Tokenizirajte tekst pomoću NLTK-a u pythonu
Tokenizacija teksta temeljna je tehnika obrade prirodnog jezika (NLP), a jedna takva tehnika je Tokenizacija. To je proces dijeljenja teksta na manje komponente ili žetone. To mogu biti:
- Riječi: Volim NLP → ['I' 'volim' 'NLP']
- Rečenice: Volim NLP. Python je super. → ['Volim NLP.' 'Python je sjajan.']
S Pythonovom popularnom bibliotekom NLTK (Natural Language Toolkit) dijeljenje teksta u smislene jedinice postaje jednostavno i ekstremno učinkovito.
Osnovna implementacija
Pogledajmo implementaciju tokenizacije pomoću NLTK-a u Pythonu
Korak 1: Instalirajte i postavite
Instalirajte točka modeli tokenizatora potrebni za tokenizaciju rečenica i riječi.
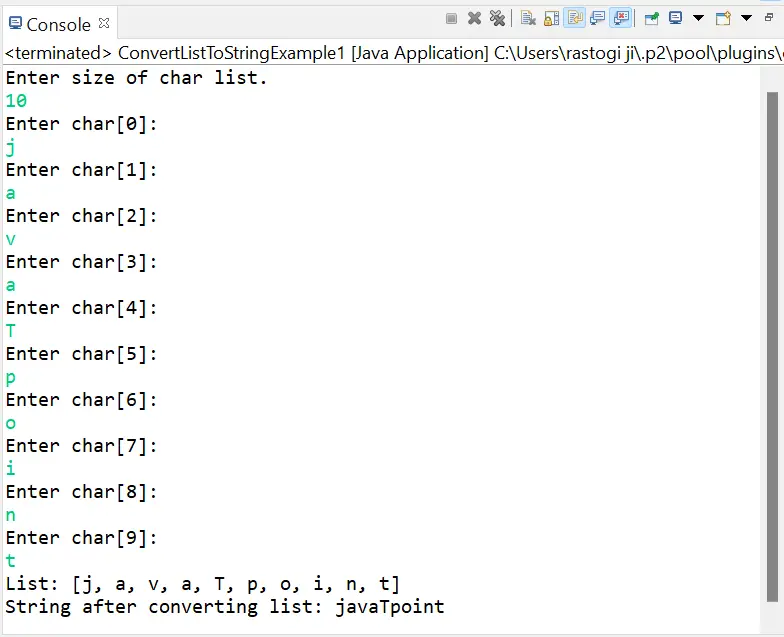
Python ! pip install nltk import nltk nltk . download ( 'punkt' )
Korak 2: Označite rečenice
sent_tokenize() dijeli niz na popis rečenica koje obrađuju interpunkcijske znakove i kratice.
Python from nltk.tokenize import sent_tokenize text = 'NLTK is a great NLP toolkit. It makes processing text easy!' sentences = sent_tokenize ( text ) print ( sentences )
Izlaz:
['NLTK je izvrstan NLP alat.' 'Olakšava obradu teksta!']
Korak 3: Tokenizirajte riječi
- word_tokenize() dijeli rečenicu na riječi i interpunkcijske znakove kao zasebne tokene.
- Obrađuje kontrakcije interpunkcijskih brojeva i više.
from nltk.tokenize import word_tokenize sentence = 'Tokenization is easy with NLTK's word_tokenize.' words = word_tokenize ( sentence ) print ( words )
Izlaz:
['Tokenizacija' 'je' 'laka' 'sa' 'NLTK' ''s' 'word_tokenize' '.']
Pogledajmo još neke primjere
1. WordPunctTokenizer
To Dijeli tekst na abecedne i neabecedne znakove
- Rastavlja sve nizove znakova riječi i interpunkcijskih znakova u tokene.
- Posebno razdvaja kontrakcije (Don't postaje Don't).
- Dijeli E-mailove na E-mailove.
from nltk.tokenize import WordPunctTokenizer tokenizer = WordPunctTokenizer () tokens = tokenizer . tokenize ( 'Don't split contractions. E-mails: [email protected]!' ) print ( tokens )
Izlaz:
['Nemoj' ''' 't' 'split' 'kontrakcije' '.' 'E' '-' 'mailovi' ':' 'zdravo' '@' 'primjer' '.' 'com' '!']
2. TreebankWordTokenizer
Pogodan je za lingvističku analizu, obrađuje interpunkciju i kontrakcije.
- Oponaša tokenizaciju u stilu Penn Treebanka koja se obično koristi za NLP lingvističku analizu.
- Inteligentnije barata određenim engleskim gramatičkim strukturama.
from nltk.tokenize import TreebankWordTokenizer tokenizer = TreebankWordTokenizer () tokens = tokenizer . tokenize ( 'Have a look at NLTK's tokenizers.' ) print ( tokens )
Izlaz:
['Pogledajte' 'NLTK' ''s' 'tokenizere' '.']
3. Regex Tokenizer
Prilagođava dijeljenje na temelju uzorka.
- Tokenizira na temelju uzorka regularnog izraza.
- w+ podudara riječi i brojeve potpuno izostavljajući interpunkciju.
from nltk.tokenize import RegexpTokenizer tokenizer = RegexpTokenizer ( r 'w+' ) tokens = tokenizer . tokenize ( 'Custom rule: keep only words & numbers drop punctuation!' ) print ( tokens )
Izlaz:
['Prilagođeno' 'pravilo' 'zadrži' 'samo' 'riječi' 'brojevi' 'ispusti' 'interpunkcija']
NLTK pruža koristan i user-friendly alat za tokenizaciju teksta u Pythonu koji podržava niz potreba za tokenizacijom od osnovnog dijeljenja riječi i rečenica do naprednih prilagođenih uzoraka.
Napravi kviz