PDF-fájlok kezelése Pythonban

Mindenkinek ismernie kell a PDF-fájlokat. Valójában ezek az egyik legfontosabb és legszélesebb körben használt digitális média. A PDF jelentése Hordozható dokumentum formátum . Használ .pdf kiterjesztés. A szoftver hardvertől vagy operációs rendszertől független dokumentumok megbízható bemutatására és cseréjére szolgál.
Feltalálta Vályogtégla A PDF ma már a Nemzetközi Szabványügyi Szervezet (ISO) által fenntartott nyílt szabvány. A PDF-fájlok hivatkozásokat és gombokat tartalmazhatnak audio-videó és üzleti logika mezőiből.
Ebben a cikkben megtudjuk, hogyan végezhetünk különféle műveleteket, például:
- Szöveg kinyerése PDF-ből
- Forgatható PDF oldalak
- PDF-ek egyesítése
- PDF felosztása
- Vízjel hozzáadása PDF-oldalakhoz
Telepítés: Egyszerű python szkriptek használata!
Harmadik féltől származó pypdf modult fogunk használni.
A pypdf egy python könyvtár, amely PDF eszközkészletként készült. Képes:
- Dokumentuminformációk kinyerése (a cím szerzője…)
- A dokumentumok oldalról oldalra bontása
- Dokumentumok egyesítése oldalanként
- Oldalak kivágása
- Több oldal összevonása egyetlen oldalba
- PDF fájlok titkosítása és visszafejtése
- és még több!
A pypdf telepítéséhez futtassa a következő parancsot a parancssorból:
pip install pypdfEz a modulnév megkülönbözteti a kis- és nagybetűket, ezért ellenőrizze, hogy a és kisbetűs, minden más nagybetűs. Az oktatóanyagban/cikkben használt összes kód és PDF fájl elérhető itt .
1. Szöveg kinyerése PDF fájlból
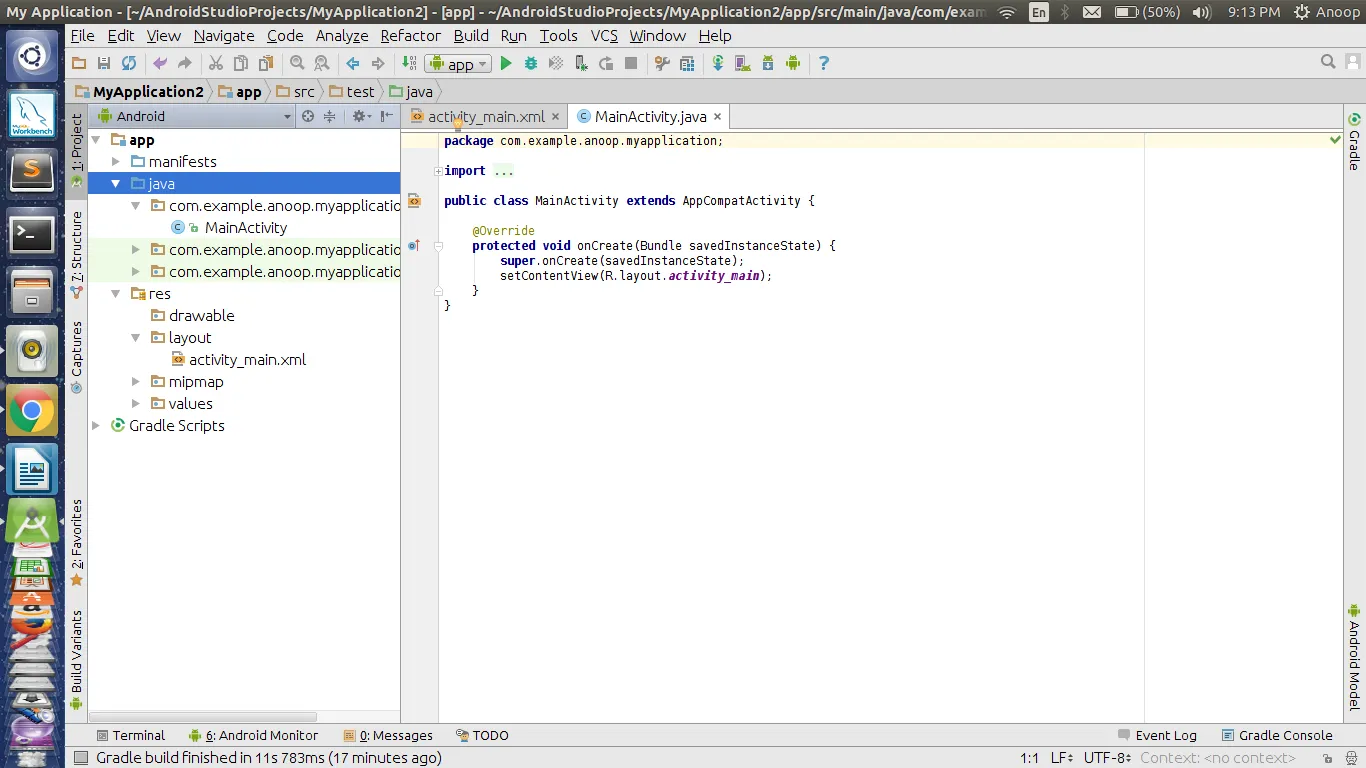
PythonA fenti program kimenete így néz ki:
20
PythonBasics
S.R.Doty
August272008
Contents
1Preliminaries
4
1.1WhatisPython?...................................
..4
1.2Installationanddocumentation....................
.........4 [and some more lines...]
Próbáljuk meg megérteni a fenti kódot darabokban:
reader = PdfReader('example.pdf')
- Itt létrehozunk egy objektumot PdfReader osztályú pypdf modult, és adja át a PDF-fájl elérési útját, és szerezzen be egy PDF-olvasó objektumot.
print(len(reader.pages))
- oldalakat tulajdonság megadja a PDF-fájl oldalainak számát. Például a mi esetünkben ez 20 (lásd a kimenet első sorát).
pageObj = reader.pages[0]
- Most létrehozunk egy objektumot PageObject pypdf modul osztálya. A PDF olvasó objektumnak van funkciója oldalak[] amely az oldalszámot veszi (a 0 indextől kezdve) argumentumként, és visszaadja az oldalobjektumot.
print(pageObj.extract_text())
- Az oldalobjektumnak van funkciója kivonat_szöveg() szöveg kinyeréséhez a PDF-oldalról.
Jegyzet: Míg a PDF-fájlok kiválóan alkalmasak a szöveg olyan elrendezésére, amelyet az emberek könnyen nyomtathatnak és olvashatnak, a szoftverek számára nem egyszerű egyszerű szöveggé elemezni. Ennek megfelelően a pypdf hibákat követhet el, amikor szöveget bont ki egy PDF-ből, és egyes PDF-eket egyáltalán nem tud megnyitni. Ez ellen sajnos nem sokat tudsz tenni. Előfordulhat, hogy a pypdf egyszerűen nem tud együttműködni bizonyos PDF-fájlokkal.
2. Forgató PDF-oldalak
# importing the required classes from pypdf import PdfReader PdfWriter def PDFrotate ( origFileName newFileName rotation ): # creating a pdf Reader object reader = PdfReader ( origFileName ) # creating a pdf writer object for new pdf writer = PdfWriter () # rotating each page for page in range ( len ( reader . pages )): pageObj = reader . pages [ page ] pageObj . rotate ( rotation ) # Add the rotated page object to the PDF writer writer . add_page ( pageObj ) # Write the rotated pages to the new PDF file with open ( newFileName 'wb' ) as newFile : writer . write ( newFile ) def main (): # original pdf file name origFileName = 'example.pdf' # new pdf file name newFileName = 'rotated_example.pdf' # rotation angle rotation = 270 # calling the PDFrotate function PDFrotate ( origFileName newFileName rotation ) if __name__ == '__main__' : # calling the main function main ()
Itt láthatja, hogyan az első oldal elforgatott_example.pdf így néz ki (jobb oldali kép) elforgatás után:

Néhány fontos pont a fenti kóddal kapcsolatban:
- Az elforgatáshoz először létrehozunk egy PDF olvasó objektumot az eredeti PDF-ből.
writer = PdfWriter()
- Az elforgatott oldalak új PDF-fájlba kerülnek. PDF-ekbe íráshoz az objektumot használjuk PdfWriter pypdf modul osztálya.
for page in range(len(pdfReader.pages)):
pageObj = pdfReader.pages[page]
pageObj.rotate(rotation)
writer.add_page(pageObj)
- Most ismételjük az eredeti PDF minden oldalát. Az oldalobjektumot kapjuk .pages[] PDF olvasó osztály módszere. Most forgatjuk el az oldalt forog() oldalobjektum osztály metódusa. Ezután hozzáadunk egy oldalt a PDF író objektumhoz a használatával add() PDF író osztály metódusa az elforgatott oldalobjektum átadásával.
newFile = open(newFileName 'wb')
writer.write(newFile)
newFile.close()
- Most egy új PDF fájlba kell írnunk a PDF oldalakat. Először megnyitjuk az új fájlobjektumot, és a segítségével PDF oldalakat írunk rá írj () PDF író objektum módszere. Végül bezárjuk az eredeti PDF fájl objektumot és az új fájl objektumot.
3. PDF fájlok egyesítése
Python # importing required modules from pypdf import PdfWriter def PDFmerge ( pdfs output ): # creating pdf file writer object pdfWriter = PdfWriter () # appending pdfs one by one for pdf in pdfs : pdfWriter . append ( pdf ) # writing combined pdf to output pdf file with open ( output 'wb' ) as f : pdfWriter . write ( f ) def main (): # pdf files to merge pdfs = [ 'example.pdf' 'rotated_example.pdf' ] # output pdf file name output = 'combined_example.pdf' # calling pdf merge function PDFmerge ( pdfs = pdfs output = output ) if __name__ == '__main__' : # calling the main function main ()
A fenti program kimenete egy kombinált PDF kombinált_példa.pdf összevonásával kapjuk példa.pdf és elforgatott_example.pdf .
- Vessünk egy pillantást a program fontos szempontjaira:
pdfWriter = PdfWriter() - Az összevonáshoz egy előre elkészített osztályt használunk PdfWriter pypdf modulból.
Itt létrehozunk egy objektumot pdfwriter PDF író osztályból
# appending pdfs one by one
for pdf in pdfs:
pdfWriter.append(pdf)
- Most minden PDF fájl objektumát hozzáfűzzük a PDF író objektumokhoz a segítségével mellékel() módszer.
# writing combined pdf to output pdf file
with open(output 'wb') as f:
pdfWriter.write(f)
- Végül a PDF oldalakat a kimeneti PDF fájlba írjuk a segítségével írj PDF író objektum módszere.
4. PDF fájl felosztása
Python # importing the required modules from pypdf import PdfReader PdfWriter def PDFsplit ( pdf splits ): # creating pdf reader object reader = PdfReader ( pdf ) # starting index of first slice start = 0 # starting index of last slice end = splits [ 0 ] for i in range ( len ( splits ) + 1 ): # creating pdf writer object for (i+1)th split writer = PdfWriter () # output pdf file name outputpdf = pdf . split ( '.pdf' )[ 0 ] + str ( i ) + '.pdf' # adding pages to pdf writer object for page in range ( start end ): writer . add_page ( reader . pages [ page ]) # writing split pdf pages to pdf file with open ( outputpdf 'wb' ) as f : writer . write ( f ) # interchanging page split start position for next split start = end try : # setting split end position for next split end = splits [ i + 1 ] except IndexError : # setting split end position for last split end = len ( reader . pages ) def main (): # pdf file to split pdf = 'example.pdf' # split page positions splits = [ 2 4 ] # calling PDFsplit function to split pdf PDFsplit ( pdf splits ) if __name__ == '__main__' : # calling the main function main ()
A kimenet három új PDF fájl lesz 1. felosztás (01. oldal) 2. osztás (23. oldal) 3. osztás (4. oldal vége) .
A fenti python programban nem használtak új függvényt vagy osztályt. Egyszerű logika és iterációk segítségével elkészítettük az átadott PDF felosztását az átadott lista szerint hasít .
5. Vízjel hozzáadása PDF-oldalakhoz
Python # importing the required modules from pypdf import PdfReader PdfWriter def add_watermark ( wmFile pageObj ): # creating pdf reader object of watermark pdf file reader = PdfReader ( wmFile ) # merging watermark pdf's first page with passed page object. pageObj . merge_page ( reader . pages [ 0 ]) # returning watermarked page object return pageObj def main (): # watermark pdf file name mywatermark = 'watermark.pdf' # original pdf file name origFileName = 'example.pdf' # new pdf file name newFileName = 'watermarked_example.pdf' # creating pdf File object of original pdf pdfFileObj = open ( origFileName 'rb' ) # creating a pdf Reader object reader = PdfReader ( pdfFileObj ) # creating a pdf writer object for new pdf writer = PdfWriter () # adding watermark to each page for page in range ( len ( reader . pages )): # creating watermarked page object wmpageObj = add_watermark ( mywatermark reader . pages [ page ]) # adding watermarked page object to pdf writer writer . add_page ( wmpageObj ) # writing watermarked pages to new file with open ( newFileName 'wb' ) as newFile : writer . write ( newFile ) # closing the original pdf file object pdfFileObj . close () if __name__ == '__main__' : # calling the main function main ()
Így néz ki az eredeti (bal oldali) és a vízjeles (jobb oldali) PDF-fájl első oldala:

- Az összes folyamat megegyezik az oldalforgatási példával. Az egyetlen különbség a következő:
wmpageObj = add_watermark(mywatermark pdfReader.pages[page])
- Az oldalobjektum vízjeles oldalobjektummá alakul a használatával add_watermark() funkció.
- Próbáljuk megérteni add_watermark() funkció:
reader = PdfReader(wmFile)
pageObj.merge_page(reader.pages[0])
return pageObj
- Mindenekelőtt létrehozunk egy PDF olvasó objektumot vízjel.pdf . Az általunk használt átadott oldalobjektumhoz merge_page() függvényt, és adja át a vízjel PDF olvasó objektum első oldalának oldalobjektumát. Ez ráborítja a vízjelet az átadott oldalobjektumra.
És itt elérkeztünk ennek a hosszú oktatóanyagnak a végére, amely a PDF-fájlokkal való munkavégzésről szól a Pythonban.
Most könnyedén létrehozhatja saját PDF-kezelőjét!
Referenciák:
- https://automatetheboringstuff.com/chapter13/
- https://pypi.org/project/pypdf/
Ha tetszik a GeeksforGeeks, és szeretne hozzájárulni, írhat egy cikket a write.geeksforgeeks.org oldalon, vagy elküldheti cikkét a [email protected] címre. Tekintse meg cikkét a GeeksforGeeks főoldalán, és segítsen másoknak.
Kérjük, írjon megjegyzéseket, ha valami helytelent talál, vagy ha további információkat szeretne megosztani a fent tárgyalt témával kapcsolatban.