%d '> , q->前->次->次->ページ番号);>> > printf> (> '%d '> , q->フロント->次->次->次->ページ番号);>> > > return> 0;> }> |
ジャワ
/* We can use Java inbuilt Deque as a double> > ended queue to store the cache keys, with> > the descending time of reference from front> > to back and a set container to check presence> > of a key. But remove a key from the Deque using> > remove(), it takes O(N) time. This can be> > optimized by storing a reference (iterator) to> > each key in a hash map. */> import> java.util.Deque;> import> java.util.HashSet;> import> java.util.Iterator;> import> java.util.LinkedList;> > public> class> LRUCache {> > > // store keys of cache> > private> Deque doublyQueue;> > > // store references of key in cache> > private> HashSet hashSet;> > > // maximum capacity of cache> > private> final> int> CACHE_SIZE;> > > LRUCache(> int> capacity)> > {> > doublyQueue => new> LinkedList();> > hashSet => new> HashSet();> > CACHE_SIZE = capacity;> > }> > > /* Refer the page within the LRU cache */> > public> void> refer(> int> page)> > {> > if> (!hashSet.contains(page)) {> > if> (doublyQueue.size() == CACHE_SIZE) {> > int> last = doublyQueue.removeLast();> > hashSet.remove(last);> > }> > }> > else> {> /* The found page may not be always the last> > element, even if it's an intermediate> > element that needs to be removed and added> > to the start of the Queue */> > doublyQueue.remove(page);> > }> > doublyQueue.push(page);> > hashSet.add(page);> > }> > > // display contents of cache> > public> void> display()> > {> > Iterator itr = doublyQueue.iterator();> > while> (itr.hasNext()) {> > System.out.print(itr.next() +> ' '> );> > }> > }> > > // Driver code> > public> static> void> main(String[] args)> > {> > LRUCache cache => new> LRUCache(> 4> );> > cache.refer(> 1> );> > cache.refer(> 2> );> > cache.refer(> 3> );> > cache.refer(> 1> );> > cache.refer(> 4> );> > cache.refer(> 5> );> > cache.display();> > }> }> // This code is contributed by Niraj Kumar> |
Python3
# We can use stl container list as a double> # ended queue to store the cache keys, with> # the descending time of reference from front> # to back and a set container to check presence> # of a key. But to fetch the address of the key> # in the list using find(), it takes O(N) time.> # This can be optimized by storing a reference> # (iterator) to each key in a hash map.> class> LRUCache:> > # store keys of cache> > def> __init__(> self> , n):> > self> .csize> => n> > self> .dq> => []> > self> .ma> => {}> > > > # Refers key x with in the LRU cache> > def> refer(> self> , x):> > > # not present in cache> > if> x> not> in> self> .ma.keys():> > # cache is full> > if> len> (> self> .dq)> => => self> .csize:> > # delete least recently used element> > last> => self> .dq[> -> 1> ]> > > # Pops the last element> > ele> => self> .dq.pop();> > > # Erase the last> > del> self> .ma[last]> > > # present in cache> > else> :> > del> self> .dq[> self> .ma[x]]> > > # update reference> > self> .dq.insert(> 0> , x)> > self> .ma[x]> => 0> ;> > > # Function to display contents of cache> > def> display(> self> ):> > > # Iterate in the deque and print> > # all the elements in it> > print> (> self> .dq)> > # Driver Code> ca> => LRUCache(> 4> )> > ca.refer(> 1> )> ca.refer(> 2> )> ca.refer(> 3> )> ca.refer(> 1> )> ca.refer(> 4> )> ca.refer(> 5> )> ca.display()> # This code is contributed by Satish Srinivas> |
C#
// C# program to implement the approach> > using> System;> using> System.Collections.Generic;> > class> LRUCache {> > // store keys of cache> > private> List <> int> >ダブルキュー;>> > > // store references of key in cache> > private> HashSet <> int> >ハッシュセット;>> > > // maximum capacity of cache> > private> int> CACHE_SIZE;> > > public> LRUCache(> int> capacity)> > {> > doublyQueue => new> List <> int> >();>> > hashSet => new> HashSet <> int> >();>> > CACHE_SIZE = capacity;> > }> > > /* Refer the page within the LRU cache */> > public> void> Refer(> int> page)> > {> > if> (!hashSet.Contains(page)) {> > if> (doublyQueue.Count == CACHE_SIZE) {> > int> last> > = doublyQueue[doublyQueue.Count - 1];> > doublyQueue.RemoveAt(doublyQueue.Count - 1);> > hashSet.Remove(last);> > }> > }> > else> {> > /* The found page may not be always the last> > element, even if it's an intermediate> > element that needs to be removed and added> > to the start of the Queue */> > doublyQueue.Remove(page);> > }> > doublyQueue.Insert(0, page);> > hashSet.Add(page);> > }> > > // display contents of cache> > public> void> Display()> > {> > foreach> (> int> page> in> doublyQueue)> > {> > Console.Write(page +> ' '> );> > }> > }> > > // Driver code> > static> void> Main(> string> [] args)> > {> > LRUCache cache => new> LRUCache(4);> > cache.Refer(1);> > cache.Refer(2);> > cache.Refer(3);> > cache.Refer(1);> > cache.Refer(4);> > cache.Refer(5);> > cache.Display();> > }> }> > // This code is contributed by phasing17> |
JavaScript
// JS code to implement the approach> class LRUCache {> > constructor(n) {> > this> .csize = n;> > this> .dq = [];> > this> .ma => new> Map();> > }> > > refer(x) {> > if> (!> this> .ma.has(x)) {> > if> (> this> .dq.length ===> this> .csize) {> > const last => this> .dq[> this> .dq.length - 1];> > this> .dq.pop();> > this> .ma.> delete> (last);> > }> > }> else> {> > this> .dq.splice(> this> .dq.indexOf(x), 1);> > }> > > this> .dq.unshift(x);> > this> .ma.set(x, 0);> > }> > > display() {> > console.log(> this> .dq);> > }> }> > const cache => new> LRUCache(4);> > cache.refer(1);> cache.refer(2);> cache.refer(3);> cache.refer(1);> cache.refer(4);> cache.refer(5);> cache.display();> > // This code is contributed by phasing17> |
二重リンクリストとハッシュを使用した LRU キャッシュの実装 :
このアイデアは非常に基本的なもので、要素を先頭に挿入し続けます。
- 要素がリストに存在しない場合は、リストの先頭に追加します。
- 要素がリストに存在する場合は、その要素を先頭に移動し、リストの残りの要素を移動します。
ノードの優先順位はヘッドからのそのノードの距離に依存し、ノードがヘッドに近いほど優先順位が高くなります。したがって、キャッシュ サイズがいっぱいで要素を削除する必要がある場合は、二重リンク リストの末尾に隣接する要素を削除します。
Deque と Hashmap を使用した LRU キャッシュの実装:
Deque データ構造では、前方および末尾からの挿入と削除が可能です。このプロパティにより、フロント要素が優先度の高い要素を表すことができる一方で、末尾の要素が優先度の低い要素、つまり最も最近使用されていない要素になる可能性があるため、LRU の実装が可能になります。
働く:
- 取得操作 : キーがキャッシュのハッシュ マップに存在するかどうかを確認し、両端キューで以下のケースに従います。
- キーが見つかった場合:
- このアイテムは最近使用されたものとみなされ、デクの先頭に移動されます。
- キーに関連付けられた値が、
get>手術。- キーが見つからない場合:
- そのようなキーが存在しないことを示すには -1 を返します。
- プット操作: まず、キャッシュのハッシュ マップにキーが既に存在するかどうかを確認し、両端キューで以下のケースに従います。
- キーが存在する場合:
- キーに関連付けられた値が更新されます。
- アイテムは最近使用されたものであるため、両端キューの先頭に移動されます。
- キーが存在しない場合:
- キャッシュがいっぱいの場合は、新しい項目を挿入する必要があり、最も最近使用されていない項目を削除する必要があることを意味します。これは、両端キューの末尾から項目を削除し、ハッシュ マップから対応するエントリを削除することによって行われます。
- 次に、新しいキーと値のペアがハッシュ マップと両端キューの先頭の両方に挿入され、それが最後に使用されたアイテムであることを示します。
スタックとハッシュマップを使用した LRU キャッシュの実装:
単純なスタックでは最も最近使用されていない項目への効率的なアクセスが提供されないため、スタック データ構造とハッシュを使用して LRU (最も最近使用されていない) キャッシュを実装するのは少し難しい場合があります。ただし、スタックとハッシュ マップを組み合わせてこれを効率的に実現できます。これを実装するための高レベルのアプローチは次のとおりです。
- ハッシュマップを使用する : ハッシュ マップには、キャッシュのキーと値のペアが保存されます。キーはスタック内の対応するノードにマップされます。
- スタックを使用する : スタックは、キーの使用状況に基づいてキーの順序を維持します。最も最近使用されていないアイテムがスタックの一番下にあり、最も最近に使用されたアイテムが一番上にあります。
このアプローチはそれほど効率的ではないため、あまり使用されません。
カウンタ実装を使用した LRU キャッシュ:
キャッシュ内の各ブロックには、カウンターの値が属する独自の LRU カウンターがあります。 {0 から n-1} 、 ここ ' n ' はキャッシュのサイズを表します。ブロック置換時に変更されたブロックは MRU ブロックとなり、そのカウンタ値は n – 1 に変更されます。アクセスされたブロックのカウンタ値より大きいカウンタ値は 1 減算されます。残りのブロックは変更されません。
| コンターの価値 | 優先度 | 使用状況 |
|---|---|---|
| 0 | 低い | 最も最近使用されていない |
| n-1 | 高い | 最近使用したもの |
Lazy Updates を使用した LRU キャッシュの実装:
遅延更新を使用して LRU (最も最近使用されていない) キャッシュを実装することは、キャッシュの操作の効率を向上させる一般的な手法です。遅延更新には、データ構造全体をすぐに更新せずに、項目がアクセスされる順序を追跡することが含まれます。キャッシュミスが発生した場合、いくつかの基準に基づいて完全な更新を実行するかどうかを決定できます。
LRU キャッシュの複雑さの分析:
- 時間計算量:
- Put() 操作: O(1) つまり、新しいキーと値のペアの挿入または更新に必要な時間は一定です
- Get() 操作: O(1) つまり、キーの値を取得するのに必要な時間は一定です
- 補助スペース: O(N) ここで、N はキャッシュの容量です。
LRU キャッシュの利点:
- 高速アクセス : LRU キャッシュのデータにアクセスするのに O(1) 時間がかかります。
- 高速アップデート : LRU キャッシュ内のキーと値のペアを更新するには O(1) 時間がかかります。
- 最も最近使用されていないデータの迅速な削除 : 最近使用されていないものを削除するには O(1) かかります。
- スラッシングなし: LRU はページの使用履歴を考慮するため、FIFO に比べてスラッシングの影響を受けにくいです。頻繁に使用されているページを検出し、それらのページに優先順位を付けてメモリを割り当てることができるため、ページ フォールトとディスク I/O 操作の数が削減されます。
LRU キャッシュの欠点:
- 効率を上げるには大きなキャッシュ サイズが必要です。
- 追加のデータ構造を実装する必要があります。
- ハードウェア支援は高いです。
- LRU では、他のアルゴリズムに比べてエラー検出が困難です。
- それは受け入れられる範囲が限られています。
LRU キャッシュの実世界への応用:
- データベース システムでは、高速なクエリ結果が得られます。
- オペレーティング システムでは、ページ フォールトを最小限に抑えます。
- 頻繁に使用されるファイルやコード スニペットを保存するためのテキスト エディターと IDE
- ネットワーク ルーターとスイッチは LRU を使用してコンピュータ ネットワークの効率を向上させます
- コンパイラの最適化において
- テキスト予測およびオートコンプリート ツール












![軍事力別世界最強国トップ10 [2023]](https://techcodeview.com/img/current-gk/40/top-10-most-powerful-country-world-military-strength.webp)