Python datastrukturer

Datastrukturer er en måde at organisere data på, så de kan tilgås mere effektivt afhængigt af situationen. Datastrukturer er grundlæggende for ethvert programmeringssprog, som et program er bygget op omkring. Python hjælper med at lære det grundlæggende i disse datastrukturer på en enklere måde sammenlignet med andre programmeringssprog.

I denne artikel vil vi diskutere datastrukturerne i Python-programmeringssproget, og hvordan de er relateret til nogle specifikke indbyggede datastrukturer som listetupler, ordbøger osv. samt nogle avancerede datastrukturer som træer, grafer osv.
Lister
Python-lister er ligesom arrays, deklareret på andre sprog, som er en ordnet samling af data. Det er meget fleksibelt, da emnerne på en liste ikke behøver at være af samme type.
Implementeringen af Python List ligner Vectors i C++ eller ArrayList i JAVA. Den dyre operation er at indsætte eller slette elementet fra begyndelsen af listen, da alle elementer skal flyttes. Indsættelse og sletning i slutningen af listen kan også blive dyrt i det tilfælde, hvor den forhåndstildelte hukommelse bliver fuld.
Vi kan oprette en liste i python som vist nedenfor.
Eksempel: Oprettelse af Python-liste
Python3
List> => [> 1> ,> 2> ,> 3> ,> 'GFG'> ,> 2.3> ]> print> (> List> )> |
Produktion
[1, 2, 3, 'GFG', 2.3]
Listeelementer kan tilgås af det tildelte indeks. I python-startindekset på listen er sekvensen 0, og slutindekset er (hvis N elementer er der) N-1.
Eksempel: Python List Operations
Python3
# Creating a List with> # the use of multiple values> List> => [> 'Geeks'> ,> 'For'> ,> 'Geeks'> ]> print> (> '
List containing multiple values: '> )> print> (> List> )> # Creating a Multi-Dimensional List> # (By Nesting a list inside a List)> List2> => [[> 'Geeks'> ,> 'For'> ], [> 'Geeks'> ]]> print> (> '
Multi-Dimensional List: '> )> print> (List2)> # accessing a element from the> # list using index number> print> (> 'Accessing element from the list'> )> print> (> List> [> 0> ])> print> (> List> [> 2> ])> # accessing a element using> # negative indexing> print> (> 'Accessing element using negative indexing'> )> > # print the last element of list> print> (> List> [> -> 1> ])> > # print the third last element of list> print> (> List> [> -> 3> ])> |
Produktion
List containing multiple values: ['Geeks', 'For', 'Geeks'] Multi-Dimensional List: [['Geeks', 'For'], ['Geeks']] Accessing element from the list Geeks Geeks Accessing element using negative indexing Geeks Geeks
Ordbog
Python ordbog er som hashtabeller på ethvert andet sprog med tidskompleksiteten O(1). Det er en uordnet samling af dataværdier, der bruges til at gemme dataværdier som et kort, som i modsætning til andre datatyper, der kun har en enkelt værdi som et element, har ordbog nøgle:værdi-parret. Nøgleværdi er angivet i ordbogen for at gøre den mere optimeret.
Indeksering af Python Dictionary sker ved hjælp af nøgler. Disse er af enhver hashbar type, dvs. et objekt, hvis objekt aldrig kan ændre sig som strenge, tal, tupler osv. Vi kan oprette en ordbog ved at bruge krøllede klammeparenteser ({}) eller ordbogsforståelse .
Eksempel: Python Dictionary Operations
Python3
# Creating a Dictionary> Dict> => {> 'Name'> :> 'Geeks'> ,> 1> : [> 1> ,> 2> ,> 3> ,> 4> ]}> print> (> 'Creating Dictionary: '> )> print> (> Dict> )> # accessing a element using key> print> (> 'Accessing a element using key:'> )> print> (> Dict> [> 'Name'> ])> # accessing a element using get()> # method> print> (> 'Accessing a element using get:'> )> print> (> Dict> .get(> 1> ))> # creation using Dictionary comprehension> myDict> => {x: x> *> *> 2> for> x> in> [> 1> ,> 2> ,> 3> ,> 4> ,> 5> ]}> print> (myDict)> |
Produktion
Creating Dictionary: {'Name': 'Geeks', 1: [1, 2, 3, 4]} Accessing a element using key: Geeks Accessing a element using get: [1, 2, 3, 4] {1: 1, 2: 4, 3: 9, 4: 16, 5: 25} Tuple
Python Tuple er en samling af Python-objekter meget ligesom en liste, men Tuples er uforanderlige i naturen, dvs. elementerne i Tuples kan ikke tilføjes eller fjernes, når de først er oprettet. Ligesom en liste kan en Tuple også indeholde elementer af forskellige typer.
I Python oprettes tuples ved at placere en sekvens af værdier adskilt af 'komma' med eller uden brug af parenteser til gruppering af datasekvensen.
Bemærk: Tuples kan også laves med et enkelt element, men det er lidt tricky. Det er ikke tilstrækkeligt at have ét element i parentesen, der skal være et efterfølgende 'komma' for at gøre det til en tupel.
Eksempel: Python Tuple Operations
Python3
# Creating a Tuple with> # the use of Strings> Tuple> => (> 'Geeks'> ,> 'For'> )> print> (> '
Tuple with the use of String: '> )> print> (> Tuple> )> > # Creating a Tuple with> # the use of list> list1> => [> 1> ,> 2> ,> 4> ,> 5> ,> 6> ]> print> (> '
Tuple using List: '> )> Tuple> => tuple> (list1)> # Accessing element using indexing> print> (> 'First element of tuple'> )> print> (> Tuple> [> 0> ])> # Accessing element from last> # negative indexing> print> (> '
Last element of tuple'> )> print> (> Tuple> [> -> 1> ])> > print> (> '
Third last element of tuple'> )> print> (> Tuple> [> -> 3> ])> |
Produktion
Tuple with the use of String: ('Geeks', 'For') Tuple using List: First element of tuple 1 Last element of tuple 6 Third last element of tuple 4 Sæt
Python sæt er en uordnet samling af data, der kan ændres og ikke tillader noget duplikatelement. Sæt bruges grundlæggende til at inkludere medlemskabstest og eliminering af duplikerede poster. Datastrukturen brugt i dette er Hashing, en populær teknik til at udføre indsættelse, sletning og gennemgang i O(1) i gennemsnit.
Hvis flere værdier er til stede på den samme indeksposition, føjes værdien til denne indeksposition for at danne en sammenkædet liste. I implementeres CPython-sæt ved hjælp af en ordbog med dummy-variabler, hvor nøglevæsener medlemmerne sætter med større optimeringer til tidskompleksiteten.
Sæt implementering:

Sæt med talrige operationer på en enkelt HashTable:

Eksempel: Python Set Operations
Python3
# Creating a Set with> # a mixed type of values> # (Having numbers and strings)> Set> => set> ([> 1> ,> 2> ,> 'Geeks'> ,> 4> ,> 'For'> ,> 6> ,> 'Geeks'> ])> print> (> '
Set with the use of Mixed Values'> )> print> (> Set> )> # Accessing element using> # for loop> print> (> '
Elements of set: '> )> for> i> in> Set> :> > print> (i, end> => ' '> )> print> ()> # Checking the element> # using in keyword> print> (> 'Geeks'> in> Set> )> |
Produktion
Set with the use of Mixed Values {1, 2, 'Geeks', 4, 6, 'For'} Elements of set: 1 2 Geeks 4 6 For True Frosne sæt
Frosne sæt i Python er uforanderlige objekter, der kun understøtter metoder og operatører, der producerer et resultat uden at påvirke det eller de frosne sæt, som de anvendes på. Mens elementer i et sæt kan ændres til enhver tid, forbliver elementer i det frosne sæt de samme efter oprettelsen.
Hvis ingen parametre sendes, returnerer den et tomt fastfrosset sæt.
Python3
# Same as {'a', 'b','c'}> normal_set> => set> ([> 'a'> ,> 'b'> ,> 'c'> ])> print> (> 'Normal Set'> )> print> (normal_set)> # A frozen set> frozen_set> => frozenset> ([> 'e'> ,> 'f'> ,> 'g'> ])> print> (> '
Frozen Set'> )> print> (frozen_set)> # Uncommenting below line would cause error as> # we are trying to add element to a frozen set> # frozen_set.add('h')> |
Produktion
Normal Set {'a', 'c', 'b'} Frozen Set frozenset({'g', 'e', 'f'}) Snor
Python-strenge er arrays af bytes, der repræsenterer Unicode-tegn. I enklere termer er en streng en uforanderlig række af tegn. Python har ikke en karakterdatatype, et enkelt tegn er blot en streng med en længde på 1.
Bemærk: Da strenge er uforanderlige, vil ændring af en streng resultere i oprettelse af en ny kopi.
Eksempel: Python Strings Operations
Python3
String> => 'Welcome to GeeksForGeeks'> print> (> 'Creating String: '> )> print> (String)> > # Printing First character> print> (> '
First character of String is: '> )> print> (String[> 0> ])> > # Printing Last character> print> (> '
Last character of String is: '> )> print> (String[> -> 1> ])> |
Produktion
Creating String: Welcome to GeeksForGeeks First character of String is: W Last character of String is: s
Bytearray
Python Bytearray giver en foranderlig sekvens af heltal i området 0 <= x < 256.
Eksempel: Python Bytearray Operations
Python3
# Creating bytearray> a> => bytearray((> 12> ,> 8> ,> 25> ,> 2> ))> print> (> 'Creating Bytearray:'> )> print> (a)> # accessing elements> print> (> '
Accessing Elements:'> , a[> 1> ])> # modifying elements> a[> 1> ]> => 3> print> (> '
After Modifying:'> )> print> (a)> # Appending elements> a.append(> 30> )> print> (> '
After Adding Elements:'> )> print> (a)> |
Produktion
Creating Bytearray: bytearray(b'x0cx08x19x02') Accessing Elements: 8 After Modifying: bytearray(b'x0cx03x19x02') After Adding Elements: bytearray(b'x0cx03x19x02x1e')
Indtil nu har vi studeret alle de datastrukturer, der er indbygget i kerne Python. Lad nu dykke dybere ned i Python og se samlingsmodulet, der giver nogle containere, der er nyttige i mange tilfælde og giver flere funktioner end de ovenfor definerede funktioner.
Indsamlingsmodul
Python-indsamlingsmodulet blev introduceret for at forbedre funktionaliteten af de indbyggede datatyper. Det giver forskellige beholdere, lad os se hver enkelt af dem i detaljer.
Tællere
En tæller er en underklasse af ordbogen. Det bruges til at holde antallet af elementer i en iterabel i form af en uordnet ordbog, hvor nøglen repræsenterer elementet i den iterable, og værdien repræsenterer antallet af det element i den iterable. Dette svarer til en taske eller et multisæt af andre sprog.
Eksempel: Python-tælleroperationer
Python3
from> collections> import> Counter> > # With sequence of items> print> (Counter([> 'B'> ,> 'B'> ,> 'A'> ,> 'B'> ,> 'C'> ,> 'A'> ,> 'B'> ,> 'B'> ,> 'A'> ,> 'C'> ]))> > # with dictionary> count> => Counter({> 'A'> :> 3> ,> 'B'> :> 5> ,> 'C'> :> 2> })> print> (count)> count.update([> 'A'> ,> 1> ])> print> (count)> |
Produktion
Counter({'B': 5, 'A': 3, 'C': 2}) Counter({'B': 5, 'A': 3, 'C': 2}) Counter({'B': 5, 'A': 4, 'C': 2, 1: 1}) BestiltDict
An BestiltDict er også en underklasse af ordbog, men i modsætning til en ordbog husker den den rækkefølge, som tasterne blev indsat.
Eksempel: Python OrderedDict Operations
Python3
from> collections> import> OrderedDict> print> (> 'Before deleting:
'> )> od> => OrderedDict()> od[> 'a'> ]> => 1> od[> 'b'> ]> => 2> od[> 'c'> ]> => 3> od[> 'd'> ]> => 4> for> key, value> in> od.items():> > print> (key, value)> print> (> '
After deleting:
'> )> od.pop(> 'c'> )> for> key, value> in> od.items():> > print> (key, value)> print> (> '
After re-inserting:
'> )> od[> 'c'> ]> => 3> for> key, value> in> od.items():> > print> (key, value)> |
Produktion
Before deleting: a 1 b 2 c 3 d 4 After deleting: a 1 b 2 d 4 After re-inserting: a 1 b 2 d 4 c 3
DefaultDict
DefaultDict bruges til at angive nogle standardværdier for nøglen, der ikke eksisterer og aldrig rejser en KeyError. Dens objekter kan initialiseres ved hjælp af metoden DefaultDict() ved at sende datatypen som et argument.
Bemærk: default_factory er en funktion, der giver standardværdien for den oprettede ordbog. Hvis denne parameter er fraværende, hæves KeyError.
Eksempel: Python DefaultDict Operations
Python3
from> collections> import> defaultdict> > # Defining the dict> d> => defaultdict(> int> )> > L> => [> 1> ,> 2> ,> 3> ,> 4> ,> 2> ,> 4> ,> 1> ,> 2> ]> > # Iterate through the list> # for keeping the count> for> i> in> L:> > > # The default value is 0> > # so there is no need to> > # enter the key first> > d[i]> +> => 1> > print> (d)> |
Produktion
defaultdict(, {1: 2, 2: 3, 3: 1, 4: 2}) Kædekort
Et ChainMap indkapsler mange ordbøger i en enkelt enhed og returnerer en liste over ordbøger. Når der skal findes en nøgle, søges der i alle ordbøgerne én efter én, indtil nøglen er fundet.
Eksempel: Python ChainMap Operations
Python3
from> collections> import> ChainMap> > > d1> => {> 'a'> :> 1> ,> 'b'> :> 2> }> d2> => {> 'c'> :> 3> ,> 'd'> :> 4> }> d3> => {> 'e'> :> 5> ,> 'f'> :> 6> }> > # Defining the chainmap> c> => ChainMap(d1, d2, d3)> print> (c)> print> (c[> 'a'> ])> print> (c[> 'g'> ])> |
Produktion
ChainMap({'a': 1, 'b': 2}, {'c': 3, 'd': 4}, {'e': 5, 'f': 6}) 1 KeyError: 'g'
Opkaldt Tuple
EN Opkaldt Tuple returnerer et tupelobjekt med navne for hver position, som de almindelige tupler mangler. Overvej f.eks. en tupelnavn elev, hvor det første element repræsenterer fname, andet repræsenterer lname og det tredje element repræsenterer DOB. Antag at for at kalde fname i stedet for at huske indekspositionen, kan du faktisk kalde elementet ved at bruge fname-argumentet, så vil det være rigtig nemt at få adgang til tuples-elementet. Denne funktionalitet leveres af NamedTuple.
Eksempel: Python NamedTuple Operations
Python3
from> collections> import> namedtuple> > # Declaring namedtuple()> Student> => namedtuple(> 'Student'> ,[> 'name'> ,> 'age'> ,> 'DOB'> ])> > # Adding values> S> => Student(> 'Nandini'> ,> '19'> ,> '2541997'> )> > # Access using index> print> (> 'The Student age using index is : '> ,end> => '')> print> (S[> 1> ])> > # Access using name> print> (> 'The Student name using keyname is : '> ,end> => '')> print> (S.name)> |
Produktion
The Student age using index is : 19 The Student name using keyname is : Nandini
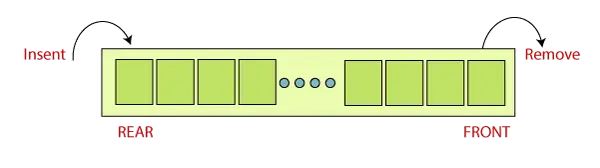
Om hvad
Deque (Double Ended Queue) er den optimerede liste til hurtigere tilføjelse og pop handlinger fra begge sider af beholderen. Det giver O(1)-tidskompleksitet for tilføjelses- og pop-operationer sammenlignet med listen med O(n)-tidskompleksitet.
Python Deque er implementeret ved hjælp af dobbeltlinkede lister, derfor er ydeevnen for tilfældig adgang til elementerne O(n).
Eksempel: Python Deque Operations
Python3
# importing 'collections' for deque operations> import> collections> # initializing deque> de> => collections.deque([> 1> ,> 2> ,> 3> ])> # using append() to insert element at right end> # inserts 4 at the end of deque> de.append(> 4> )> # printing modified deque> print> (> 'The deque after appending at right is : '> )> print> (de)> # using appendleft() to insert element at left end> # inserts 6 at the beginning of deque> de.appendleft(> 6> )> # printing modified deque> print> (> 'The deque after appending at left is : '> )> print> (de)> # using pop() to delete element from right end> # deletes 4 from the right end of deque> de.pop()> # printing modified deque> print> (> 'The deque after deleting from right is : '> )> print> (de)> # using popleft() to delete element from left end> # deletes 6 from the left end of deque> de.popleft()> # printing modified deque> print> (> 'The deque after deleting from left is : '> )> print> (de)> |
Produktion
The deque after appending at right is : deque([1, 2, 3, 4]) The deque after appending at left is : deque([6, 1, 2, 3, 4]) The deque after deleting from right is : deque([6, 1, 2, 3]) The deque after deleting from left is : deque([1, 2, 3])
UserDict
UserDict er en ordbogslignende beholder, der fungerer som en indpakning omkring ordbogsobjekterne. Denne beholder bruges, når nogen ønsker at oprette deres egen ordbog med en ændret eller ny funktionalitet.
Eksempel: Python UserDict
Python3
from> collections> import> UserDict> # Creating a Dictionary where> # deletion is not allowed> class> MyDict(UserDict):> > > # Function to stop deletion> > # from dictionary> > def> __del__(> self> ):> > raise> RuntimeError(> 'Deletion not allowed'> )> > > # Function to stop pop from> > # dictionary> > def> pop(> self> , s> => None> ):> > raise> RuntimeError(> 'Deletion not allowed'> )> > > # Function to stop popitem> > # from Dictionary> > def> popitem(> self> , s> => None> ):> > raise> RuntimeError(> 'Deletion not allowed'> )> > # Driver's code> d> => MyDict({> 'a'> :> 1> ,> > 'b'> :> 2> ,> > 'c'> :> 3> })> print> (> 'Original Dictionary'> )> print> (d)> d.pop(> 1> )> |
Produktion
Original Dictionary {'a': 1, 'b': 2, 'c': 3} RuntimeError: Deletion not allowed
Brugerliste
UserList er en listelignende beholder, der fungerer som en indpakning omkring listeobjekterne. Dette er nyttigt, når nogen ønsker at oprette deres egen liste med en eller anden ændret eller yderligere funktionalitet.
Eksempler: Python UserList
Python3
# Python program to demonstrate> # userlist> from> collections> import> UserList> # Creating a List where> # deletion is not allowed> class> MyList(UserList):> > > # Function to stop deletion> > # from List> > def> remove(> self> , s> => None> ):> > raise> RuntimeError(> 'Deletion not allowed'> )> > > # Function to stop pop from> > # List> > def> pop(> self> , s> => None> ):> > raise> RuntimeError(> 'Deletion not allowed'> )> > # Driver's code> L> => MyList([> 1> ,> 2> ,> 3> ,> 4> ])> print> (> 'Original List'> )> print> (L)> # Inserting to List'> L.append(> 5> )> print> (> 'After Insertion'> )> print> (L)> # Deleting From List> L.remove()> |
Produktion
Original List [1, 2, 3, 4] After Insertion [1, 2, 3, 4, 5]
RuntimeError: Deletion not allowed
Brugerstreng
UserString er en strenglignende beholder, og ligesom UserDict og UserList fungerer den som en indpakning omkring strengobjekter. Det bruges, når nogen ønsker at oprette deres egne strenge med en eller anden modificeret eller yderligere funktionalitet.
Eksempel: Python UserString
Python3
from> collections> import> UserString> # Creating a Mutable String> class> Mystring(UserString):> > > # Function to append to> > # string> > def> append(> self> , s):> > self> .data> +> => s> > > # Function to remove from> > # string> > def> remove(> self> , s):> > self> .data> => self> .data.replace(s, '')> > # Driver's code> s1> => Mystring(> 'Geeks'> )> print> (> 'Original String:'> , s1.data)> # Appending to string> s1.append(> 's'> )> print> (> 'String After Appending:'> , s1.data)> # Removing from string> s1.remove(> 'e'> )> print> (> 'String after Removing:'> , s1.data)> |
Produktion
Original String: Geeks String After Appending: Geekss String after Removing: Gkss
Efter at have studeret alle datastrukturerne, lad os nu se nogle avancerede datastrukturer såsom stak, kø, graf, linket liste osv., der kan bruges i Python Language.
Linket liste
En sammenkædet liste er en lineær datastruktur, hvor elementerne ikke er gemt på sammenhængende hukommelsesplaceringer. Elementerne i en linket liste er linket ved hjælp af pointere som vist på billedet nedenfor:

En sammenkædet liste er repræsenteret af en pegepind til den første knude på den sammenkædede liste. Den første knude kaldes hovedet. Hvis den linkede liste er tom, så er værdien af hovedet NULL. Hver node i en liste består af mindst to dele:
- Data
- Pointer (eller reference) til næste knude
Eksempel: Definition af linket liste i Python
Python3
# Node class> class> Node:> > # Function to initialize the node object> > def> __init__(> self> , data):> > self> .data> => data> # Assign data> > self> .> next> => None> # Initialize> > # next as null> # Linked List class> class> LinkedList:> > > # Function to initialize the Linked> > # List object> > def> __init__(> self> ):> > self> .head> => None> |
Lad os oprette en simpel linket liste med 3 noder.
Python3
# A simple Python program to introduce a linked list> # Node class> class> Node:> > # Function to initialise the node object> > def> __init__(> self> , data):> > self> .data> => data> # Assign data> > self> .> next> => None> # Initialize next as null> # Linked List class contains a Node object> class> LinkedList:> > # Function to initialize head> > def> __init__(> self> ):> > self> .head> => None> # Code execution starts here> if> __name__> => => '__main__'> :> > # Start with the empty list> > list> => LinkedList()> > list> .head> => Node(> 1> )> > second> => Node(> 2> )> > third> => Node(> 3> )> > '''> > Three nodes have been created.> > We have references to these three blocks as head,> > second and third> > list.head second third> > | | |> > | | |> > +----+------+ +----+------+ +----+------+> > | 1 | None | | 2 | None | | 3 | None |> > +----+------+ +----+------+ +----+------+> > '''> > list> .head.> next> => second;> # Link first node with second> > '''> > Now next of first Node refers to second. So they> > both are linked.> > list.head second third> > | | |> > | | |> > +----+------+ +----+------+ +----+------+> > | 1 | o-------->| 2 | null | | 3 | null |> > +----+------+ +----+------+ +----+------+> > '''> > second.> next> => third;> # Link second node with the third node> > '''> > Now next of second Node refers to third. So all three> > nodes are linked.> > list.head second third> > | | |> > | | |> > +----+------+ +----+------+ +----+------+> > | 1 | o-------->| 2 | o-------->| 3 | null |> > +----+------+ +----+------+ +----+------+> > '''> |
Linket listegennemgang
I det forrige program har vi lavet en simpel sammenkædet liste med tre noder. Lad os krydse den oprettede liste og udskrive dataene for hver node. For gennemgang, lad os skrive en generel funktion printList(), der udskriver en given liste.
Python3
# A simple Python program for traversal of a linked list> # Node class> class> Node:> > # Function to initialise the node object> > def> __init__(> self> , data):> > self> .data> => data> # Assign data> > self> .> next> => None> # Initialize next as null> # Linked List class contains a Node object> class> LinkedList:> > # Function to initialize head> > def> __init__(> self> ):> > self> .head> => None> > # This function prints contents of linked list> > # starting from head> > def> printList(> self> ):> > temp> => self> .head> > while> (temp):> > print> (temp.data)> > temp> => temp.> next> # Code execution starts here> if> __name__> => => '__main__'> :> > # Start with the empty list> > list> => LinkedList()> > list> .head> => Node(> 1> )> > second> => Node(> 2> )> > third> => Node(> 3> )> > list> .head.> next> => second;> # Link first node with second> > second.> next> => third;> # Link second node with the third node> > list> .printList()> |
Produktion
1 2 3
Stak
EN stak er en lineær datastruktur, der gemmer elementer på en Last-In/First-Out (LIFO) eller First-In/Last-Out (FILO) måde. I stakken tilføjes et nyt element i den ene ende, og et element fjernes kun fra den ende. Indsæt- og sletningsoperationerne kaldes ofte push og pop.

Funktionerne forbundet med stack er:
- empty() – Returnerer om stakken er tom – Tidskompleksitet: O(1) size() – Returnerer stakkens størrelse – Tidskompleksitet: O(1) top() – Returnerer en reference til det øverste element i stakken – Tidskompleksitet: O(1) push(a) – Indsætter elementet 'a' i toppen af stakken – Tidskompleksitet: O(1) pop() – Sletter det øverste element i stakken – Tidskompleksitet: O( 1)
Python Stack Implementering
Stack i Python kan implementeres på følgende måder:
- liste
- Collections.deque
- kø.LifoKø
Implementering ved hjælp af List
Pythons indbyggede datastrukturliste kan bruges som en stak. I stedet for push(), bruges append() til at tilføje elementer til toppen af stakken, mens pop() fjerner elementet i LIFO-rækkefølge.
Python3
stack> => []> # append() function to push> # element in the stack> stack.append(> 'g'> )> stack.append(> 'f'> )> stack.append(> 'g'> )> print> (> 'Initial stack'> )> print> (stack)> # pop() function to pop> # element from stack in> # LIFO order> print> (> '
Elements popped from stack:'> )> print> (stack.pop())> print> (stack.pop())> print> (stack.pop())> print> (> '
Stack after elements are popped:'> )> print> (stack)> # uncommenting print(stack.pop())> # will cause an IndexError> # as the stack is now empty> |
Produktion
Initial stack ['g', 'f', 'g'] Elements popped from stack: g f g Stack after elements are popped: []
Implementering ved hjælp af collections.deque:
Python stack kan implementeres ved hjælp af deque-klassen fra samlingsmodulet. Deque foretrækkes frem for listen i de tilfælde, hvor vi har brug for hurtigere tilføjelses- og pop-operationer fra begge ender af containeren, da deque giver en O(1)-tidskompleksitet for tilføjelses- og pop-handlinger sammenlignet med liste, der giver O(n) tidskompleksitet.
Python3
from> collections> import> deque> stack> => deque()> # append() function to push> # element in the stack> stack.append(> 'g'> )> stack.append(> 'f'> )> stack.append(> 'g'> )> print> (> 'Initial stack:'> )> print> (stack)> # pop() function to pop> # element from stack in> # LIFO order> print> (> '
Elements popped from stack:'> )> print> (stack.pop())> print> (stack.pop())> print> (stack.pop())> print> (> '
Stack after elements are popped:'> )> print> (stack)> # uncommenting print(stack.pop())> # will cause an IndexError> # as the stack is now empty> |
Produktion
Initial stack: deque(['g', 'f', 'g']) Elements popped from stack: g f g Stack after elements are popped: deque([])
Implementering vha. kømodul
Kømodulet har også en LIFO Queue, som grundlæggende er en Stack. Data indsættes i køen ved hjælp af put()-funktionen og get() tager data ud fra køen.
Python3
from> queue> import> LifoQueue> # Initializing a stack> stack> => LifoQueue(maxsize> => 3> )> # qsize() show the number of elements> # in the stack> print> (stack.qsize())> # put() function to push> # element in the stack> stack.put(> 'g'> )> stack.put(> 'f'> )> stack.put(> 'g'> )> print> (> 'Full: '> , stack.full())> print> (> 'Size: '> , stack.qsize())> # get() function to pop> # element from stack in> # LIFO order> print> (> '
Elements popped from the stack'> )> print> (stack.get())> print> (stack.get())> print> (stack.get())> print> (> '
Empty: '> , stack.empty())> |
Produktion
0 Full: True Size: 3 Elements popped from the stack g f g Empty: True
Kø
Som en stak kø er en lineær datastruktur, der gemmer elementer på en First In First Out (FIFO) måde. Med en kø fjernes det mindst nyligt tilføjede element først. Et godt eksempel på køen er enhver kø af forbrugere til en ressource, hvor den forbruger, der kom først, bliver serveret først.

Operationer forbundet med kø er:
- Enqueue: Tilføjer et element til køen. Hvis køen er fuld, siges det at være en overløbstilstand – Tidskompleksitet: O(1) Dequeue: Fjerner en vare fra køen. Elementerne poppes i samme rækkefølge, som de skubbes. Hvis køen er tom, så siges det at være en underløbstilstand – Tidskompleksitet: O(1) Foran: Hent det forreste element fra køen – Tidskompleksitet: O(1) Bageste: Hent det sidste element fra køen – Tidskompleksitet : O(1)
Implementering af Python-kø
Kø i Python kan implementeres på følgende måder:
- liste
- samlinger.deque
- hale.hale
Implementering ved hjælp af liste
I stedet for enqueue() og dequeue(), bruges append() og pop()-funktionen.
Python3
# Initializing a queue> queue> => []> # Adding elements to the queue> queue.append(> 'g'> )> queue.append(> 'f'> )> queue.append(> 'g'> )> print> (> 'Initial queue'> )> print> (queue)> # Removing elements from the queue> print> (> '
Elements dequeued from queue'> )> print> (queue.pop(> 0> ))> print> (queue.pop(> 0> ))> print> (queue.pop(> 0> ))> print> (> '
Queue after removing elements'> )> print> (queue)> # Uncommenting print(queue.pop(0))> # will raise and IndexError> # as the queue is now empty> |
Produktion
Initial queue ['g', 'f', 'g'] Elements dequeued from queue g f g Queue after removing elements []
Implementering ved hjælp af collections.deque
Deque foretrækkes frem for listen i de tilfælde, hvor vi har brug for hurtigere tilføjelses- og pop-operationer fra begge ender af containeren, da deque giver en O(1)-tidskompleksitet for tilføjelses- og pop-handlinger sammenlignet med liste, der giver O(n) tidskompleksitet.
Python3
from> collections> import> deque> # Initializing a queue> q> => deque()> # Adding elements to a queue> q.append(> 'g'> )> q.append(> 'f'> )> q.append(> 'g'> )> print> (> 'Initial queue'> )> print> (q)> # Removing elements from a queue> print> (> '
Elements dequeued from the queue'> )> print> (q.popleft())> print> (q.popleft())> print> (q.popleft())> print> (> '
Queue after removing elements'> )> print> (q)> # Uncommenting q.popleft()> # will raise an IndexError> # as queue is now empty> |
Produktion
Initial queue deque(['g', 'f', 'g']) Elements dequeued from the queue g f g Queue after removing elements deque([])
Implementering ved hjælp af køen.Kø
queue.Queue(maxsize) initialiserer en variabel til en maksimal størrelse på maxsize. En maxstørrelse på nul '0' betyder en uendelig kø. Denne kø følger FIFO-reglen.
Python3
from> queue> import> Queue> # Initializing a queue> q> => Queue(maxsize> => 3> )> # qsize() give the maxsize> # of the Queue> print> (q.qsize())> # Adding of element to queue> q.put(> 'g'> )> q.put(> 'f'> )> q.put(> 'g'> )> # Return Boolean for Full> # Queue> print> (> '
Full: '> , q.full())> # Removing element from queue> print> (> '
Elements dequeued from the queue'> )> print> (q.get())> print> (q.get())> print> (q.get())> # Return Boolean for Empty> # Queue> print> (> '
Empty: '> , q.empty())> q.put(> 1> )> print> (> '
Empty: '> , q.empty())> print> (> 'Full: '> , q.full())> # This would result into Infinite> # Loop as the Queue is empty.> # print(q.get())> |
Produktion
0 Full: True Elements dequeued from the queue g f g Empty: True Empty: False Full: False
Prioritetskø
Prioriterede køer er abstrakte datastrukturer, hvor hver data/værdi i køen har en vis prioritet. For eksempel hos flyselskaber ankommer bagage med titlen Business eller First-class tidligere end resten. Priority Queue er en udvidelse af køen med følgende egenskaber.
- Et element med høj prioritet sættes ud af kø før et element med lav prioritet.
- Hvis to elementer har samme prioritet, serveres de i henhold til deres rækkefølge i køen.
Python3
# A simple implementation of Priority Queue> # using Queue.> class> PriorityQueue(> object> ):> > def> __init__(> self> ):> > self> .queue> => []> > def> __str__(> self> ):> > return> ' '> .join([> str> (i)> for> i> in> self> .queue])> > # for checking if the queue is empty> > def> isEmpty(> self> ):> > return> len> (> self> .queue)> => => 0> > # for inserting an element in the queue> > def> insert(> self> , data):> > self> .queue.append(data)> > # for popping an element based on Priority> > def> delete(> self> ):> > try> :> > max> => 0> > for> i> in> range> (> len> (> self> .queue)):> > if> self> .queue[i]>> self> .queue[> max> ]:> > max> => i> > item> => self> .queue[> max> ]> > del> self> .queue[> max> ]> > return> item> > except> IndexError:> > print> ()> > exit()> if> __name__> => => '__main__'> :> > myQueue> => PriorityQueue()> > myQueue.insert(> 12> )> > myQueue.insert(> 1> )> > myQueue.insert(> 14> )> > myQueue.insert(> 7> )> > print> (myQueue)> > while> not> myQueue.isEmpty():> > print> (myQueue.delete())> |
Produktion
12 1 14 7 14 12 7 1
Heap-kø (eller heapq)
heapq-modul i Python leverer heap-datastrukturen, der hovedsageligt bruges til at repræsentere en prioritetskø. Egenskaben ved denne datastruktur i Python er, at hver gang det mindste heap-element poppes (min-heap). Når elementer skubbes eller poppes, bibeholdes bunkestrukturen. Heap[0]-elementet returnerer også det mindste element hver gang.
Det understøtter udtrækning og indsættelse af det mindste element i O(log n) gange.
Python3
# importing 'heapq' to implement heap queue> import> heapq> # initializing list> li> => [> 5> ,> 7> ,> 9> ,> 1> ,> 3> ]> # using heapify to convert list into heap> heapq.heapify(li)> # printing created heap> print> (> 'The created heap is : '> ,end> => '')> print> (> list> (li))> # using heappush() to push elements into heap> # pushes 4> heapq.heappush(li,> 4> )> # printing modified heap> print> (> 'The modified heap after push is : '> ,end> => '')> print> (> list> (li))> # using heappop() to pop smallest element> print> (> 'The popped and smallest element is : '> ,end> => '')> print> (heapq.heappop(li))> |
Produktion
The created heap is : [1, 3, 9, 7, 5] The modified heap after push is : [1, 3, 4, 7, 5, 9] The popped and smallest element is : 1
Binært træ
Et træ er en hierarkisk datastruktur, der ser ud som nedenstående figur –
tree ---- j <-- root / f k / a h z <-- leaves
Træets øverste knude kaldes roden, mens de nederste knudepunkter eller knuderne uden børn kaldes bladknuderne. De noder, der er direkte under en node, kaldes dens børn, og de noder, der er direkte over noget, kaldes dens forælder.
Et binært træ er et træ, hvis elementer kan have næsten to børn. Da hvert element i et binært træ kun kan have 2 børn, kalder vi dem typisk venstre og højre børn. En binær træknude indeholder følgende dele.
- Data
- Viser til venstre barn
- Pointer til det rigtige barn
Eksempel: Definition af nodeklasse
Python3
# A Python class that represents an individual node> # in a Binary Tree> class> Node:> > def> __init__(> self> ,key):> > self> .left> => None> > self> .right> => None> > self> .val> => key> |
Lad os nu oprette et træ med 4 noder i Python. Lad os antage, at træstrukturen ser ud som nedenfor -
tree ---- 1 <-- root / 2 3 / 4
Eksempel: Tilføjelse af data til træet
Python3
# Python program to introduce Binary Tree> # A class that represents an individual node in a> # Binary Tree> class> Node:> > def> __init__(> self> ,key):> > self> .left> => None> > self> .right> => None> > self> .val> => key> # create root> root> => Node(> 1> )> ''' following is the tree after above statement> > 1> > /> > None None'''> root.left> => Node(> 2> );> root.right> => Node(> 3> );> ''' 2 and 3 become left and right children of 1> > 1> > /> > 2 3> > / /> None None None None'''> root.left.left> => Node(> 4> );> '''4 becomes left child of 2> > 1> > /> > 2 3> > / /> 4 None None None> /> None None'''> |
Trægennemgang
Træer kan krydses på forskellige måder. Følgende er de almindeligt anvendte måder at krydse træer på. Lad os overveje nedenstående træ -
tree ---- 1 <-- root / 2 3 / 4 5
Dybde første gennemløb:
- I rækkefølge (venstre, rod, højre): 4 2 5 1 3
- Forudbestil (rod, venstre, højre): 1 2 4 5 3
- Postordre (venstre, højre, rod): 4 5 2 3 1
Algoritme rækkefølge (træ)
- Gå gennem det venstre undertræ, dvs. kald Inorder (venstre-undertræ)
- Besøg roden.
- Gå gennem det højre undertræ, dvs. kald Inorder (højre-undertræ)
Algoritme forudbestilling (træ)
- Besøg roden.
- Gå gennem det venstre undertræ, dvs. kald Preorder (venstre-undertræ)
- Gå gennem det højre undertræ, dvs. kald Preorder (højre-undertræ)
Algoritme Postordre (træ)
- Gå gennem det venstre undertræ, dvs. kald Postorder (venstre-undertræ)
- Gå gennem det højre undertræ, dvs. kald Postorder (højre-undertræ)
- Besøg roden.
Python3
# Python program to for tree traversals> # A class that represents an individual node in a> # Binary Tree> class> Node:> > def> __init__(> self> , key):> > self> .left> => None> > self> .right> => None> > self> .val> => key> # A function to do inorder tree traversal> def> printInorder(root):> > if> root:> > # First recur on left child> > printInorder(root.left)> > # then print the data of node> > print> (root.val),> > # now recur on right child> > printInorder(root.right)> # A function to do postorder tree traversal> def> printPostorder(root):> > if> root:> > # First recur on left child> > printPostorder(root.left)> > # the recur on right child> > printPostorder(root.right)> > # now print the data of node> > print> (root.val),> # A function to do preorder tree traversal> def> printPreorder(root):> > if> root:> > # First print the data of node> > print> (root.val),> > # Then recur on left child> > printPreorder(root.left)> > # Finally recur on right child> > printPreorder(root.right)> # Driver code> root> => Node(> 1> )> root.left> => Node(> 2> )> root.right> => Node(> 3> )> root.left.left> => Node(> 4> )> root.left.right> => Node(> 5> )> print> (> 'Preorder traversal of binary tree is'> )> printPreorder(root)> print> (> '
Inorder traversal of binary tree is'> )> printInorder(root)> print> (> '
Postorder traversal of binary tree is'> )> printPostorder(root)> |
Produktion
Preorder traversal of binary tree is 1 2 4 5 3 Inorder traversal of binary tree is 4 2 5 1 3 Postorder traversal of binary tree is 4 5 2 3 1
Tidskompleksitet – O(n)
Breadth-First eller Level Order Traversal
Niveauordregennemgang af et træ er bredde-første traversering for træet. Niveauordregennemgangen af ovenstående træ er 1 2 3 4 5.
For hver node besøges først noden, og derefter sættes dens underordnede noder i en FIFO-kø. Nedenfor er algoritmen for det samme –
- Opret en tom kø q
- temp_node = root /*start fra root*/
- Loop mens temp_node ikke er NULL
- udskriv temp_node->data.
- Sæt temp_nodes børn i kø (først venstre og derefter højre børn) til q
- Sæt en node i kø fra q
Python3
# Python program to print level> # order traversal using Queue> # A node structure> class> Node:> > > # A utility function to create a new node> > def> __init__(> self> ,key):> > self> .data> => key> > self> .left> => None> > self> .right> => None> # Iterative Method to print the> # height of a binary tree> def> printLevelOrder(root):> > > # Base Case> > if> root> is> None> :> > return> > > # Create an empty queue> > # for level order traversal> > queue> => []> > # Enqueue Root and initialize height> > queue.append(root)> > while> (> len> (queue)>> 0> ):> > > # Print front of queue and> > # remove it from queue> > print> (queue[> 0> ].data)> > node> => queue.pop(> 0> )> > # Enqueue left child> > if> node.left> is> not> None> :> > queue.append(node.left)> > # Enqueue right child> > if> node.right> is> not> None> :> > queue.append(node.right)> # Driver Program to test above function> root> => Node(> 1> )> root.left> => Node(> 2> )> root.right> => Node(> 3> )> root.left.left> => Node(> 4> )> root.left.right> => Node(> 5> )> print> (> 'Level Order Traversal of binary tree is -'> )> printLevelOrder(root)> |
Produktion
Level Order Traversal of binary tree is - 1 2 3 4 5
Tidskompleksitet: O(n)
Kurve
EN kurve er en ikke-lineær datastruktur bestående af noder og kanter. Noderne omtales nogle gange også som hjørner, og kanterne er linjer eller buer, der forbinder to vilkårlige noder i grafen. Mere formelt kan en graf defineres som en graf bestående af et endeligt sæt af knudepunkter (eller noder) og et sæt kanter, der forbinder et par knudepunkter.

I ovenstående graf er sættet af hjørner V = {0,1,2,3,4} og sættet af kanter E = {01, 12, 23, 34, 04, 14, 13}.
De følgende to er de mest brugte repræsentationer af en graf.
- Adjacency Matrix
- Tilgrænsende liste
Adjacency Matrix
Adjacency Matrix er et 2D-array af størrelse V x V, hvor V er antallet af hjørner i en graf. Lad 2D-arrayet være adj[][], et slot adj[i][j] = 1 indikerer, at der er en kant fra toppunkt i til toppunkt j. Adjacency-matrixen for en urettet graf er altid symmetrisk. Adjacency Matrix bruges også til at repræsentere vægtede grafer. Hvis adj[i][j] = w, så er der en kant fra toppunkt i til toppunkt j med vægt w.
Python3
# A simple representation of graph using Adjacency Matrix> class> Graph:> > def> __init__(> self> ,numvertex):> > self> .adjMatrix> => [[> -> 1> ]> *> numvertex> for> x> in> range> (numvertex)]> > self> .numvertex> => numvertex> > self> .vertices> => {}> > self> .verticeslist> => [> 0> ]> *> numvertex> > def> set_vertex(> self> ,vtx,> id> ):> > if> 0> <> => vtx <> => self> .numvertex:> > self> .vertices[> id> ]> => vtx> > self> .verticeslist[vtx]> => id> > def> set_edge(> self> ,frm,to,cost> => 0> ):> > frm> => self> .vertices[frm]> > to> => self> .vertices[to]> > self> .adjMatrix[frm][to]> => cost> > > # for directed graph do not add this> > self> .adjMatrix[to][frm]> => cost> > def> get_vertex(> self> ):> > return> self> .verticeslist> > def> get_edges(> self> ):> > edges> => []> > for> i> in> range> (> self> .numvertex):> > for> j> in> range> (> self> .numvertex):> > if> (> self> .adjMatrix[i][j]!> => -> 1> ):> > edges.append((> self> .verticeslist[i],> self> .verticeslist[j],> self> .adjMatrix[i][j]))> > return> edges> > > def> get_matrix(> self> ):> > return> self> .adjMatrix> G> => Graph(> 6> )> G.set_vertex(> 0> ,> 'a'> )> G.set_vertex(> 1> ,> 'b'> )> G.set_vertex(> 2> ,> 'c'> )> G.set_vertex(> 3> ,> 'd'> )> G.set_vertex(> 4> ,> 'e'> )> G.set_vertex(> 5> ,> 'f'> )> G.set_edge(> 'a'> ,> 'e'> ,> 10> )> G.set_edge(> 'a'> ,> 'c'> ,> 20> )> G.set_edge(> 'c'> ,> 'b'> ,> 30> )> G.set_edge(> 'b'> ,> 'e'> ,> 40> )> G.set_edge(> 'e'> ,> 'd'> ,> 50> )> G.set_edge(> 'f'> ,> 'e'> ,> 60> )> print> (> 'Vertices of Graph'> )> print> (G.get_vertex())> print> (> 'Edges of Graph'> )> print> (G.get_edges())> print> (> 'Adjacency Matrix of Graph'> )> print> (G.get_matrix())> |
Produktion
Grafens hjørner
['a', 'b', 'c', 'd', 'e', 'f']
Kanter af graf
[('a', 'c', 20), ('a', 'e', 10), ('b', 'c', 30), ('b', 'e', 40), ( 'c', 'a', 20), ('c', 'b', 30), ('d', 'e', 50), ('e', 'a', 10), ('e ', 'b', 40), ('e', 'd', 50), ('e', 'f', 60), ('f', 'e', 60)]
Adjacency Matrix of Graph
[[-1, -1, 20, -1, 10, -1], [-1, -1, 30, -1, 40, -1], [20, 30, -1, -1, -1 , -1], [-1, -1, -1, -1, 50, -1], [10, 40, -1, 50, -1, 60], [-1, -1, -1, -1, 60, -1]]
Tilgrænsende liste
Der bruges en række lister. Størrelsen af arrayet er lig med antallet af hjørner. Lad arrayet være et array[]. En indgangsmatrix[i] repræsenterer listen over toppunkter, der støder op til det ith-punkt. Denne repræsentation kan også bruges til at repræsentere en vægtet graf. Vægten af kanter kan repræsenteres som lister over par. Følgende er en gengivelse af nabolisten af ovenstående graf.

Python3
# A class to represent the adjacency list of the node> class> AdjNode:> > def> __init__(> self> , data):> > self> .vertex> => data> > self> .> next> => None> # A class to represent a graph. A graph> # is the list of the adjacency lists.> # Size of the array will be the no. of the> # vertices 'V'> class> Graph:> > def> __init__(> self> , vertices):> > self> .V> => vertices> > self> .graph> => [> None> ]> *> self> .V> > # Function to add an edge in an undirected graph> > def> add_edge(> self> , src, dest):> > > # Adding the node to the source node> > node> => AdjNode(dest)> > node.> next> => self> .graph[src]> > self> .graph[src]> => node> > # Adding the source node to the destination as> > # it is the undirected graph> > node> => AdjNode(src)> > node.> next> => self> .graph[dest]> > self> .graph[dest]> => node> > # Function to print the graph> > def> print_graph(> self> ):> > for> i> in> range> (> self> .V):> > print> (> 'Adjacency list of vertex {}
head'> .> format> (i), end> => '')> > temp> => self> .graph[i]> > while> temp:> > print> (> ' ->{}'> .> format> (temp.vertex), end> => '')> > temp> => temp.> next> > print> (> '
'> )> # Driver program to the above graph class> if> __name__> => => '__main__'> :> > V> => 5> > graph> => Graph(V)> > graph.add_edge(> 0> ,> 1> )> > graph.add_edge(> 0> ,> 4> )> > graph.add_edge(> 1> ,> 2> )> > graph.add_edge(> 1> ,> 3> )> > graph.add_edge(> 1> ,> 4> )> > graph.add_edge(> 2> ,> 3> )> > graph.add_edge(> 3> ,> 4> )> > graph.print_graph()> |
Produktion
Adjacency list of vertex 0 head ->4 -> 1 Adjacency liste over toppunkt 1 hoved -> 4 -> 3 -> 2 -> 0 Adjacency liste over toppunkt 2 hoved -> 3 -> 1 Adjacency liste af toppunkt 3 hoved -> 4 -> 2 -> 1 Adjacency liste over toppunkt 4 hoved -> 3 -> 1 -> 0
Grafgennemgang
Breadth-First Search eller BFS
Bredth-First Traversal for en graf ligner Breadth-First Traversal af et træ. Den eneste fangst her er, i modsætning til træer, kan grafer indeholde cyklusser, så vi kan komme til den samme knude igen. For at undgå at behandle en node mere end én gang, bruger vi et boolesk besøgt array. For nemheds skyld antages det, at alle toppunkter er tilgængelige fra startpunktet.
For eksempel, i den følgende graf, starter vi traversering fra toppunkt 2. Når vi kommer til toppunkt 0, leder vi efter alle tilstødende toppunkter af det. 2 er også et tilstødende toppunkt på 0. Hvis vi ikke markerer besøgte toppunkter, vil 2 blive behandlet igen, og det bliver en ikke-afsluttende proces. En Breadth-First Traversal af følgende graf er 2, 0, 3, 1.

Python3
# Python3 Program to print BFS traversal> # from a given source vertex. BFS(int s)> # traverses vertices reachable from s.> from> collections> import> defaultdict> # This class represents a directed graph> # using adjacency list representation> class> Graph:> > # Constructor> > def> __init__(> self> ):> > # default dictionary to store graph> > self> .graph> => defaultdict(> list> )> > # function to add an edge to graph> > def> addEdge(> self> ,u,v):> > self> .graph[u].append(v)> > # Function to print a BFS of graph> > def> BFS(> self> , s):> > # Mark all the vertices as not visited> > visited> => [> False> ]> *> (> max> (> self> .graph)> +> 1> )> > # Create a queue for BFS> > queue> => []> > # Mark the source node as> > # visited and enqueue it> > queue.append(s)> > visited[s]> => True> > while> queue:> > # Dequeue a vertex from> > # queue and print it> > s> => queue.pop(> 0> )> > print> (s, end> => ' '> )> > # Get all adjacent vertices of the> > # dequeued vertex s. If a adjacent> > # has not been visited, then mark it> > # visited and enqueue it> > for> i> in> self> .graph[s]:> > if> visited[i]> => => False> :> > queue.append(i)> > visited[i]> => True> # Driver code> # Create a graph given in> # the above diagram> g> => Graph()> g.addEdge(> 0> ,> 1> )> g.addEdge(> 0> ,> 2> )> g.addEdge(> 1> ,> 2> )> g.addEdge(> 2> ,> 0> )> g.addEdge(> 2> ,> 3> )> g.addEdge(> 3> ,> 3> )> print> (> 'Following is Breadth First Traversal'> > ' (starting from vertex 2)'> )> g.BFS(> 2> )> # This code is contributed by Neelam Yadav> |
Produktion
Following is Breadth First Traversal (starting from vertex 2) 2 0 3 1
Tidskompleksitet: O(V+E) hvor V er antallet af hjørner i grafen og E er antallet af kanter i grafen.
Depth First Search eller DFS
Dybde første gennemløb for en graf svarer til Depth First Traversal af et træ. Den eneste fangst her er, i modsætning til træer, grafer kan indeholde cyklusser, en node kan besøges to gange. For at undgå at behandle en node mere end én gang skal du bruge en boolsk besøgt matrix.
Algoritme:
- Opret en rekursiv funktion, der tager indekset for noden og et besøgt array.
- Marker den aktuelle node som besøgt, og udskriv noden.
- Gå gennem alle tilstødende og umarkerede noder og kald den rekursive funktion med indekset for den tilstødende node.
Python3
# Python3 program to print DFS traversal> # from a given graph> from> collections> import> defaultdict> # This class represents a directed graph using> # adjacency list representation> class> Graph:> > # Constructor> > def> __init__(> self> ):> > # default dictionary to store graph> > self> .graph> => defaultdict(> list> )> > # function to add an edge to graph> > def> addEdge(> self> , u, v):> > self> .graph[u].append(v)> > # A function used by DFS> > def> DFSUtil(> self> , v, visited):> > # Mark the current node as visited> > # and print it> > visited.add(v)> > print> (v, end> => ' '> )> > # Recur for all the vertices> > # adjacent to this vertex> > for> neighbour> in> self> .graph[v]:> > if> neighbour> not> in> visited:> > self> .DFSUtil(neighbour, visited)> > # The function to do DFS traversal. It uses> > # recursive DFSUtil()> > def> DFS(> self> , v):> > # Create a set to store visited vertices> > visited> => set> ()> > # Call the recursive helper function> > # to print DFS traversal> > self> .DFSUtil(v, visited)> # Driver code> # Create a graph given> # in the above diagram> g> => Graph()> g.addEdge(> 0> ,> 1> )> g.addEdge(> 0> ,> 2> )> g.addEdge(> 1> ,> 2> )> g.addEdge(> 2> ,> 0> )> g.addEdge(> 2> ,> 3> )> g.addEdge(> 3> ,> 3> )> print> (> 'Following is DFS from (starting from vertex 2)'> )> g.DFS(> 2> )> |
Produktion
Following is DFS from (starting from vertex 2) 2 0 1 3
Tidskompleksitet: O(V + E), hvor V er antallet af hjørner og E er antallet af kanter i grafen.