Pandat lukevat CSV:tä Pythonissa
CSV-tiedostot ovat pilkuilla erotettuja tiedostoja. Jotta voimme käyttää CSV-tiedoston tietoja, tarvitsemme Pandasta funktion read_csv(), joka hakee tiedot tietokehyksen muodossa.
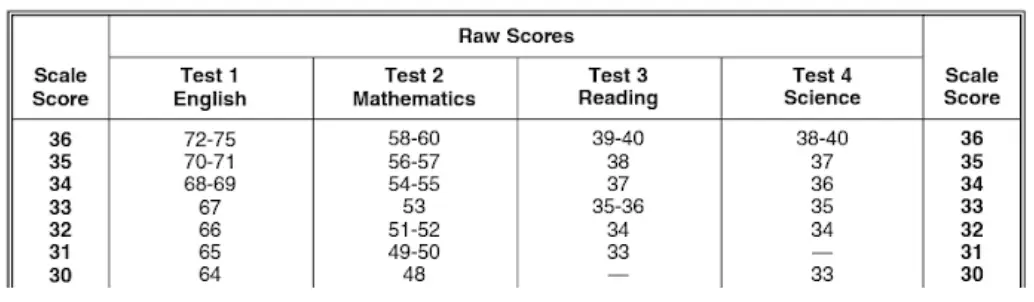
read_csv() syntaksi
Tässä on Pandat lukevat CSV:tä syntaksi parametreineen.
Syntaksi: pd.read_csv (filepath_or_buffer, sep=’ ,’ , header=’infer’, index_col=Ei mitään, usecols=Ei mitään, engine=Ei mitään, skiprows=Ei mitään, nrows=Ei mitään)
Parametrit:
- tiedostopolku_tai_puskuri : csv-tiedoston sijainti. Se hyväksyy minkä tahansa tiedoston merkkijonopolun tai URL-osoitteen.
- syys : Se tarkoittaa erotinta, oletusarvo on ', '.
- otsikko : Se hyväksyy int, int-luettelon, sarakkeiden niminä käytettävät rivinumerot ja tietojen alun. Jos nimiä ei välitetä, eli header=Ei mitään, se näyttää ensimmäisen sarakkeen muodossa 0, toisen 1:nä ja niin edelleen.
- käytä koloja : Hakee vain valitut sarakkeet CSV-tiedostosta.
- nrows : Tietojoukosta näytettävien rivien lukumäärä.
- index_col : Jos Ei mitään, indeksinumeroita ei näytetä tietueiden kanssa.
- hyppyjä : Ohittaa ohitetut rivit uudessa tietokehyksessä.
Lue CSV-tiedosto käyttämällä Pandas read_csv:tä
Ennen kuin käytät tätä toimintoa, meidän on tuotava Pandat kirjasto, lataamme CSV-tiedoston Pandasin avulla.
PYTHON3
# Import pandas> import> pandas as pd> # reading csv file> df> => pd.read_csv(> 'people.csv'> )> print> (df.head())> |
Lähtö:
First Name Last Name Sex Email Date of birth Job Title 0 Shelby Terrell Male [email protected] 1945-10-26 Games developer 1 Phillip Summers Female [email protected] 1910-03-24 Phytotherapist 2 Kristine Travis Male [email protected] 1992-07-02 Homeopath 3 Yesenia Martinez Male [email protected] 2017-08-03 Market researcher 4 Lori Todd Male [email protected] 1938-12-01 Veterinary surgeon
Käyttämällä syys kohdassa read_csv()
Tässä esimerkissä otamme CSV-tiedoston ja lisäämme sitten erikoismerkkejä nähdäksemme, miten syys parametri toimii.
Python 3
# sample = 'totalbill_tip, sex:smoker, day_time, size> # 16.99, 1.01:Female|No, Sun, Dinner, 2> # 10.34, 1.66, Male, No|Sun:Dinner, 3> # 21.01:3.5_Male, No:Sun, Dinner, 3> #23.68, 3.31, Male|No, Sun_Dinner, 2> # 24.59:3.61, Female_No, Sun, Dinner, 4> # 25.29, 4.71|Male, No:Sun, Dinner, 4'> # Importing pandas library> import> pandas as pd> # Load the data of csv> df> => pd.read_csv(> 'sample.csv'> ,> > sep> => '[:, |_]'> ,> > engine> => 'python'> )> # Print the Dataframe> print> (df)> |
Lähtö:
totalbill tip Unnamed: 2 sex smoker Unnamed: 5 day time Unnamed: 8 size 16.99 NaN 1.01 Female No NaN Sun NaN Dinner NaN 2 10.34 NaN 1.66 NaN Male NaN No Sun Dinner NaN 3 21.01 3.50 Male NaN No Sun NaN Dinner NaN 3.0 None 23.68 NaN 3.31 NaN Male No NaN Sun Dinner NaN 2 24.59 3.61 NaN Female No NaN Sun NaN Dinner NaN 2 25.29 NaN 4.71 Male NaN No Sun NaN Dinner NaN 4
Usecollien käyttö read_csv()
Tässä määritämme vain 3 saraketta, eli [First Name, Sex, Email] ladattavaksi, ja käytämme otsikkoa 0 oletusotsikona.
Python 3
df> => pd.read_csv(> 'people.csv'> ,> > header> => 0> ,> > usecols> => [> 'First Name'> ,> 'Sex'> ,> 'Email'> ])> # printing dataframe> print> (df.head())> |
Lähtö:
First Name Sex Email 0 Shelby Male [email protected] 1 Phillip Female [email protected] 2 Kristine Male [email protected] 3 Yesenia Male [email protected] 4 Lori Male [email protected]
Index_colin käyttäminen read_csv()
Tässä käytämme seksiä indeksi ensin ja sitten Työnimike index, voimme yksinkertaisesti indeksoida otsikon uudelleen index_col parametri.
Python 3
df> => pd.read_csv(> 'people.csv'> ,> > header> => 0> ,> > index_col> => [> 'Sex'> ,> 'Job Title'> ],> > usecols> => [> 'Sex'> ,> 'Job Title'> ,> 'Email'> ])> print> (df.head())> |
Lähtö:
Email Sex Job Title Male Games developer [email protected] Female Phytotherapist [email protected] Male Homeopath [email protected] Market researcher [email protected] Veterinary surgeon [email protected]
nrow:ien käyttö read_csv()
Tässä näytämme vain 5 riviä käyttämällä nrows-parametri .
Python 3
df> => pd.read_csv(> 'people.csv'> ,> > header> => 0> ,> > index_col> => [> 'Sex'> ,> 'Job Title'> ],> > usecols> => [> 'Sex'> ,> 'Job Title'> ,> 'Email'> ],> > nrows> => 3> )> print> (df)> |
Lähtö:
Email Sex Job Title Male Games developer [email protected] Female Phytotherapist [email protected] Male Homeopath [email protected]
Ohituslauseiden käyttö read_csv()
The hyppyjä auta ohittamaan joitakin rivejä CSV:ssä, eli tässä huomaat, että ohitusriveissä mainitut rivit on ohitettu alkuperäisestä tietojoukosta.
Python 3
df> => pd.read_csv(> 'people.csv'> )> print> (> 'Previous Dataset: '> )> print> (df)> # using skiprows> df> => pd.read_csv(> 'people.csv'> , skiprows> => [> 1> ,> 5> ])> print> (> 'Dataset After skipping rows: '> )> print> (df)> |
Lähtö:
Previous Dataset: First Name Last Name Sex Email Date of birth Job Title 0 Shelby Terrell Male [email protected] 1945-10-26 Games developer 1 Phillip Summers Female [email protected] 1910-03-24 Phytotherapist 2 Kristine Travis Male [email protected] 1992-07-02 Homeopath 3 Yesenia Martinez Male [email protected] 2017-08-03 Market researcher 4 Lori Todd Male [email protected] 1938-12-01 Veterinary surgeon 5 Erin Day Male [email protected] 2015-10-28 Management officer 6 Katherine Buck Female [email protected] 1989-01-22 Analyst 7 Ricardo Hinton Male [email protected] 1924-03-26 Hydrogeologist Dataset After skipping rows: First Name Last Name Sex Email Date of birth Job Title 0 Shelby Terrell Male [email protected] 1945-10-26 Games developer 1 Kristine Travis Male [email protected] 1992-07-02 Homeopath 2 Yesenia Martinez Male [email protected] 2017-08-03 Market researcher 3 Lori Todd Male [email protected] 1938-12-01 Veterinary surgeon 4 Katherine Buck Female [email protected] 1989-01-22 Analyst 5 Ricardo Hinton Male [email protected] 1924-03-26 Hydrogeologist