Einfacher Multithread-Download-Manager in Python
A Download-Manager ist im Grunde ein Computerprogramm, das sich der Aufgabe widmet, eigenständige Dateien aus dem Internet herunterzuladen. Hier erstellen wir mithilfe von Threads in Python einen einfachen Download-Manager. Mithilfe von Multithreading kann eine Datei in Form von Blöcken gleichzeitig von verschiedenen Threads heruntergeladen werden. Um dies zu implementieren, erstellen wir ein einfaches Befehlszeilentool, das die URL der Datei akzeptiert und sie dann herunterlädt.
Voraussetzungen: Windows-Rechner mit installiertem Python.
Aufstellen
Laden Sie die unten genannten Pakete von der Eingabeaufforderung herunter.
1. Click-Paket: Click ist ein Python-Paket zum Erstellen schöner Befehlszeilenschnittstellen mit so wenig Code wie nötig. Es handelt sich um das Command Line Interface Creation Kit.
pip install klicken
2. Anforderungspaket: In diesem Tool laden wir eine Datei basierend auf der URL (HTTP-Adressen) herunter. Requests ist eine in Python geschriebene HTTP-Bibliothek, mit der Sie HTTP-Anfragen senden können. Sie können Header aus mehrteiligen Datendateien und Parametern mit einfachen Python-Wörterbüchern hinzufügen und auf die gleiche Weise auf die Antwortdaten zugreifen.
pip-Installationsanfragen
3. Threading-Paket: Um mit Threads arbeiten zu können, benötigen wir ein Threading-Paket.
Pip-Install-Threading
Durchführung
Notiz:
Um das Verständnis zu erleichtern, wurde das Programm in Teile aufgeteilt. Stellen Sie sicher, dass Ihnen beim Ausführen des Programms kein Teil des Codes entgeht.
Schritt 1: Erforderliche Pakete importieren
Diese Pakete stellen die notwendigen Tools bereit, damit Webanfragen Befehlszeileneingaben verarbeiten und Threads erstellen können.
Python import click import requests import threading
Schritt 2: Erstellen Sie die Handler-Funktion
Jeder Thread führt diese Funktion aus, um seinen spezifischen Teil der Datei herunterzuladen. Diese Funktion ist dafür verantwortlich, nur einen bestimmten Bytebereich anzufordern und diese an die richtige Position in der Datei zu schreiben.
Python def Handler ( start end url filename ): headers = { 'Range' : f 'bytes= { start } - { end } ' } r = requests . get ( url headers = headers stream = True ) with open ( filename 'r+b' ) as fp : fp . seek ( start ) fp . write ( r . content )
Schritt 3: Definieren Sie die Hauptfunktion mit Klick
Verwandelt die Funktion in ein Befehlszeilendienstprogramm. Dies definiert, wie Benutzer über die Befehlszeile mit dem Skript interagieren.
Python #Note: This code will not work on online IDE @click . command ( help = 'Downloads the specified file with given name using multi-threading' ) @click . option ( '--number_of_threads' default = 4 help = 'Number of threads to use' ) @click . option ( '--name' type = click . Path () help = 'Name to save the file as (with extension)' ) @click . argument ( 'url_of_file' type = str ) def download_file ( url_of_file name number_of_threads ):
Schritt 4: Dateinamen festlegen und Dateigröße bestimmen
Wir benötigen die Dateigröße, um den Download auf Threads aufzuteilen und sicherzustellen, dass der Server zeitlich begrenzte Downloads unterstützt.
Python r = requests . head ( url_of_file ) file_name = name if name else url_of_file . split ( '/' )[ - 1 ] try : file_size = int ( r . headers [ 'Content-Length' ]) except : print ( 'Invalid URL or missing Content-Length header.' ) return
Schritt 5: Dateispeicher vorab zuweisen
Durch die Vorabzuweisung wird sichergestellt, dass die Datei die richtige Größe hat, bevor wir Blöcke in bestimmte Bytebereiche schreiben.
Python part = file_size // number_of_threads with open ( file_name 'wb' ) as fp : fp . write ( b ' � ' * file_size )
Schritt 6: Threads erstellen
Threads werden bestimmte Bytebereiche zum parallelen Herunterladen zugewiesen.
Python threads = [] for i in range ( number_of_threads ): start = part * i end = file_size - 1 if i == number_of_threads - 1 else ( start + part - 1 ) t = threading . Thread ( target = Handler kwargs = { 'start' : start 'end' : end 'url' : url_of_file 'filename' : file_name }) threads . append ( t ) t . start ()
Schritt 7: Threads beitreten
Stellt sicher, dass alle Threads abgeschlossen sind, bevor das Programm beendet wird.
Python for t in threads : t . join () print ( f ' { file_name } downloaded successfully!' ) if __name__ == '__main__' : download_file ()
Code:
Python import click import requests import threading def Handler ( start end url filename ): headers = { 'Range' : f 'bytes= { start } - { end } ' } r = requests . get ( url headers = headers stream = True ) with open ( filename 'r+b' ) as fp : fp . seek ( start ) fp . write ( r . content ) @click . command ( help = 'Downloads the specified file with given name using multi-threading' ) @click . option ( '--number_of_threads' default = 4 help = 'Number of threads to use' ) @click . option ( '--name' type = click . Path () help = 'Name to save the file as (with extension)' ) @click . argument ( 'url_of_file' type = str ) def download_file ( url_of_file name number_of_threads ): r = requests . head ( url_of_file ) if name : file_name = name else : file_name = url_of_file . split ( '/' )[ - 1 ] try : file_size = int ( r . headers [ 'Content-Length' ]) except : print ( 'Invalid URL or missing Content-Length header.' ) return part = file_size // number_of_threads with open ( file_name 'wb' ) as fp : fp . write ( b ' � ' * file_size ) threads = [] for i in range ( number_of_threads ): start = part * i # Make sure the last part downloads till the end of file end = file_size - 1 if i == number_of_threads - 1 else ( start + part - 1 ) t = threading . Thread ( target = Handler kwargs = { 'start' : start 'end' : end 'url' : url_of_file 'filename' : file_name }) threads . append ( t ) t . start () for t in threads : t . join () print ( f ' { file_name } downloaded successfully!' ) if __name__ == '__main__' : download_file ()
Wir sind mit dem Codierungsteil fertig und befolgen nun die unten gezeigten Befehle, um die .py-Datei auszuführen.
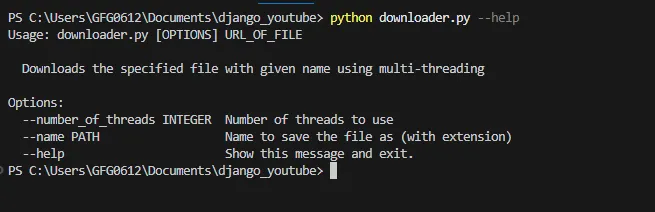
python filename.py –-helpAusgabe:
Python-Dateiname.py –-help
Dieser Befehl zeigt die Verwendung des Click-Command-Tools und die Optionen an, die das Tool akzeptieren kann. Unten ist der Beispielbefehl, mit dem wir versuchen, eine JPG-Bilddatei von einer URL herunterzuladen und außerdem einen Namen und eine Anzahl_der_Threads anzugeben.
Beispielbefehl zum Herunterladen eines JPG
Nachdem alles erfolgreich ausgeführt wurde, können Sie Ihre Datei (in diesem Fall „flower.webp“) in Ihrem Ordnerverzeichnis sehen, wie unten gezeigt:
Verzeichnis
Endlich sind wir damit erfolgreich fertig und dies ist eine der Möglichkeiten, einen einfachen Multithread-Download-Manager in Python zu erstellen.
 Python-Dateiname.py –-help
Python-Dateiname.py –-help  Beispielbefehl zum Herunterladen eines JPG
Beispielbefehl zum Herunterladen eines JPG  Verzeichnis
Verzeichnis