Panda DataFrame.pivot_table()
I Panda tabella pivot() viene utilizzato per calcolare, aggregare e riepilogare i dati. È definito come un potente strumento che aggrega dati con calcoli come Somma, Conteggio, Media, Massimo, E minimo .
Consente inoltre all'utente di ordinare e filtrare i dati una volta creata la tabella pivot.
parametri:
Se passiamo un array, deve avere la stessa lunghezza dei dati.
Se passiamo un array, deve avere la stessa lunghezza dei dati.
Se passiamo l'elenco delle funzioni, la tabella pivot risultante avrà colonne gerarchiche il cui livello superiore sono i nomi delle funzioni.
Se passiamo un dict, la chiave viene definita colonna da aggregare e il valore è funzione o elenco di funzioni.
Ritorna:
Restituisce un DataFrame come output.
Esempio:
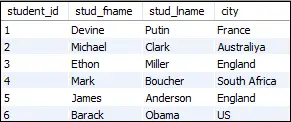
# importing pandas as pd import pandas as pd import numpy as np # create dataframe info = pd.DataFrame({'P': ['Smith', 'John', 'William', 'Parker'], 'Q': ['Python', 'C', 'C++', 'Java'], 'R': [19, 24, 22, 25]}) info table = pd.pivot_table(info, index =['P', 'Q']) table Produzione
P Q R John C 24 Parker Java 25 Smith Python 19 William C 22