Hash-taulukon toteutus C/C++:ssa käyttämällä erillistä ketjutusta
Esittely:
URL-osoitteiden lyhentäjät ovat esimerkki tiivistämisestä, koska se yhdistää suuren URL-osoitteen pieneen kokoon
Joitakin esimerkkejä hash-funktioista:
- avain % kauhojen lukumäärä
- Merkin * PrimeNumber ASCII-arvo x . Missä x = 1, 2, 3….n
- Voit tehdä oman hash-funktion, mutta sen pitäisi olla hyvä hash-funktio, joka antaa vähemmän törmäyksiä.

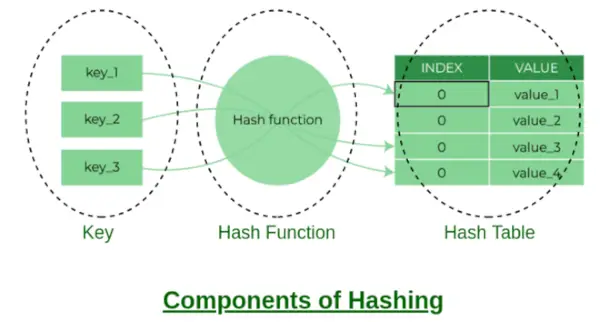
Hashingin osat
Ryhmän indeksi:
Hash-funktion palauttama arvo on erillisessä ketjutusmenetelmässä avaimen ämpäriindeksi. Jokaista taulukon indeksiä kutsutaan säilöksi, koska se on linkitetyn luettelon segmentti.
Uudelleentarkistus:
Uudelleenhajotus on konsepti, joka vähentää törmäystä, kun elementtejä lisätään nykyisessä hash-taulukossa. Se tekee uuden kaksinkertaisen kokoisen taulukon ja kopioi siihen aiemmat taulukon elementit ja se on kuin vektorin sisäinen työskentely C++:ssa. Hash-funktion tulisi luonnollisesti olla dynaaminen, koska sen pitäisi heijastaa joitain muutoksia, kun kapasiteettia lisätään. Hajautusfunktio sisältää siinä olevan hash-taulukon kapasiteetin, joten kun avainarvoja kopioidaan edellisestä taulukon hash-funktiosta, saadaan erilaisia kauhaindeksejä, koska se riippuu hash-taulukon kapasiteetista (ämpärit). Yleensä kun kuormituskertoimen arvo on suurempi kuin 0,5, uudelleentarkistus tehdään.
- Tuplaa taulukon koko.
- Kopioi edellisen taulukon elementit uuteen taulukkoon. Käytämme hash-funktiota kopioitaessamme jokaisen solmun uuteen taulukkoon uudelleen, joten se vähentää törmäyksiä.
- Poista edellinen matriisi muistista ja osoita hash-kartan sisäinen taulukko osoitin tähän uuteen taulukkoon.
- Yleensä kuormituskerroin = Hash Map -elementtien lukumäärä / ryhmien kokonaismäärä (kapasiteetti).
Törmäys:
Törmäys on tilanne, jossa kauhaindeksi ei ole tyhjä. Se tarkoittaa, että linkitetyn luettelon pää on läsnä kyseisessä ryhmähakemistossa. Meillä on vähintään kaksi arvoa, jotka liittyvät samaan ryhmäindeksiin.
Ohjelmamme tärkeimmät toiminnot
- Lisäys
- Hae
- Hash-toiminto
- Poistaa
- Rehashing
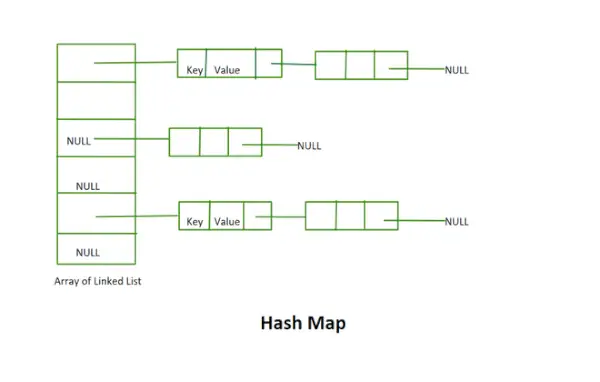
Hash kartta
Käyttöönotto ilman uudelleenkäsittelyä:
C
#include> #include> #include> // Linked List node> struct> node {> > // key is string> > char> * key;> > // value is also string> > char> * value;> > struct> node* next;> };> // like constructor> void> setNode(> struct> node* node,> char> * key,> char> * value)> {> > node->avain = avain;> > node->arvo = arvo;> > node->seuraava = NULL;> > return> ;> };> struct> hashMap {> > // Current number of elements in hashMap> > // and capacity of hashMap> > int> numOfElements, capacity;> > // hold base address array of linked list> > struct> node** arr;> };> // like constructor> void> initializeHashMap(> struct> hashMap* mp)> {> > // Default capacity in this case> > mp->kapasiteetti = 100;> > mp->numOfElements = 0;> > // array of size = 1> > mp->arr = (> struct> node**)> malloc> (> sizeof> (> struct> node*)> > * mp->kapasiteetti);> > return> ;> }> int> hashFunction(> struct> hashMap* mp,> char> * key)> {> > int> bucketIndex;> > int> sum = 0, factor = 31;> > for> (> int> i = 0; i <> strlen> (key); i++) {> > // sum = sum + (ascii value of> > // char * (primeNumber ^ x))...> > // where x = 1, 2, 3....n> > sum = ((sum % mp->kapasiteetti)> > + (((> int> )key[i]) * factor) % mp->kapasiteetti)> > % mp->kapasiteetti;> > // factor = factor * prime> > // number....(prime> > // number) ^ x> > factor = ((factor % __INT16_MAX__)> > * (31 % __INT16_MAX__))> > % __INT16_MAX__;> > }> > bucketIndex = sum;> > return> bucketIndex;> }> void> insert(> struct> hashMap* mp,> char> * key,> char> * value)> {> > // Getting bucket index for the given> > // key - value pair> > int> bucketIndex = hashFunction(mp, key);> > struct> node* newNode = (> struct> node*)> malloc> (> > // Creating a new node> > sizeof> (> struct> node));> > // Setting value of node> > setNode(newNode, key, value);> > // Bucket index is empty....no collision> > if> (mp->arr[bucketIndex] == NULL) {> > mp->arr[bucketIndex] = uusiSolmu;> > }> > // Collision> > else> {> > // Adding newNode at the head of> > // linked list which is present> > // at bucket index....insertion at> > // head in linked list> > newNode->seuraava = mp->arr[bucketIndex];> > mp->arr[bucketIndex] = uusiSolmu;> > }> > return> ;> }> void> delete> (> struct> hashMap* mp,> char> * key)> {> > // Getting bucket index for the> > // given key> > int> bucketIndex = hashFunction(mp, key);> > struct> node* prevNode = NULL;> > // Points to the head of> > // linked list present at> > // bucket index> > struct> node* currNode = mp->arr[bucketIndex];> > while> (currNode != NULL) {> > // Key is matched at delete this> > // node from linked list> > if> (> strcmp> (key, currNode->avain) == 0) {> > // Head node> > // deletion> > if> (currNode == mp->arr[bucketIndex]) {> > mp->arr[bucketIndex] = currNode->next;> > }> > // Last node or middle node> > else> {> > prevNode->next = currNode->next;> > }> > free> (currNode);> > break> ;> > }> > prevNode = currNode;> > currNode = currNode->seuraava;> > }> > return> ;> }> char> * search(> struct> hashMap* mp,> char> * key)> {> > // Getting the bucket index> > // for the given key> > int> bucketIndex = hashFunction(mp, key);> > // Head of the linked list> > // present at bucket index> > struct> node* bucketHead = mp->arr[bucketIndex];> > while> (bucketHead != NULL) {> > // Key is found in the hashMap> > if> (bucketHead->avain == avain) {> > return> bucketHead->arvo;> > }> > bucketHead = bucketHead->seuraava;> > }> > // If no key found in the hashMap> > // equal to the given key> > char> * errorMssg = (> char> *)> malloc> (> sizeof> (> char> ) * 25);> > errorMssg => 'Oops! No data found.
'> ;> > return> errorMssg;> }> // Drivers code> int> main()> {> > // Initialize the value of mp> > struct> hashMap* mp> > = (> struct> hashMap*)> malloc> (> sizeof> (> struct> hashMap));> > initializeHashMap(mp);> > insert(mp,> 'Yogaholic'> ,> 'Anjali'> );> > insert(mp,> 'pluto14'> ,> 'Vartika'> );> > insert(mp,> 'elite_Programmer'> ,> 'Manish'> );> > insert(mp,> 'GFG'> ,> 'techcodeview.com'> );> > insert(mp,> 'decentBoy'> ,> 'Mayank'> );> > printf> (> '%s
'> , search(mp,> 'elite_Programmer'> ));> > printf> (> '%s
'> , search(mp,> 'Yogaholic'> ));> > printf> (> '%s
'> , search(mp,> 'pluto14'> ));> > printf> (> '%s
'> , search(mp,> 'decentBoy'> ));> > printf> (> '%s
'> , search(mp,> 'GFG'> ));> > // Key is not inserted> > printf> (> '%s
'> , search(mp,> 'randomKey'> ));> > printf> (> '
After deletion :
'> );> > // Deletion of key> > delete> (mp,> 'decentBoy'> );> > printf> (> '%s
'> , search(mp,> 'decentBoy'> ));> > return> 0;> }> |
C++
#include> #include> // Linked List node> struct> node {> > // key is string> > char> * key;> > // value is also string> > char> * value;> > struct> node* next;> };> // like constructor> void> setNode(> struct> node* node,> char> * key,> char> * value) {> > node->avain = avain;> > node->arvo = arvo;> > node->seuraava = NULL;> > return> ;> }> struct> hashMap {> > // Current number of elements in hashMap> > // and capacity of hashMap> > int> numOfElements, capacity;> > // hold base address array of linked list> > struct> node** arr;> };> // like constructor> void> initializeHashMap(> struct> hashMap* mp) {> > // Default capacity in this case> > mp->kapasiteetti = 100;> > mp->numOfElements = 0;> > // array of size = 1> > mp->arr = (> struct> node**)> malloc> (> sizeof> (> struct> node*) * mp->kapasiteetti);> > return> ;> }> int> hashFunction(> struct> hashMap* mp,> char> * key) {> > int> bucketIndex;> > int> sum = 0, factor = 31;> > for> (> int> i = 0; i <> strlen> (key); i++) {> > // sum = sum + (ascii value of> > // char * (primeNumber ^ x))...> > // where x = 1, 2, 3....n> > sum = ((sum % mp->kapasiteetti) + (((> int> )key[i]) * factor) % mp->kapasiteetti) % mp->kapasiteetti;> > // factor = factor * prime> > // number....(prime> > // number) ^ x> > factor = ((factor % __INT16_MAX__) * (31 % __INT16_MAX__)) % __INT16_MAX__;> > }> > bucketIndex = sum;> > return> bucketIndex;> }> void> insert(> struct> hashMap* mp,> char> * key,> char> * value) {> > // Getting bucket index for the given> > // key - value pair> > int> bucketIndex = hashFunction(mp, key);> > struct> node* newNode = (> struct> node*)> malloc> (> > // Creating a new node> > sizeof> (> struct> node));> > // Setting value of node> > setNode(newNode, key, value);> > // Bucket index is empty....no collision> > if> (mp->arr[bucketIndex] == NULL) {> > mp->arr[bucketIndex] = uusiSolmu;> > }> > // Collision> > else> {> > // Adding newNode at the head of> > // linked list which is present> > // at bucket index....insertion at> > // head in linked list> > newNode->seuraava = mp->arr[bucketIndex];> > mp->arr[bucketIndex] = uusiSolmu;> > }> > return> ;> }> void> deleteKey(> struct> hashMap* mp,> char> * key) {> > // Getting bucket index for the> > // given key> > int> bucketIndex = hashFunction(mp, key);> > struct> node* prevNode = NULL;> > // Points to the head of> > // linked list present at> > // bucket index> > struct> node* currNode = mp->arr[bucketIndex];> > while> (currNode != NULL) {> > // Key is matched at delete this> > // node from linked list> > if> (> strcmp> (key, currNode->avain) == 0) {> > // Head node> > // deletion> > if> (currNode == mp->arr[bucketIndex]) {> > mp->arr[bucketIndex] = currNode->next;> > }> > // Last node or middle node> > else> {> > prevNode->next = currNode->next;> }> free> (currNode);> break> ;> }> prevNode = currNode;> > currNode = currNode->seuraava;> > }> return> ;> }> char> * search(> struct> hashMap* mp,> char> * key) {> // Getting the bucket index for the given key> int> bucketIndex = hashFunction(mp, key);> // Head of the linked list present at bucket index> struct> node* bucketHead = mp->arr[bucketIndex];> while> (bucketHead != NULL) {> > > // Key is found in the hashMap> > if> (> strcmp> (bucketHead->avain, avain) == 0) {> > return> bucketHead->arvo;> > }> > > bucketHead = bucketHead->seuraava;> }> // If no key found in the hashMap equal to the given key> char> * errorMssg = (> char> *)> malloc> (> sizeof> (> char> ) * 25);> strcpy> (errorMssg,> 'Oops! No data found.
'> );> return> errorMssg;> }> // Drivers code> int> main()> {> // Initialize the value of mp> struct> hashMap* mp = (> struct> hashMap*)> malloc> (> sizeof> (> struct> hashMap));> initializeHashMap(mp);> insert(mp,> 'Yogaholic'> ,> 'Anjali'> );> insert(mp,> 'pluto14'> ,> 'Vartika'> );> insert(mp,> 'elite_Programmer'> ,> 'Manish'> );> insert(mp,> 'GFG'> ,> 'techcodeview.com'> );> insert(mp,> 'decentBoy'> ,> 'Mayank'> );> printf> (> '%s
'> , search(mp,> 'elite_Programmer'> ));> printf> (> '%s
'> , search(mp,> 'Yogaholic'> ));> printf> (> '%s
'> , search(mp,> 'pluto14'> ));> printf> (> '%s
'> , search(mp,> 'decentBoy'> ));> printf> (> '%s
'> , search(mp,> 'GFG'> ));> // Key is not inserted> printf> (> '%s
'> , search(mp,> 'randomKey'> ));> printf> (> '
After deletion :
'> );> // Deletion of key> deleteKey(mp,> 'decentBoy'> );> // Searching the deleted key> printf> (> '%s
'> , search(mp,> 'decentBoy'> ));> return> 0;> }> |
Lähtö
Manish Anjali Vartika Mayank techcodeview.com Oops! No data found. After deletion : Oops! No data found.
Selitys:
- lisäys: Lisää avain-arvo-parin linkitetyn luettelon alkuun, joka on annetussa ryhmäindeksissä. hashFunction: Antaa ämpäriindeksin annetulle avaimelle. Meidän hash-funktio = merkin * alkuluku ASCII-arvo x . Alkuluku meidän tapauksessamme on 31 ja x:n arvo kasvaa 1:stä n:ään avaimen peräkkäisille merkeille. poisto: Poistaa avainarvo-parin annetun avaimen hash-taulukosta. Se poistaa linkitetystä luettelosta solmun, joka sisältää avain-arvo-parin. Haku: Etsi annetun avaimen arvo.
- Tämä toteutus ei käytä uudelleentarkistuskonseptia. Se on kiinteän kokoinen joukko linkitettyjä luetteloita.
- Avain ja arvo ovat molemmat merkkijonoja annetussa esimerkissä.
Ajan ja tilan monimutkaisuus:
Hajautustaulukon lisäys- ja poistotoimintojen aikamonimutkaisuus on keskimäärin O(1). Jokin matemaattinen laskelma todistaa sen.
- Lisäyksen aika monimutkaisuus: Keskimääräisessä tapauksessa se on vakio. Pahimmassa tapauksessa se on lineaarinen. Haun aika monimutkaisuus: Keskimääräisessä tapauksessa se on vakio. Pahimmassa tapauksessa se on lineaarinen. Poistamisen aika monimutkaisuus: Keskimääräisissä tapauksissa se on vakio. Pahimmassa tapauksessa se on lineaarinen. Avaruuden monimutkaisuus: O(n), koska siinä on n lukumäärää elementtejä.
Aiheeseen liittyvät artikkelit:
- Erillinen ketjutuksen törmäyskäsittelytekniikka hajautustekniikassa.



![Top 10: Pelatuimmat verkkopelit maailmassa [Vuonna 2024]](https://techcodeview.com/img/health-lifestyle/63/top-10-most-played-online-games-world.webp)