Hanki ainutlaatuiset arvot Pandas DataFramen sarakkeesta

Unique()-funktio poistaa kaikki sarakkeen päällekkäiset arvot ja palauttaa yhden arvon useille samoille arvoille. Tässä artikkelissa keskustelemme siitä, kuinka voimme saada ainutlaatuisia arvoja sarakkeesta Pandas DataFrame .
Pandas-tietokehyksen luominen päällekkäisillä elementeillä
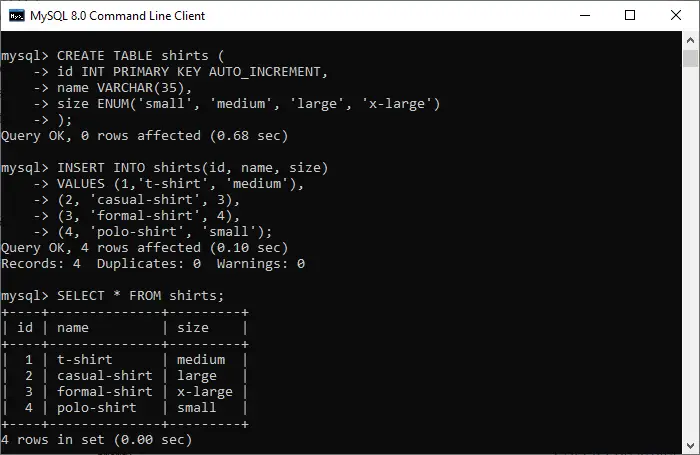
Luo esimerkki Pandas-tietokehyksestä luetteloiden sanakirjalla, vaikka sarakkeiden nimet ovat A, B, C, D ja E päällekkäisten elementtien kanssa.
Python 3
# Import pandas package> import> pandas as pd> # create a dictionary with five fields each> data> => {> > 'A'> : [> 'A1'> ,> 'A2'> ,> 'A3'> ,> 'A4'> ,> 'A5'> ],> > 'B'> : [> 'B1'> ,> 'B2'> ,> 'B3'> ,> 'B4'> ,> 'B4'> ],> > 'C'> : [> 'C1'> ,> 'C2'> ,> 'C3'> ,> 'C3'> ,> 'C3'> ],> > 'D'> : [> 'D1'> ,> 'D2'> ,> 'D2'> ,> 'D2'> ,> 'D2'> ],> > 'E'> : [> 'E1'> ,> 'E1'> ,> 'E1'> ,> 'E1'> ,> 'E1'> ]}> # Convert the dictionary into DataFrame> df> => pd.DataFrame(data)> |

Hanki ainutlaatuiset arvot Pandas DataFramen sarakkeesta
Alla on esimerkkejä, joiden avulla voimme saada tämän tietokehyksen sarakkeen ainutlaatuiset arvot.
- Hanki B-sarakkeen ainutlaatuiset arvot
- Hanki E-sarakkeen ainutlaatuiset arvot
- Hanki yksittäisten arvojen määrä sarakkeessa
- Käytä set():tä poistamaan päällekkäiset arvot sarakkeesta
- Pandas.concat()- ja Unique()-menetelmien käyttö
- Series.drop_duplicates()
Hanki B-sarakkeen ainutlaatuiset arvot
Tässä esimerkissä haemme ja tulostamme yksilölliset arvot B-sarakkeesta käyttämällä unique()> menetelmä. Tuloksena saadut ainutlaatuiset arvot ovat ['B1', 'B2', 'B3', 'B4']> .
Python 3
# Import pandas package> import> pandas as pd> # Convert the dictionary into DataFrame> df> => pd.DataFrame(data)> # Get the unique values of 'B' column> df.B.unique()> |
Lähtö
array(['B1', 'B2', 'B3', 'B4'], dtype=object)
Hanki pandan ainutlaatuiset arvot E-sarakkeesta
Tässä esimerkissä luomme pandas DataFrame -kehyksen sanakirjasta ja noutamme sitten ainutlaatuiset arvot E-sarakkeesta käyttämällä unique()> menetelmä. Tuloksena saadut ainutlaatuiset arvot ovat ['E1']> .
Python 3
# Import pandas package> import> pandas as pd> # Convert the dictionary into DataFrame> df> => pd.DataFrame(data)> # Get the unique values of 'E' column> df.E.unique()> |
Lähtö
array(['E1'], dtype=object)
Hanki yksittäisten arvojen määrä sarakkeessa
Tässä esimerkissä luomme pandas DataFrame -kehyksen sanakirjasta ja sitten laskemme ja tulostamme yksilöllisten arvojen lukumäärän C-sarakkeessa NaN-arvoja lukuun ottamatta. Tulos on 3, mikä tarkoittaa, että sarakkeessa C on kolme ainutlaatuista arvoa.
Python 3
# Import pandas package> import> pandas as pd> # Convert the dictionary into DataFrame> df> => pd.DataFrame(data)> # Get number of unique values in column 'C'> df.C.nunique(dropna> => True> )> |
Lähtö
3
Poista päällekkäiset arvot sarakkeesta käyttämällä set()
Tässä esimerkissä luomme pandas DataFrame -kehyksen sanakirjasta ja käyttää sitten set()> toiminto poimimaan ainutlaatuiset arvot sarakkeesta 'C' ja poistamaan kaksoiskappaleet. Tuloksena oleva sarja, {'C1', 'C2', 'C3'}> , edustaa sarakkeen C yksilöllisiä arvoja.
Python 3
# Import pandas package> import> pandas as pd> # Convert the dictionary into DataFrame> df> => pd.DataFrame(data)> # Use set() to eliminate duplicate values in column 'C'> unique_values_set> => set> (df[> 'C'> ])> # Print the unique values> print> (unique_values_set)> |
Lähtö
{'C1', 'C2', 'C3'} Pandas.concat()- ja Unique()-menetelmien käyttö
Tässä esimerkissä luomme pandas DataFrame -kehyksen sanakirjasta ja yhdistämme sitten yksilölliset arvot kaikista sarakkeista käyttämällä pd.concat()> . Tuloksena oleva NumPy-taulukko näyttää tulostettuna kaikki yksilölliset arvot sarakkeista A–E.
Python 3
# Import pandas package> import> pandas as pd> # Convert the dictionary into DataFrame> df> => pd.DataFrame(data)> # Use pd.concat() to concatenate all columns and then apply unique()> unique_values_all_columns> => pd.concat([df[col].unique()> for> col> in> df.columns])> # Print the unique values> print> (unique_values_all_columns)> |
Lähtö
['A1' 'A2' 'A3' 'A4' 'A5' 'B1' 'B2' 'B3' 'B4' 'C1' 'C2' 'C3' 'D1' 'D2' 'E1']
Series.drop_duplicates()
Tässä esimerkissä luomme pandas DataFrame -kehyksen sanakirjasta ja poistamme kaksoiskappaleet sarakkeista 'A' ja 'D' käyttämällä drop_duplicates()> menetelmä . Tuloksena oleva DataFrame näyttää tulostettuna yksilölliset arvot sarakkeissa 'A' ja 'D' sekä NaN-arvot, joissa kaksoiskappaleet poistettiin D:stä.
Python 3
# Import pandas package> import> pandas as pd> # Convert the dictionary into DataFrame> df> => pd.DataFrame(data)> # Use drop_duplicates() to remove duplicates from columns 'A' and 'D'> df[> 'A'> ]> => df[> 'A'> ].drop_duplicates()> df[> 'D'> ]> => df[> 'D'> ].drop_duplicates()> # Print the DataFrame after removing duplicates from columns 'A' and 'D'> print> (df)> |
Lähtö
A B C D E 0 A1 B1 C1 D1 E1 1 A2 B2 C2 D2 E1 2 A3 B3 C3 NaN E1 3 A4 B4 C3 NaN E1 4 A5 B4 C3 NaN E1