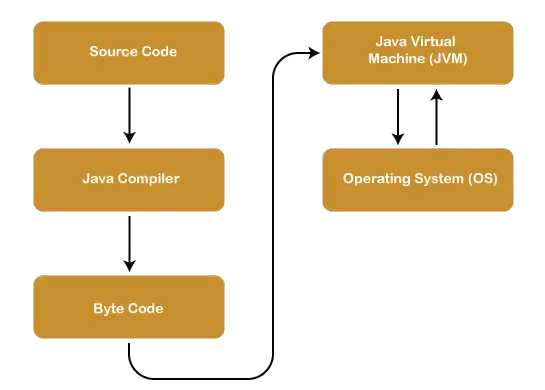
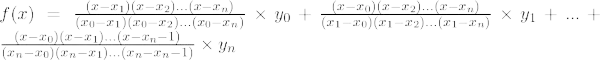Normalfordeling i R
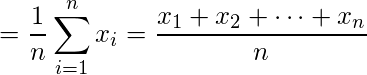
Normal fordeling er en sandsynlighedsfunktion, der bruges i statistik, der fortæller om, hvordan dataværdierne er fordelt. Det er den vigtigste sandsynlighedsfordelingsfunktion, der bruges i statistik på grund af dens fordele i virkelige tilfælde. For eksempel befolkningens højde, skostørrelse, IQ-niveau, terningkast og mange flere. Det observeres generelt, at datafordeling er normal, når der er en tilfældig indsamling af data fra uafhængige kilder. Grafen fremstillet efter plotning af værdien af variablen på x-aksen og optælling af værdien på y-aksen er en klokkeformet kurvegraf. Grafen angiver, at toppunktet er middelværdien af datasættet, og halvdelen af værdierne af datasættet ligger på venstre side af middelværdien og den anden halvdel ligger på højre del af middelværdien og fortæller om fordelingen af værdierne. Grafen er symmetrisk fordeling. I R er der 4 indbyggede funktioner til at generere normalfordeling:  er ond og
er ond og 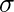 er standardafvigelse. Syntaks:
er standardafvigelse. Syntaks:
Produktion: 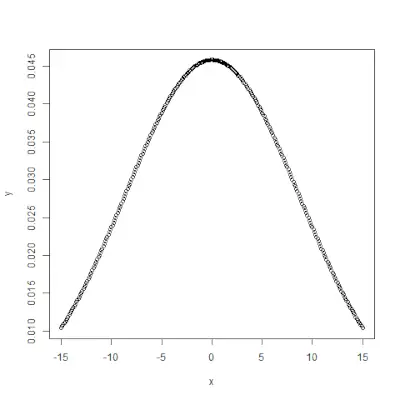
Output: 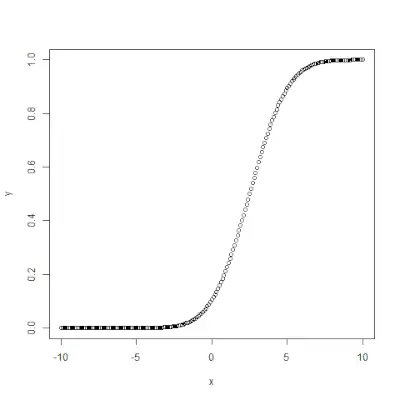
Produktion: 
Output: 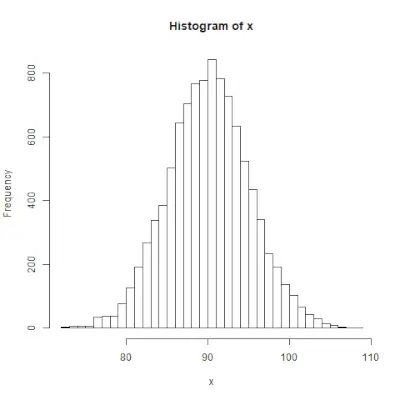
- dnorm()
dnorm(x, mean, sd)pnorm()
pnorm(x, mean, sd)qnorm()
qnorm(p, mean, sd)rnorm()
rnorm(n, mean, sd)hvor,
– x repræsenterer datasættet af værdier – middel(x) repræsenterer gennemsnittet af datasættet x . Dens standardværdi er 0.– sd(x) repræsenterer standardafvigelsen for datasættet x . Dens standardværdi er 1.– n er antallet af observationer. – s er vektor af sandsynligheder
Funktioner til at generere normalfordeling i R
dnorm()
dnorm()> funktion i R programmering måler tæthed funktion af distribution. I statistik måles det med nedenstående formel-hvor,  er ond og
er ond og 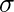 er standardafvigelse. Syntaks:
er standardafvigelse. Syntaks: dnorm(x, mean, sd)Eksempel:
# creating a sequence of values> # between -15 to 15 with a difference of 0.1> x> => seq(> -> 15> ,> 15> , by> => 0.1> )> > y> => dnorm(x, mean(x), sd(x))> > # output to be present as PNG file> png(> file> => 'dnormExample.webp'> )> > # Plot the graph.> plot(x, y)> > # saving the file> dev.off()> |

pnorm()
pnorm()> funktion er den kumulative fordelingsfunktion, som måler sandsynligheden for, at et tilfældigt tal X tager en værdi mindre end eller lig med x, dvs. i statistik er det givet ved- Syntaks: pnorm(x, mean, sd)Eksempel:
# creating a sequence of values> # between -10 to 10 with a difference of 0.1> x <> -> seq(> -> 10> ,> 10> , by> => 0.1> )> > y <> -> pnorm(x, mean> => 2.5> , sd> => 2> )> > # output to be present as PNG file> png(> file> => 'pnormExample.webp'> )> > # Plot the graph.> plot(x, y)> > # saving the file> dev.off()> |

qnorm()
qnorm()> funktion er det omvendte af pnorm()> fungere. Den tager sandsynlighedsværdien og giver output, der svarer til sandsynlighedsværdien. Det er nyttigt til at finde percentilerne for en normalfordeling. Syntaks: qnorm(p, mean, sd)Eksempel:
# Create a sequence of probability values> # incrementing by 0.02.> x <> -> seq(> 0> ,> 1> , by> => 0.02> )> > y <> -> qnorm(x, mean(x), sd(x))> > # output to be present as PNG file> png(> file> => 'qnormExample.webp'> )> > # Plot the graph.> plot(x, y)> > # Save the file.> dev.off()> |

rnorm()
rnorm()> funktion i R-programmering bruges til at generere en vektor af tilfældige tal, som er normalfordelt. Syntaks: rnorm(x, mean, sd)Eksempel:
# Create a vector of 1000 random numbers> # with mean=90 and sd=5> x <> -> rnorm(> 10000> , mean> => 90> , sd> => 5> )> > # output to be present as PNG file> png(> file> => 'rnormExample.webp'> )> > # Create the histogram with 50 bars> hist(x, breaks> => 50> )> > # Save the file.> dev.off()> |