Herunterladen von Dateien aus dem Internet mit Python
Anfragen ist eine vielseitige HTTP-Bibliothek in Python mit verschiedenen Anwendungen. Eine seiner Anwendungen besteht darin, eine Datei mithilfe der Datei-URL aus dem Internet herunterzuladen. Installation: First of all you would need to download the requests library. You can directly install it using pip by typing following command: Da nicht alle Dateidaten in einer einzigen Zeichenfolge gespeichert werden können, verwenden wir r.iter_content Methode zum Laden von Daten in Blöcken unter Angabe der Blockgröße.
pip install requestsOr download it directly from Hier und manuell installieren.
Dateien herunterladen
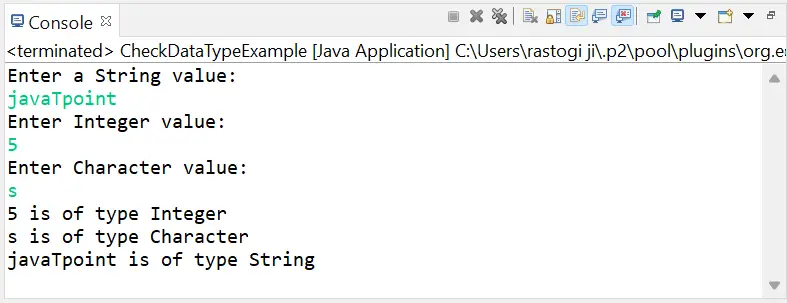
Python3 # imported the requests library import requests image_url = 'https://www.python.org/static/community_logos/python-logo-master-v3-TM.webp' # URL of the image to be downloaded is defined as image_url r = requests . get ( image_url ) # create HTTP response object # send a HTTP request to the server and save # the HTTP response in a response object called r with open ( 'python_logo.webp' 'wb' ) as f : # Saving received content as a png file in # binary format # write the contents of the response (r.content) # to a new file in binary mode. f . write ( r . content )
This small piece of code written above will download the following image from the web. Now check your local directory(the folder where this script resides) and you will find this image: All we need is the URL of the image source. (You can get the URL of image source by right-clicking on the image and selecting the View Image option.) Laden Sie große Dateien herunter
Der Inhalt der HTTP-Antwort ( r.content ) ist nichts anderes als eine Zeichenfolge, die die Dateidaten speichert. Daher ist es bei großen Dateien nicht möglich, alle Daten in einer einzigen Zeichenfolge zu speichern. Um dieses Problem zu lösen, nehmen wir einige Änderungen an unserem Programm vor:r = requests.get(URL stream = True)Setting Strom Parameter zu WAHR führt nur zum Herunterladen der Antwortheader und die Verbindung bleibt offen. Dadurch wird vermieden, dass der Inhalt bei großen Antworten auf einmal in den Speicher eingelesen wird. Jedes Mal wird ein fester Block geladen r.iter_content is iterated. Here is an example: Python3
import requests file_url = 'http://codex.cs.yale.edu/avi/db-book/db4/slide-dir/ch1-2.pdf' r = requests . get ( file_url stream = True ) with open ( 'python.pdf' 'wb' ) as pdf : for chunk in r . iter_content ( chunk_size = 1024 ): # writing one chunk at a time to pdf file if chunk : pdf . write ( chunk )
Videos herunterladen
In diesem Beispiel sind wir daran interessiert, alle hierzu verfügbaren Videovorträge herunterzuladen Webseite . Alle Archive dieser Vorlesung sind verfügbar Hier . So we first scrape the webpage to extract all video links and then download the videos one by one. Python3 import requests from bs4 import BeautifulSoup ''' URL of the archive web-page which provides link to all video lectures. It would have been tiring to download each video manually. In this example we first crawl the webpage to extract all the links and then download videos. ''' # specify the URL of the archive here archive_url = 'https://public.websites.umich.edu/errors/404.html def get_video_links (): # create response object r = requests . get ( archive_url ) # create beautiful-soup object soup = BeautifulSoup ( r . content 'html5lib' ) # find all links on web-page links = soup . findAll ( 'a' ) # filter the link sending with .mp4 video_links = [ archive_url + link [ 'href' ] for link in links if link [ 'href' ] . endswith ( 'mp4' )] return video_links def download_video_series ( video_links ): for link in video_links : '''iterate through all links in video_links and download them one by one''' # obtain filename by splitting url and getting # last string file_name = link . split ( '/' )[ - 1 ] print ( 'Downloading file: %s ' % file_name ) # create response object r = requests . get ( link stream = True ) # download started with open ( file_name 'wb' ) as f : for chunk in r . iter_content ( chunk_size = 1024 * 1024 ): if chunk : f . write ( chunk ) print ( ' %s downloaded! n ' % file_name ) print ( 'All videos downloaded!' ) return if __name__ == '__main__' : # getting all video links video_links = get_video_links () # download all videos download_video_series ( video_links )
Advantages of using Requests library to download web files are: - Man kann die Webverzeichnisse einfach herunterladen, indem man rekursiv durch die Website iteriert!
- Dies ist eine browserunabhängige Methode und viel schneller!
- Man kann einfach eine Webseite durchsuchen, um alle Datei-URLs auf einer Webseite zu erhalten und somit alle Dateien mit einem einzigen Befehl herunterladen.
Implementierung von Web Scraping in Python mit BeautifulSoup