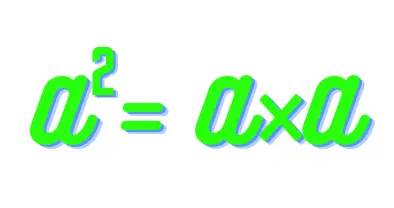ניתוח XML ב- Python

מאמר זה מתמקד כיצד ניתן לנתח קובץ XML נתון ולחלץ ממנו כמה נתונים שימושיים בצורה מובנית. XML: XML ראשי תיבות של eXtensible Markup Language. הוא תוכנן לאחסן ולהעביר נתונים. הוא תוכנן כך שיהיה קריא גם לאדם וגם למכונה. לכן מטרות העיצוב של XML מדגישות פשטות כלליות ושימושיות ברחבי האינטרנט. קובץ ה-XML שיש לנתח במדריך זה הוא למעשה הזנת RSS. RSS: RSS (סיכום אתר עשיר שנקרא לעתים קרובות Really Simple Syndication) משתמש במשפחה של פורמטים סטנדרטיים של הזנת אינטרנט כדי לפרסם מידע מתעדכן לעתים קרובות כמו רשומות בלוג חדשות כותרות וידאו וידאו. RSS הוא טקסט רגיל בפורמט XML.
- פורמט ה-RSS עצמו קל יחסית לקריאה הן על ידי תהליכים אוטומטיים והן על ידי בני אדם כאחד.
- ה-RSS המעובד במדריך זה הוא הזנת RSS של כתבות חדשות מובילות מאתר חדשות פופולרי. אתה יכול לבדוק את זה כָּאן . המטרה שלנו היא לעבד את הזנת ה-RSS (או קובץ ה-XML) הזה ולשמור אותו בפורמט אחר לשימוש עתידי.
#Python code to illustrate parsing of XML files # importing the required modules import csv import requests import xml.etree.ElementTree as ET def loadRSS (): # url of rss feed url = 'http://www.hindustantimes.com/rss/topnews/rssfeed.xml' # creating HTTP response object from given url resp = requests . get ( url ) # saving the xml file with open ( 'topnewsfeed.xml' 'wb' ) as f : f . write ( resp . content ) def parseXML ( xmlfile ): # create element tree object tree = ET . parse ( xmlfile ) # get root element root = tree . getroot () # create empty list for news items newsitems = [] # iterate news items for item in root . findall ( './channel/item' ): # empty news dictionary news = {} # iterate child elements of item for child in item : # special checking for namespace object content:media if child . tag == '{https://video.search.yahoo.com/mrss' : news [ 'media' ] = child . attrib [ 'url' ] else : news [ child . tag ] = child . text . encode ( 'utf8' ) # append news dictionary to news items list newsitems . append ( news ) # return news items list return newsitems def savetoCSV ( newsitems filename ): # specifying the fields for csv file fields = [ 'guid' 'title' 'pubDate' 'description' 'link' 'media' ] # writing to csv file with open ( filename 'w' ) as csvfile : # creating a csv dict writer object writer = csv . DictWriter ( csvfile fieldnames = fields ) # writing headers (field names) writer . writeheader () # writing data rows writer . writerows ( newsitems ) def main (): # load rss from web to update existing xml file loadRSS () # parse xml file newsitems = parseXML ( 'topnewsfeed.xml' ) # store news items in a csv file savetoCSV ( newsitems 'topnews.csv' ) if __name__ == '__main__' : # calling main function main ()
Above code will: - טען הזנת RSS מכתובת האתר שצוינה ושמור אותה כקובץ XML.
- נתח את קובץ ה-XML כדי לשמור חדשות כרשימה של מילונים כאשר כל מילון הוא פריט חדשות בודד.
- שמור את החדשות בקובץ CSV.
- אתה יכול להסתכל על עדכוני rss נוספים של אתר החדשות המשמש בדוגמה לעיל. אתה יכול לנסות ליצור גרסה מורחבת של הדוגמה לעיל על ידי ניתוח עדכוני rss אחרים מדי.
- האם אתה חובב קריקט? אָז זֶה הזנת rss חייבת לעניין אותך! אתה יכול לנתח את קובץ ה-XML הזה כדי לגרד מידע על משחקי הקריקט החיים ולהשתמש בו כדי להודיע על שולחן העבודה!
def loadRSS(): # url of rss feed url = 'http://www.hindustantimes.com/rss/topnews/rssfeed.xml' # creating HTTP response object from given url resp = requests.get(url) # saving the xml file with open('topnewsfeed.xml' 'wb') as f: f.write(resp.content) Here we first created a HTTP response object by sending an HTTP request to the URL of the RSS feed. The content of response now contains the XML file data which we save as topnewsfeed.xml במדריך המקומי שלנו. למידע נוסף על אופן פעולת מודול הבקשות, עקוב אחר מאמר זה: GET ו-POST בקשות באמצעות Python  כאן אנחנו משתמשים xml.etree.ElementTree (קוראים לזה בקיצור ET) מודול. ל-Element Tree יש שני מחלקות למטרה זו - ElementTree מייצג את כל מסמך ה-XML כעץ ו אֵלֵמֶנט מייצג צומת בודד בעץ זה. אינטראקציות עם המסמך כולו (קריאה וכתיבה אל/מקבצים) נעשות בדרך כלל על ElementTree רָמָה. אינטראקציות עם אלמנט XML בודד ורכיבי המשנה שלו נעשים ב- אֵלֵמֶנט רָמָה. אוקיי אז בוא נעבור על parseXML() function now:
כאן אנחנו משתמשים xml.etree.ElementTree (קוראים לזה בקיצור ET) מודול. ל-Element Tree יש שני מחלקות למטרה זו - ElementTree מייצג את כל מסמך ה-XML כעץ ו אֵלֵמֶנט מייצג צומת בודד בעץ זה. אינטראקציות עם המסמך כולו (קריאה וכתיבה אל/מקבצים) נעשות בדרך כלל על ElementTree רָמָה. אינטראקציות עם אלמנט XML בודד ורכיבי המשנה שלו נעשים ב- אֵלֵמֶנט רָמָה. אוקיי אז בוא נעבור על parseXML() function now: tree = ET.parse(xmlfile)Here we create an ElementTree אובייקט על ידי ניתוח המעבר קובץ xml.
root = tree.getroot()getrooted() הפונקציה מחזירה את השורש של עֵץ בתור אֵלֵמֶנט object.
for item in root.findall('./channel/item'): Now once you have taken a look at the structure of your XML file you will notice that we are interested only in פָּרִיט אֵלֵמֶנט. ./ערוץ/פריט הוא למעשה XPath תחביר (XPath היא שפה לטיפול בחלקים ממסמך XML). כאן אנחנו רוצים למצוא הכל פָּרִיט הנכדים של עָרוּץ ילדי ה שׁוֹרֶשׁ (מסומן ב-'.') אלמנט. אתה יכול לקרוא עוד על תחביר XPath נתמך כָּאן . for item in root.findall('./channel/item'): # empty news dictionary news = {} # iterate child elements of item for child in item: # special checking for namespace object content:media if child.tag == '{https://video.search.yahoo.com/mrss': news['media'] = child.attrib['url'] else: news[child.tag] = child.text.encode('utf8') # append news dictionary to news items list newsitems.append(news) Now we know that we are iterating through פָּרִיט אלמנטים שבהם כל אחד פָּרִיט אלמנט מכיל ידיעה אחת. אז אנחנו יוצרים ריק חֲדָשׁוֹת dictionary in which we will store all data available about news item. To iterate though each child element of an element we simply iterate through it like this: for child in item:Now notice a sample item element here:
 We will have to handle namespace tags separately as they get expanded to their original value when parsed. So we do something like this:
We will have to handle namespace tags separately as they get expanded to their original value when parsed. So we do something like this: if child.tag == '{https://video.search.yahoo.com/mrss': news['media'] = child.attrib['url'] child.attrib הוא מילון של כל התכונות הקשורות לאלמנט. כאן אנחנו מתעניינים כתובת אתר תכונה של מדיה:תוכן namespace tag. Now for all other children we simply do: news[child.tag] = child.text.encode('utf8') child.tag מכיל את השם של אלמנט הבן. ילד.טקסט stores all the text inside that child element. So finally a sample item element is converted to a dictionary and looks like this: {'description': 'Ignis has a tough competition already from Hyun.... 'guid': 'http://www.hindustantimes.com/autos/maruti-ignis-launch.... 'link': 'http://www.hindustantimes.com/autos/maruti-ignis-launch.... 'media': 'http://www.hindustantimes.com/rf/image_size_630x354/HT/... 'pubDate': 'Thu 12 Jan 2017 12:33:04 GMT ' 'title': 'Maruti Ignis launches on Jan 13: Five cars that threa..... } Then we simply append this dict element to the list אתרי חדשות . לבסוף הרשימה הזו מוחזרת.  כפי שאתה יכול לראות, נתוני קובץ ה-XML ההיררכיים הומרו לקובץ CSV פשוט כך שכל כתבות החדשות מאוחסנות בצורה של טבלה. זה מקל גם על הרחבת מסד הנתונים. כמו כן ניתן להשתמש בנתונים דמויי JSON ישירות באפליקציות שלהם! זוהי האלטרנטיבה הטובה ביותר לחילוץ נתונים מאתרים שאינם מספקים API ציבורי אך מספקים עדכוני RSS מסוימים. ניתן למצוא את כל הקוד והקבצים המשמשים במאמר לעיל כָּאן . מה הלאה?
כפי שאתה יכול לראות, נתוני קובץ ה-XML ההיררכיים הומרו לקובץ CSV פשוט כך שכל כתבות החדשות מאוחסנות בצורה של טבלה. זה מקל גם על הרחבת מסד הנתונים. כמו כן ניתן להשתמש בנתונים דמויי JSON ישירות באפליקציות שלהם! זוהי האלטרנטיבה הטובה ביותר לחילוץ נתונים מאתרים שאינם מספקים API ציבורי אך מספקים עדכוני RSS מסוימים. ניתן למצוא את כל הקוד והקבצים המשמשים במאמר לעיל כָּאן . מה הלאה? 
מאמרים למעלה