Metodo DataFrame.to_excel() in Panda

IL eccellere() Il metodo viene utilizzato per esportare DataFrame nel file Excel. Per scrivere un singolo oggetto nel file Excel, dobbiamo specificare il nome del file di destinazione. Se vogliamo scrivere su più fogli, dobbiamo creare un oggetto ExcelWriter con nome file di destinazione e dobbiamo anche specificare il foglio nel file in cui dobbiamo scrivere. È possibile scrivere più fogli anche specificando il nome_foglio univoco. È necessario salvare le modifiche per tutti i dati scritti nel file.
Sintassi:
data.to_excel( excel_writer, sheet_name='Sheet1', **kwargs )
parametri:
| argomenti | Tipo | Descrizione |
|---|---|---|
| excel_writer | oggetto str o ExcelWriter | Percorso del file o ExcelWriter esistente |
| nome_foglio | str, predefinito 'Foglio1' | Nome del foglio che conterrà DataFrame |
| colonne | sequenza o elenco di str, facoltativo | Colonne da scrivere |
| indice | bool, predefinito Vero | Scrivi i nomi delle righe (indice) |
| etichetta_indice | str o sequenza, facoltativo | Etichetta della colonna per le colonne dell'indice, se lo si desidera. Se non specificato e `header` e `index` sono True, vengono utilizzati i nomi degli indici. Dovrebbe essere fornita una sequenza se DataFrame utilizza MultiIndex. |
- È possibile fornire il nome del file Excel o l'oggetto Excelwrite.
- Per impostazione predefinita il numero del foglio è 1, è possibile modificarlo inserendo il valore dell'argomento nome_foglio.
- È possibile fornire il nome delle colonne in cui archiviare i dati inserendo il valore delle colonne degli argomenti.
- Per impostazione predefinita l'indice è etichettato con numeri come 0,1,2 ... e così via, è possibile modificarlo passando una sequenza dell'elenco per il valore dell'argomento indice.
Di seguito è riportata l'implementazione del metodo sopra:
Python3
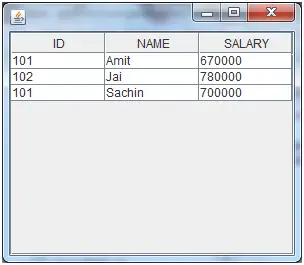
# importing packages> import> pandas as pd> > # dictionary of data> dct> => {> 'ID'> : {> 0> :> 23> ,> 1> :> 43> ,> 2> :> 12> ,> > 3> :> 13> ,> 4> :> 67> ,> 5> :> 89> ,> > 6> :> 90> ,> 7> :> 56> ,> 8> :> 34> },> > 'Name'> : {> 0> :> 'Ram'> ,> 1> :> 'Deep'> ,> > 2> :> 'Yash'> ,> 3> :> 'Aman'> ,> > 4> :> 'Arjun'> ,> 5> :> 'Aditya'> ,> > 6> :> 'Divya'> ,> 7> :> 'Chalsea'> ,> > 8> :> 'Akash'> },> > 'Marks'> : {> 0> :> 89> ,> 1> :> 97> ,> 2> :> 45> ,> 3> :> 78> ,> > 4> :> 56> ,> 5> :> 76> ,> 6> :> 100> ,> 7> :> 87> ,> > 8> :> 81> },> > 'Grade'> : {> 0> :> 'B'> ,> 1> :> 'A'> ,> 2> :> 'F'> ,> 3> :> 'C'> ,> > 4> :> 'E'> ,> 5> :> 'C'> ,> 6> :> 'A'> ,> 7> :> 'B'> ,> > 8> :> 'B'> }> > }> > # forming dataframe> data> => pd.DataFrame(dct)> > # storing into the excel file> data.to_excel(> 'output.xlsx'> )> |
Produzione :

Nell'esempio sopra,
- Per impostazione predefinita l'indice è etichettato come 0,1,…. e così via.
- Poiché il nostro DataFrame ha nomi di colonne, le colonne sono etichettate.
- Per impostazione predefinita, viene salvato nel Foglio1.