Semplice gestore di download multithread in Python
UN Scarica Gestore è fondamentalmente un programma per computer dedicato al compito di scaricare file autonomi da Internet. Qui creeremo un semplice Download Manager con l'aiuto di thread in Python. Utilizzando il multithreading un file può essere scaricato sotto forma di blocchi contemporaneamente da thread diversi. Per implementarlo creeremo un semplice strumento da riga di comando che accetta l'URL del file e quindi lo scarica.
Prerequisiti: macchina Windows con Python installato.
Impostare
Scarica i pacchetti menzionati di seguito dal prompt dei comandi.
1. Pacchetto Click: Click è un pacchetto Python per creare bellissime interfacce a riga di comando con il minimo codice necessario. È il kit di creazione dell'interfaccia della riga di comando.
2. Pacchetto richieste: in questo strumento scaricheremo un file in base all'URL (indirizzi HTTP). Requests è una libreria HTTP scritta in Python che consente di inviare richieste HTTP. È possibile aggiungere intestazioni a file di dati multiparte e parametri con semplici dizionari Python e accedere ai dati di risposta nello stesso modo.
richieste di installazione pip
3. Pacchetto threading: per lavorare con i thread abbiamo bisogno del pacchetto threading.
pip installa il threading
Attuazione
Nota:
Il programma è stato suddiviso in parti per facilitarne la comprensione. Assicurati di non perdere nessuna parte del codice durante l'esecuzione del programma.
Passaggio 1: importa i pacchetti richiesti
Questi pacchetti forniscono gli strumenti necessari per fare in modo che le richieste web gestiscano gli input della riga di comando e creino thread.
Python import click import requests import threading
Passaggio 2: creare la funzione gestore
Ogni thread eseguirà questa funzione per scaricare la sua parte specifica del file. Questa funzione è responsabile della richiesta solo di un intervallo specifico di byte e della loro scrittura nella posizione corretta nel file.
Python def Handler ( start end url filename ): headers = { 'Range' : f 'bytes= { start } - { end } ' } r = requests . get ( url headers = headers stream = True ) with open ( filename 'r+b' ) as fp : fp . seek ( start ) fp . write ( r . content )
Passaggio 3: definire la funzione principale con un clic
Trasforma la funzione in un'utilità della riga di comando. Ciò definisce il modo in cui gli utenti interagiscono con lo script dalla riga di comando.
Python #Note: This code will not work on online IDE @click . command ( help = 'Downloads the specified file with given name using multi-threading' ) @click . option ( '--number_of_threads' default = 4 help = 'Number of threads to use' ) @click . option ( '--name' type = click . Path () help = 'Name to save the file as (with extension)' ) @click . argument ( 'url_of_file' type = str ) def download_file ( url_of_file name number_of_threads ):
Passaggio 4: imposta il nome file e determina la dimensione del file
Abbiamo bisogno della dimensione del file per dividere il download tra thread e garantire che il server supporti download a distanza.
Python r = requests . head ( url_of_file ) file_name = name if name else url_of_file . split ( '/' )[ - 1 ] try : file_size = int ( r . headers [ 'Content-Length' ]) except : print ( 'Invalid URL or missing Content-Length header.' ) return
Step 5: Preallocate File Space
La preallocazione garantisce che il file abbia le dimensioni corrette prima di scrivere blocchi in intervalli di byte specifici.
Python part = file_size // number_of_threads with open ( file_name 'wb' ) as fp : fp . write ( b ' � ' * file_size )
Passaggio 6: crea discussioni
Ai thread vengono assegnati intervalli di byte specifici da scaricare in parallelo.
Python threads = [] for i in range ( number_of_threads ): start = part * i end = file_size - 1 if i == number_of_threads - 1 else ( start + part - 1 ) t = threading . Thread ( target = Handler kwargs = { 'start' : start 'end' : end 'url' : url_of_file 'filename' : file_name }) threads . append ( t ) t . start ()
Passaggio 7: unisciti ai thread
Garantisce che tutti i thread siano completati prima che il programma termini.
Python for t in threads : t . join () print ( f ' { file_name } downloaded successfully!' ) if __name__ == '__main__' : download_file ()
Codice:
Python import click import requests import threading def Handler ( start end url filename ): headers = { 'Range' : f 'bytes= { start } - { end } ' } r = requests . get ( url headers = headers stream = True ) with open ( filename 'r+b' ) as fp : fp . seek ( start ) fp . write ( r . content ) @click . command ( help = 'Downloads the specified file with given name using multi-threading' ) @click . option ( '--number_of_threads' default = 4 help = 'Number of threads to use' ) @click . option ( '--name' type = click . Path () help = 'Name to save the file as (with extension)' ) @click . argument ( 'url_of_file' type = str ) def download_file ( url_of_file name number_of_threads ): r = requests . head ( url_of_file ) if name : file_name = name else : file_name = url_of_file . split ( '/' )[ - 1 ] try : file_size = int ( r . headers [ 'Content-Length' ]) except : print ( 'Invalid URL or missing Content-Length header.' ) return part = file_size // number_of_threads with open ( file_name 'wb' ) as fp : fp . write ( b ' � ' * file_size ) threads = [] for i in range ( number_of_threads ): start = part * i # Make sure the last part downloads till the end of file end = file_size - 1 if i == number_of_threads - 1 else ( start + part - 1 ) t = threading . Thread ( target = Handler kwargs = { 'start' : start 'end' : end 'url' : url_of_file 'filename' : file_name }) threads . append ( t ) t . start () for t in threads : t . join () print ( f ' { file_name } downloaded successfully!' ) if __name__ == '__main__' : download_file ()
Abbiamo finito con la parte di codifica e ora seguiamo i comandi mostrati di seguito per eseguire il file .py.
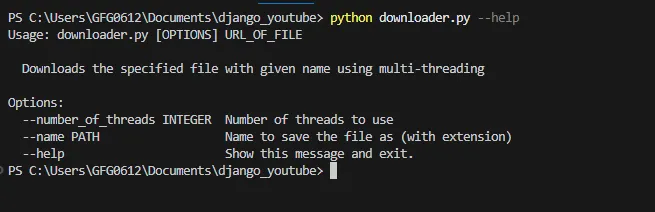
python filename.py –-helpProduzione:
python nomefile.py –-help
Questo comando mostra l'utilizzo dello strumento clic command e le opzioni che lo strumento può accettare. Di seguito è riportato il comando di esempio in cui proviamo a scaricare un file immagine jpg da un URL e diamo anche un nome e un numero di thread.
comando di esempio per scaricare un jpg
Dopo aver eseguito tutto correttamente, sarai in grado di vedere il tuo file (flower.webp in questo caso) nella directory della tua cartella come mostrato di seguito:
directory
Finalmente abbiamo finito con successo e questo è uno dei modi per costruire un semplice gestore di download multithread in Python.
 python nomefile.py –-help
python nomefile.py –-help  comando di esempio per scaricare un jpg
comando di esempio per scaricare un jpg  directory
directory